Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例
Posted rask
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例相关的知识,希望对你有一定的参考价值。
需求
1.统计音乐点播次数
2.使用echarts柱状图显示每首音乐的点播次数
项目结构
创建JavaEE项目
统计播放次数Job关键代码
package com.etc.mc;
import java.io.IOException;
import java.util.HashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/** 歌曲点播统计 */
public class MusicCount
//定义保存统计数据结果的map集合
public static HashMap<String, Integer> map=new HashMap<String, Integer>();
public static class MusicMapper extends Mapper<Object, Text, Text, IntWritable>
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
IntWritable valueOut = new IntWritable(1);
String keyInStr = value.toString();
String[] keyInStrArr = keyInStr.split("\\t");// 使用\\t将输入 文本行转换为字符串
String keyOut = keyInStrArr[0];// 获取歌曲名称
context.write(new Text(keyOut), valueOut);
public static class MusicReducer extends Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
result.set(sum);
context.write(key, result);//统计数据保存到hdfs文件
map.put(key.toString(), sum);//将统计结果保存到map集合
public static HashMap<String, Integer> main() throws Exception
Configuration conf = new Configuration();
conf.addResource("core-site.xml");// 读取项目中hdfs配置信息
conf.addResource("mapred-site.xml");// 读取项目中mapreduce配置信息
// 实例化作业
Job job = Job.getInstance(conf, "music_count");
// 指定jar的class
job.setJarByClass(MusicCount.class);
// 指定Mapper
job.setMapperClass(MusicMapper.class);
// 压缩数据
job.setCombinerClass(MusicReducer.class);// 减少datanode,TaskTracker之间数据传输
// 指定reducer
job.setReducerClass(MusicReducer.class);
// 设置输出key数据类型
job.setOutputKeyClass(Text.class);
// 设置输出Value数据类型
job.setOutputValueClass(IntWritable.class);
// 设置输入文件路径
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music1.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music2.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music3.txt"));
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.137.131:9000/music/music4.txt"));
//设置输出文件路径
FileSystem fs=FileSystem.get(conf);
Path path=new Path("hdfs://192.168.137.131:9000/musicout");
if(fs.exists(path))
fs.delete(path,true);
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.137.131:9000/musicout"));
if(job.waitForCompletion(true))
return map;
else
return null;
Servlet关键代码
package com.etc.action;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.HashMap;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.alibaba.fastjson.JSON;
import com.etc.mc.MusicCount;
/**向客户端提供json数据*/
@WebServlet("/CountServlet")
public class CountServlet extends HttpServlet
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
//post乱码处理
request.setCharacterEncoding("utf-8");
// 设置响应数据类型
response.setContentType("text/html");
// 设置响应编码格式
response.setCharacterEncoding("utf-8");
// 获取out对象
PrintWriter out = response.getWriter();
//组织json数据
HashMap<String, Integer> map=null;
try
map=MusicCount.main();
catch (Exception e)
System.out.println("获取数据出错");
//通过构建map集合转换为嵌套json格式数据
HashMap jsonmap = new HashMap();
jsonmap.put("mytitle","歌词播放统计");
jsonmap.put("mylegend", "点播");
jsonmap.put("prolist", map);
String str =JSON.toJSONString(jsonmap);
out.print(str);
out.flush();
out.close();
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
doGet(request, response);
视图index.jsp关键代码
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>金融大数据解析</title> <!-- 引入 echarts.js --> <script src="script/echarts.min.js"></script> <!-- 引入 jquery.js --> <script src="script/jquery-1.8.3.min.js"></script> </head> <body> <!-- 为ECharts准备一个具备大小(宽高)的Dom --> <div id="main" style="width: 600px; height: 400px;"></div> <script type="text/javascript"> //显示柱状图函数 function showdata(mytitle, mylegend, xdata, ydata) // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById(‘main‘)); // 指定图表的配置项和数据 var option = title : text : mytitle , tooltip : , legend : data : mylegend , xAxis : data : xdata , yAxis : , series : [ name : ‘点播‘, type : ‘bar‘, data : ydata ] ; // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); $(function() var mytitle; var mylegend; var xdata=new Array(); var ydata=new Array(); $.getJSON("CountServlet", function(data) mytitle = data.mytitle; mylegend = data.mylegend; //获取x轴数据 $.each(data.prolist, function(i, n) xdata.push(i); ); //获取y轴数据 $.each(data.prolist, function(i, n) ydata.push(n); ); //执行函数 showdata(mytitle, [ mylegend ], xdata, ydata); ); ); </script> </body> </html>
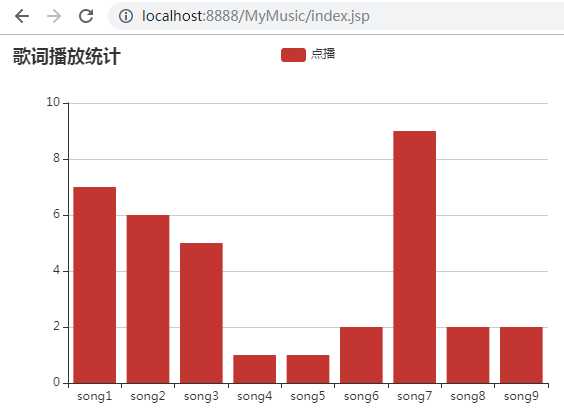
运行结果
项目所需jar列表

总结
1.该案例的缺点是什么?每次访问数据需要提交job到hadoop集群运行,性能低。
2.数据分析结果保存在HDFS和集合中,不适合分析结果为大数据集合。
3.如何改进?使用HBase存储解析后的数据集,构建离线分析和即时查询大数据分析平台。
以上是关于Hadoop-02 基于Hadoop的JavaEE数据可视化简易案例的主要内容,如果未能解决你的问题,请参考以下文章