爬虫 + 数据分析 - 7 CrawlSpider(全站爬取), 分布式, 增量式爬虫
Posted lw1095950124
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫 + 数据分析 - 7 CrawlSpider(全站爬取), 分布式, 增量式爬虫相关的知识,希望对你有一定的参考价值。
一.全站爬取(CrawlSpider)
1.基本概念
作用:就是用于进行全站数据的爬取
- CrawlSpider就是Spider的一个子类
- 如何新建一个基于CrawlSpider的爬虫文件 - scrapy genspider -t crawl xxx www.xxx.com
- LinkExtractor连接提取器:根据指定规则(正则)进行连接的提取 - Rule规则解析器:将链接提取器提取到的链接进行请求发送,然后对获取的页面数据进行 指定规则(callback)的解析 - 一个链接提取器对应唯一一个规则解析器
2.项目示例
①.爬取抽屉网多页数据对象
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ChoutiSpider(CrawlSpider):
name = ‘chouti‘
# allowed_domains = [‘www.ccc.coim‘]
start_urls = [‘https://dig.chouti.com/all/hot/recent/1‘]
#链接提取器:从起始url对应的页面中提取符合规则的链接。allow=》正则
link= LinkExtractor(allow=r‘/all/hot/recent/\\d+‘)
rules = (
#规则解析器:将链接提取器提取到的链接对应的页面源码进行指定规则的解析
Rule(link, callback=‘parse_item‘, follow=True),
#follow:True 将连接提取器 继续 作用到 连接提取器提取出来的链接 对应的页面源码中
#False:只提取当前页匹配的地址
)
def parse_item(self, response):
print(response)
②爬取阳光热线 多页及详情页数据,持久化存储
#爬虫文件中:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from sunLinePro.items import SunlineproItem,ContentItem class SunSpider(CrawlSpider): name = ‘sun‘ # allowed_domains = [‘www.xxx.com‘] start_urls = [‘http://wz.sun0769.com/index.php/question/questionType?type=4&page=‘] link= LinkExtractor(allow=r‘type=4&page=\\d+‘)#提取页码连接 link1 = LinkExtractor(allow=r‘question/2019\\d+/\\d+\\.shtml‘)#提取详情页的链接 rules = ( Rule(link, callback=‘parse_item‘, follow=False), Rule(link1, callback=‘parse_detail‘), ) #解析出标题和网友名称 def parse_item(self, response): tr_list = response.xpath(‘//*[@id="morelist"]/div/table[2]//tr/td/table//tr‘) for tr in tr_list: title = tr.xpath(‘./td[2]/a[2]/text()‘).extract_first() netFriend = tr.xpath(‘./td[4]/text()‘).extract_first() item = SunlineproItem() item[‘title‘] = title item[‘netFriend‘] = netFriend yield item #解析出新闻的内容 def parse_detail(self,response): content = response.xpath(‘/html/body/div[9]/table[2]//tr[1]/td/div[2]//text()‘).extract() content = ‘‘.join(content) item = ContentItem() item[‘content‘] = content yield item
#在 items.py 文件中:
import scrapy class SunlineproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() netFriend = scrapy.Field() class ContentItem(scrapy.Item): # define the fields for your item here like: content = scrapy.Field()
#在管道文件中:
class SunlineproPipeline(object): def process_item(self, item, spider): #接收到的item究竟是什么类型的 if item.__class__.__name__ ==‘SunlineproItem‘: print(item[‘title‘],item[‘netFriend‘]) else: print(item[‘content‘]) return item
二.分布式
1.基本概念
- 概念:可以将一组程序执行在多台机器上(分布式机群),使其进行数据的分布爬取。
- 原生的scrapy框架是否可以实现分布式? - 不可以? - 调度器不可以被分布式机群共享 - 管道不可以被分布式机群共享
- 借助scrapy-redis这个模块帮助scrapy实现分布式 - scrapy-redis作用: - 可以提供可以被共享的管道和调度器
安装模块: - pip install scrapy-redis
2.实现流程
- 分布式的实现流程:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 修改爬虫文件的代码:
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 将start_urls删除
- 添加一个新属性redis_key = ‘ts‘:可以被共享的调度器中的队列名称
- 设置管道:
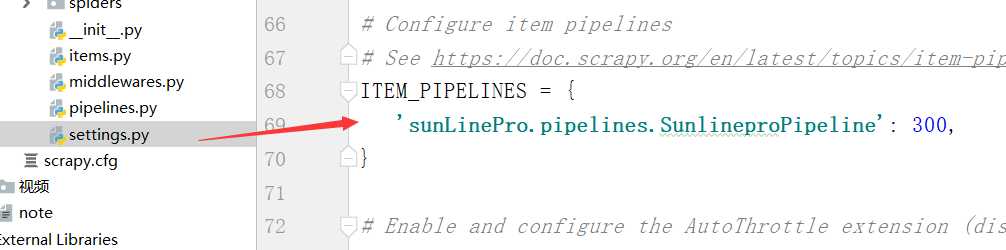
ITEM_PIPELINES =
‘scrapy_redis.pipelines.RedisPipeline‘: 400
# ‘scrapyRedisPro.pipelines.ScrapyredisproPipeline‘: 300,
- 设置调度器:
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器
REDIS_HOST = ‘192.168.12.154‘
REDIS_PORT = 6379
- 配置redis:
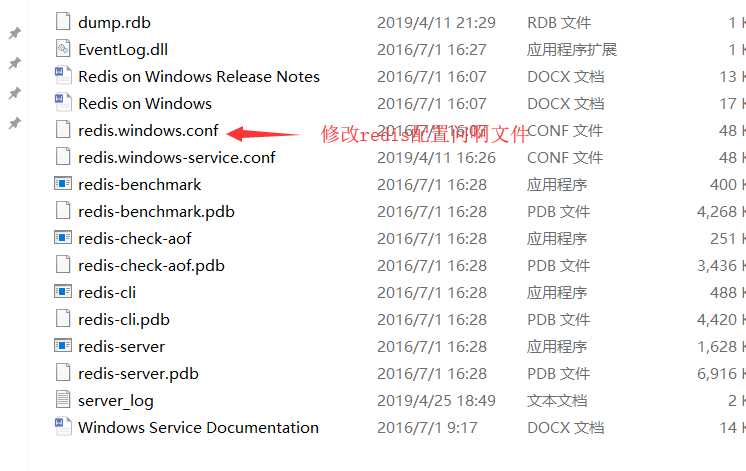
修改Redis的配置文件:redis.windows.conf
- #bind 127.0.0.1
- protected-mode no
- 携带配置文件启动redis服务
- redis-server ./redis.windows.conf
- 启动redis客户端
- 执行工程:scrapy runspider xxx.py (执行爬虫py文件)
- 手动将起始url扔入调度器的队列中(redis-cli):lpush ts www.xxx.com
- redis-cli: items:xxx
3.示例(阳光热线的爬取):
# 在爬虫文件中
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapyRedisPro.items import ScrapyredisproItem from scrapy_redis.spiders import RedisCrawlSpider from scrapy_redis.spiders import RedisSpider class TestSpider(RedisCrawlSpider): name = ‘test‘ # allowed_domains = [‘www.xxx.com‘] # start_urls = [‘http://www.xxx.com/‘] redis_key = ‘ts‘ #可以被共享的调度器中的队列名称 rules = ( Rule(LinkExtractor(allow=r‘type=4&page=\\d+‘), callback=‘parse_item‘, follow=True), ) def parse_item(self, response): tr_list = response.xpath(‘//*[@id="morelist"]/div/table[2]//tr/td/table//tr‘) for tr in tr_list: title = tr.xpath(‘./td[2]/a[2]/text()‘).extract_first() netFriend = tr.xpath(‘./td[4]/text()‘).extract_first() item = ScrapyredisproItem() item[‘title‘] = title item[‘net‘] = netFriend yield item #提交的item必须保证提交到可以被共享的管道中
#在items.py 文件中:
import scrapy class ScrapyredisproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() net = scrapy.Field()
#在setting.py文件中:
# -*- coding: utf-8 -*- # Scrapy settings for scrapyRedisPro project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘scrapyRedisPro‘ SPIDER_MODULES = [‘scrapyRedisPro.spiders‘] NEWSPIDER_MODULE = ‘scrapyRedisPro.spiders‘ USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘scrapyRedisPro (+http://www.yourdomain.com)‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, # # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = # ‘scrapyRedisPro.middlewares.ScrapyredisproSpiderMiddleware‘: 543, # # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = # ‘scrapyRedisPro.middlewares.ScrapyredisproDownloaderMiddleware‘: 543, # # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = # ‘scrapy.extensions.telnet.TelnetConsole‘: None, # # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = ‘scrapy_redis.pipelines.RedisPipeline‘: 400 # ‘scrapyRedisPro.pipelines.ScrapyredisproPipeline‘: 300, # 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据 SCHEDULER_PERSIST = True REDIS_HOST = ‘192.168.12.154‘ REDIS_PORT = 6379 # 网速号可开多个线程(影响不大) CONCURRENT_REQUESTS = 2


三.增量式爬虫
概念:通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新出的新数据。
如何进行增量式的爬取工作: 在发送请求之前判断这个URL是不是之前爬取过 在解析内容后判断这部分内容是不是之前爬取过 写入存储介质时判断内容是不是已经在介质中存在 分析: 不难发现,其实增量爬取的核心是去重, 至于去重的操作在哪个步骤起作用,只能说各有利弊。在我看来,
前两种思路需要根据实际情况取一个(也可能都用)。第一种思路适合不断有新页面出现的网站,比如说小说的新章节,
每天的最新新闻等等;第二种思路则适合页面内容会更新的网站。第三个思路是相当于是最后的一道防线。
这样做可以最大程度上达到去重的目的。 去重方法: 将爬取过程中产生的url进行存储,存储在redis的set中。当下次进行数据爬取时,
首先对即将要发起的请求对应的url在存储的url的set中做判断,如果存在则不进行请求,否则才进行请求。 对爬取到的网页内容进行唯一标识的制定,然后将该唯一表示存储至redis的set中。当下次爬取到网页数据的时候,
在进行持久化存储之前,首先可以先判断该数据的唯一标识在redis的set中是否存在,在决定是否进行持久化存储。
- 概念:监测网上数据更新的情况。
1.对url去重
- 利用 redis中的 sadd存储类型
2.对数据去重
- 数据指纹
1.对url去重(爬取4567电影网数据)
#在爬虫文件中:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from redis import Redis from moviePro.items import MovieproItem class MovieSpider(CrawlSpider): name = ‘movie‘ # allowed_domains = [‘www.xxx.com‘] start_urls = [‘https://www.4567tv.tv/frim/index1.html‘] link = LinkExtractor(allow=r‘/frim/index1-\\d+.html‘) rules = ( Rule(link, callback=‘parse_item‘, follow=False), ) conn = Redis(host=‘127.0.0.1‘,port=6379) #解析电影的名称和详情页的url def parse_item(self, response): li_list = response.xpath(‘/html/body/div[1]/div/div/div/div[2]/ul/li‘) for li in li_list: title = li.xpath(‘./div/a/@title‘).extract_first() detail_url = ‘https://www.4567tv.tv‘+li.xpath(‘./div/a/@href‘).extract_first() item = MovieproItem() item[‘title‘] = title #判断该详情页的url是否进行请求发送 ex = self.conn.sadd(‘movie_detail_urls‘,detail_url) if ex == 1:#说明detail_url不存在于redis的set中 print(‘已有最新数据更新,请爬......‘) yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta=‘item‘:item) else: print(‘暂无新数据的更新!!!‘) def parse_detail(self,response): item = response.meta[‘item‘] desc = response.xpath(‘/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()‘).extract_first() item[‘desc‘] = desc yield item
#在items.py 文件中
import scrapy class MovieproItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() desc = scrapy.Field()
#在管道文件中:
class MovieproPipeline(object): def process_item(self, item, spider): dic = ‘title‘:item[‘title‘], ‘desc‘:item[‘desc‘] conn = spider.conn #存储 conn.lpush(‘movie_data‘,dic) return item
2.对数据的去重(糗事百科)
用hashlib.sha256生成唯一的 数据指纹
存放在redis中的 sadd数据类型中
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from incrementByDataPro.items import IncrementbydataproItem
from redis import Redis
import hashlib
class QiubaiSpider(CrawlSpider):
name = ‘qiubai‘
# allowed_domains = [‘www.xxx.com‘]
start_urls = [‘https://www.qiushibaike.com/text/‘]
rules = (
Rule(LinkExtractor(allow=r‘/text/page/\\d+/‘), callback=‘parse_item‘, follow=True),
Rule(LinkExtractor(allow=r‘/text/$‘), callback=‘parse_item‘, follow=True),
)
#创建redis链接对象
conn = Redis(host=‘127.0.0.1‘,port=6379)
def parse_item(self, response):
div_list = response.xpath(‘//div[@id="content-left"]/div‘)
for div in div_list:
item = IncrementbydataproItem()
item[‘author‘] = div.xpath(‘./div[1]/a[2]/h2/text() | ./div[1]/span[2]/h2/text()‘).extract_first()
item[‘content‘] = div.xpath(‘.//div[@class="content"]/span/text()‘).extract_first()
#将解析到的数据值生成一个唯一的标识进行redis存储
source = item[‘author‘]+item[‘content‘]
source_id = hashlib.sha256(source.encode()).hexdigest()
#将解析内容的唯一表示存储到redis的data_id中
ex = self.conn.sadd(‘data_id‘,source_id)
if ex == 1:
print(‘该条数据没有爬取过,可以爬取......‘)
yield item
else:
print(‘该条数据已经爬取过了,不需要再次爬取了!!!‘)
# 在管道文件中:
from redis import Redis class IncrementbydataproPipeline(object): conn = None def open_spider(self, spider): self.conn = Redis(host=‘127.0.0.1‘, port=6379) def process_item(self, item, spider): dic = ‘author‘: item[‘author‘], ‘content‘: item[‘content‘] # print(dic) self.conn.lpush(‘qiubaiData‘, dic) return item
以上是关于爬虫 + 数据分析 - 7 CrawlSpider(全站爬取), 分布式, 增量式爬虫的主要内容,如果未能解决你的问题,请参考以下文章