R语言对推特数据进行文本情感分析
Posted tecdat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言对推特数据进行文本情感分析相关的知识,希望对你有一定的参考价值。
美国调查公司盖洛普公司(Gallup poll found)民调显示,至少51%美国人不赞同总统特朗普的政策。据外媒报道,特朗普上任8天以来引发51%美国人的不满,42%美国人赞同新总统的政策。该项调查共有1500名成年美国人,误差为3%。

为了验证美国民众的不满情绪,我们以R语言抓取的特朗普推特数据为例,对数据进行文本挖掘,进一步进行情感分析,从而得到很多有趣的信息。
找到推特来源是苹果手机或者安卓手机的样本,清理掉其他来源的样本
tweets <-trump_tweets_df>%select(id, statusSource, text, created) %>%extract(statusSource, "source", "Twitter for (.*?)<")>%filter(source %in%c("iPhone", "android"))对数据进行可视化计算不同时间,对应的推特比例.
并且对比安卓手机和苹果手机上的推特数量的区别

从对比图中我们可以发现,安卓手机和苹果手机发布推特的时间有显著的差别,安卓手机倾向于在5点到10点之间发布推特,而苹果手机一般在10点到20,点左右发布推特.同时我们也可以看到,安卓手机发布推特数量的比例要高于苹果手机
然后查看推特中是否含有引用 ,并且对比不同平台上的数量
ggplot(aes(source, n, fill = quoted)) +geom_bar(stat ="identity", position ="dodge") +labs(x ="", y ="Number of tweets", fill ="") +ggtitle(‘Whether tweets start with a quotation mark (")‘)
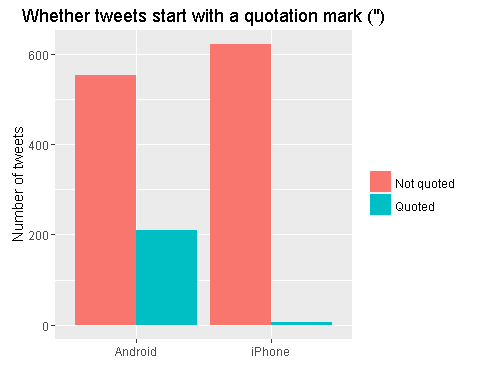
从对比的结果来看,安卓手机,没有引用的比例要明显低于苹果手机。而安卓手机应用的数量要明显大于苹果手机。因此可以认为,苹果手机发的推特内容大多为原创,而安卓手机大多为应用内
然后查看推特中是否有链接或者图片,并且对比不同平台的情况
ggplot(tweet_picture_counts, aes(source, n, fill = picture)) +geom_bar(stat ="identity", position ="dodge") +labs(x ="", y ="Number of tweets", fill ="")
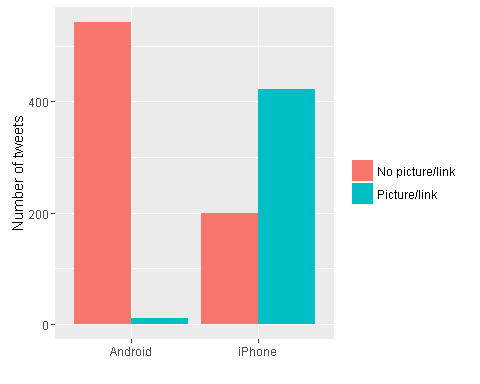
从上面的对比图中,我们可以看到安卓手机没有图片或者链接的情况要多与苹果,也就是说,使用苹果手机的用户在发推特的时候一般会发布照片或者链接
同时可以看到安卓平台的用户把推特一般不使用图片或者链接,而苹果手机的用户恰恰相反
spr <-tweet_picture_counts>%spread(source, n) %>%mutate_each(funs(. /sum(.)), Android, iPhone)rr <-spr$iPhone[2] /spr$Android[2]
然后我们对推特中的异常字符进行检测,并且进行删除
然后找到推特中关键词,并且按照数量进行排序library(tidytext)reg <- "([^A-Za-z\\d#@‘]|‘(?![A-Za-z\\d#@]))"tweet_words <-tweets>%filter(!str_detect(text, ‘^"‘)) %>%mutate(text =str_replace_all(text, "https://t.co/[A-Za-z\\d]+|&", "")) %>%unnest_tokens(word, text, token ="regex", pattern = reg) %>%filter(!word %in%stop_words$word,str_detect(word, "[a-z]"))tweet_words
tweet_words %>%count(word, sort =TRUE) %>%head(20) %>%mutate(word =reorder(word, n)) %>%ggplot(aes(word, n)) +geom_bar(stat ="identity") +ylab("Occurrences") +coord_flip()
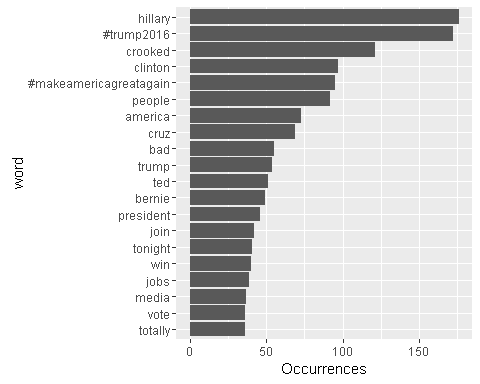
从图中我们可以看到希拉里这个关键词的排名是第一,随后是特朗普2016这个关键词。同时在后面的关键词中,我们还看到了特朗普,以及克林顿等。
对数据进行情感分析,并且计算安卓和苹果手机的相对影响比例
通过特征词情感倾向分别计算不同平台的情感比,并且进行可视化
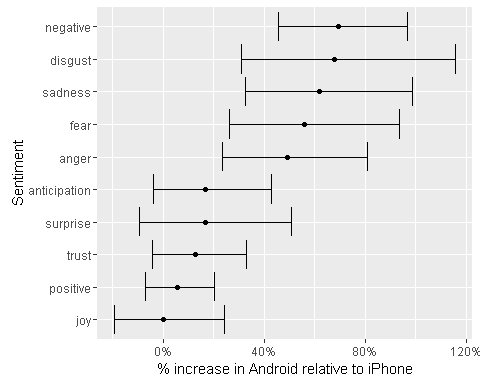
在统计出不同情感倾向的词的数量之后,绘制他们的置信区间。从上面的图中可以看到,相比于苹果手机,安卓手机的负面情绪最多,其次是disgust,然后是悲伤。表示积极的情感倾向很少。
然后我们对每个情感类别中出现的关键词的数量进行统计
android_iphone_ratios %>%inner_join(nrc, by ="word") %>%filter(!sentiment %in%c("positive", "negative")) %>%mutate(sentiment =reorder(sentiment, -logratio),word =reorder(word, -logratio)) %>%
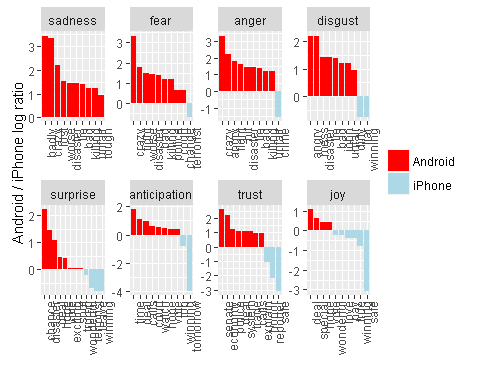
从结果中我们可以看到,负面词大多出现在安卓手机上,而苹果手机上出现的负面词的数量要远远小于安卓平台上的数量
以上是关于R语言对推特数据进行文本情感分析的主要内容,如果未能解决你的问题,请参考以下文章