3.redis-六大特性
Posted xixi18
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.redis-六大特性相关的知识,希望对你有一定的参考价值。
一.慢查询
1.慢查询的生命周期
第一阶段:客户端发送命令到redis(客户端超时不一定慢查询,但慢查询的客户端超时的一个可能因素)
第二阶段:因为redis是单线程,在命令执行之前都是要排队的
第三阶段:redis执行命令(慢查询发生在第三阶段)
第四阶段:返回结果给客户端
2.慢查询的两个配置
配置一:slowlog-max-len
(1)先进先出队列:一条命令在第三阶段执行过程中,被列入慢查询的范围内,就会进入一个队列,其实用redis的列表实现的,但它是一个先进先出的队列
(2)固定长度:这个队列是固定长度的,当队列满了之后,最先进的就会被踢出
(3)保存在内存中:当redis重启,会消失
默认值:slowlog-max-len =128
配置二:slowlog-log-slower-than
(1)慢查询阈值(单位:微秒[1毫秒=1000微秒])
(2)slowlog-log-slower-than=0,记录所有命令到慢查询
默认值:slowlog-log-slower-than = 10000
3.慢查询的配置方法:
配置一:修改配置文件重启
配置二:动态配置
config set slowlog-max-len 1000
config set slowlog-log-slower-than 1000
4.慢查询的三个命令
第一个命令:
slowlog get[n]:获取慢查询队列,n是获取慢查询的多少条
第二个命令:
slowlog len:获取慢查询队列长度
第三个命令:
slowlog reset:清空慢查询队列
5.慢查询运维经验
第一条:slowlog-max-len不要设置过大,默认10ms,通常设置1ms根据阈值设定,redis的qps通常是万级别的,通常希望1秒执行一万次,平均的时间是0.1毫秒,设置过大,必须10毫秒才能记录这条命令,超过1毫秒对qps就会有影响
第二条:slowlog-log-slower-than不要设置过小,通常设置1000左右队列存在内存当中,当redis重启之后,列表就会进行清空,而且是先进先出的队列,随着慢查询的数量不断增加,最开始的慢查询就会丢掉,对于分析历史问题不是很方便
第三条:理解命令生命周期
第四条:定期持久化慢查询,针对第二条,因为慢查询存在内存当中,定期将慢查询持久化到例如mysql,这样就可以查到历史慢查询的操作
二.pipeline流水线
1.什么是流水线
正常一条命令:1次时间=1次网络时间+1次命令时间
正常多条命令:n次时间=n次网络时间+n次命令时间
流水线:将一批命令批量打包,在服务端进行批量计算,然后按顺序把结果返回给客户端,大大节省了网络时间
1次pipeline流水线(n条命令)=1次网络时间+n次命令时间
2.客户端实现
3.pipeline与原生操作对比
4.使用建议
第一:注意每次pipeline携带数据量
第二:pipeline每次只能作用在一个redis节点上
三.发布订阅
1.角色
发布者(publisher):发布者发布消息,发布者会将信息发送到对应的频道上
订阅者(subscriber):订阅者一直订阅这个频道,就会收到相应的消息
频道(channel)
2.模型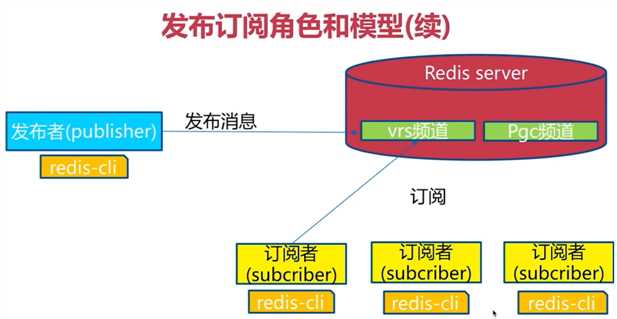
一个发布者已经发布消息到一个频道上了,一个新的订阅者是无法获取到之前的消息,无法做到消息堆积
3.API
命令一:发布publish命令:
语法:publish channel message
实例:向souhu:tv发送xixi返回的结果是订阅者数,如果是0就是没有客户端订阅
127.0.0.1:6379> publish sohu:tv "xixi"
(integer) 0
命令二:订阅subscribe
语法:subscribe[channel] #一个或多个
实例:返回订阅的频道和收到消息的详细的订阅信息,收到消息对应的频道
127.0.0.1:6379> subscribe sohu:tv
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "sohu:tv"
3) (integer) 1
命令三:取消订阅unsubscribe
语法:unsubscribe[channel] #一个或多个
实例:取消定于souhu:tv,返回对应的结果
127.0.0.1:6379> unsubscribe sohu:tv
1) "unsubscribe"
2) "sohu:tv"
3) (integer) 0
4.发布订阅与消息队列
四.Bitmap位图
1.什么是位图
2.位图相关命令
(1)设置整个字符串变成二进制后的第几位的值
语法:setbit(name, offset, value)
对name对应值的二进制表示的位进行操作
127.0.0.1:6379> get Name
"xi"
xi的二进制表示的位:
x i
1111000 1101001
把第二位的1改成0
127.0.0.1:6379> setbit Name 1 0
(integer) 1
127.0.0.1:6379> get Name
"8i"
(2)获取name对应的值的二进制表示中的某位的值(0或1)
语法:getbit(name, offset)
127.0.0.1:6379> get Name
"xi"
xi的二进制表示的位:
x i
1111000 1101001
(3)获取name对应的值的二进制表示中的第8位值是几
127.0.0.1:6379> getbit Name 9
(integer) 1
(4)获取name对应的值的二进制表示中1的个数
语法:bitcount(key, start=None, end=None)
127.0.0.1:6379> get Name
"xi"
xi的二进制表示的位:
x i
1111000 1101001
获取name里1的个数有几个
127.0.0.1:6379> bitcount Name
(integer) 8
3.独立用户统计
使用set和Bitmap
1亿用户,5千万独立
4.使用经验
type=string,最大512MB
注意setbit时的偏移量,可能有较大耗时
位图不上绝对好
五.HyperLogLog
1.新的数据结构
基于HyperLogLog算法:极小空间完成独立数量统计
本质还是字符串
2.三个命令
命令一:pfadd key element[element...]:向hyperloglog添加元素
实例:做独立id统计,向2019_06_25中添加4个uuid
127.0.0.1:6379> pfadd 2019_06_25:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
命了二:pfcount key[key...]:计算hyperloglog的独立总数
实例:独立用户的统计
127.0.0.1:6379> pfcount 2019_06_25:unique:ids
(integer) 4
命令三:pfmerge destkey sourcekey[sourcekey...]:合并多个hyperloglog
实例:
(1)向2019_06_25中添加4个uuid
127.0.0.1:6379> pfadd 2019_06_25:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
(2)向2019_06_26中添加4个uuid
127.0.0.1:6379> pfadd 2019_06_26:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
(integer) 1
(3)合并2019_06_25和2019_06_26为2016_06_25,26
127.0.0.1:6379> pfmerge 2016_06_25,26:unique:ids 2019_06_25:unique:ids 2019_06_26:unique:ids
OK
(4)查看独立用户数
127.0.0.1:6379> pfcount 2016_06_25,26:unique:ids
(integer) 7
3.内存消耗
4.使用经验
是否能容忍错误(错误率:0.81%)
是否需要单条数据
六.GEO(地理信息定位)
1.GEO是什么
存储经纬度,计算两地距离,范围计算等
2.5个城市经纬度
3.相关命令
4.相关说明
以上是关于3.redis-六大特性的主要内容,如果未能解决你的问题,请参考以下文章