记一次ceph心跳机制异常的案例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次ceph心跳机制异常的案例相关的知识,希望对你有一定的参考价值。
现象:部署使用ceph集群的时候遇到一个情况,在大规模集群的时候,有节点网络或者osd异常时,mon迟迟不把该异常的osd标down,一直等待900s后mon发现该节点的osd一直没有更新pgmap才把异常的osd标down,并更新osdmap扩散出去。但这个900s内,客户端IO还是会一直往异常的osd上去下发,导致io超时,并进一步影响上次的业务。原因分析:
我们在mon的日志里面也看到了和异常osd建立心跳的其他osd向mon报告该osd的异常,但mon确实在短时间内没有这些osd标down。查看了一些相关网络和书籍的资料后,才发现了问题。
首先我们关注osd配置中几个相关的配置项:
(1)osd_heartbeat_min_peers:10
(2)mon_osd_min_down_reporters:2
(3)mon_osd_min_down_reporters_ratio:0.5
以上参数的之都可以在ceph集群节点上执行ceph daemon osd.x config show查看(x是你的集群osd的id)。
问题出现的原因是什么呢?
问题现场的集群部署时每个osd会随机选取10个peer osd来作为建立心跳的对象,但在ceph的机制中,这个10个osd不一定保证能够全部分散在不同的节点上。故在有osd异常的时候,向mon报该osd down的reporter有概率不满足ratio=0.5,即reporter数量未过集群存储host数量的一半,这样异常osd就无法通过osd之间的心跳报活机制快速标down,直到900s后mon发现这个osd pgmap一直不更新才识别到异常(另一种机制,可以看做是给osd心跳保活机制做最后的保险),并通过osdmap扩散出来。而这个900s对于上层业务来说,往往是不可接受的。
但这个现象对于小规模集群几乎不会出现,比如以一个3节点ceph集群为例: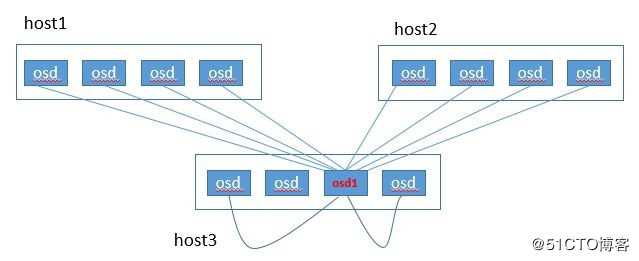
如果与其他节点osd建立的peer数量小于了osd_heartbeat_min_peers,那么osd会继续选择与自己较近的osd建立心跳连接(即使是和自己位于同一个节点上。)
对于osd心跳机制,网上有人总结过几点要求:
(1)及时:建立心跳的osd可以在秒级发现其他osd的异常并上报monitor,monitor在几分钟内把该osd标down下线
(2)适当的压力:不要以为peer越多越好,特别是现在实际应用场景中osd监听和发送心跳报文的网络链路都是和public network以及cluster network共用的,心跳连接建立过多会极大影响系统的性能。Mon有单独与osd维持心跳的方式,但ceph通过osd之间的心跳保活,将这种压力分散到各个osd上,极大减小了中心节点mon的压力。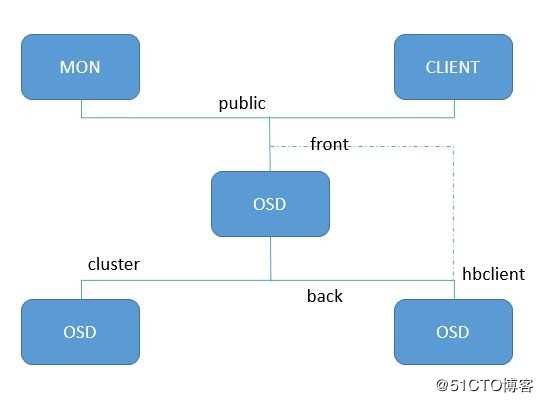
(3)容忍网络抖动:mon收集到osd的汇报之后,会经过周期的等待几个条件,而不是贸然把osd标down。这些条件有目标osd的实效时间大于通过固定量osd_heartbeat_grace和历史网络条件确定的阈值,以及上报的主机数是否达到min_reporters和min_reporters_ratio,以及在一定时间内,失效汇报没有被源报告者取消掉等。
(4)扩散机制:2种实现,mon主动扩散osdmap,还有一种惰性的是osd和client自己来取。为了让异常信息及时让client和其他osd感知到,一般是前一种实现比较好。
总结和启示:
2个方向可以做出改变。
(1)对于原有机制中取集群存储节点数量的0.5作为min_reporter_ratio明显不合理,应该采用的是这个osd与多少host上的osd建立心跳(取host数量),那就由0.5*建立心跳的host总数来作为判断依据。
(2)一些场景下,我们会自己定义一些数据存放的逻辑区域,通过对crush的层级结构的利用,例如在一个ceph集群中定义多个逻辑区域,一个数据的分片或者副本只存在于一个逻辑区域中,那相关osd建立心跳连接的范围就需要相应精简和准确。
现在ceph实现的osd心跳机制还是会有很多问题,不知道后面会不会有新的机制替换当前机制,让我们拭目以待。
以上是关于记一次ceph心跳机制异常的案例的主要内容,如果未能解决你的问题,请参考以下文章