Java基础--JDBC
Posted l-y-h
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基础--JDBC相关的知识,希望对你有一定的参考价值。
一、JDBC
1、JDBC简介
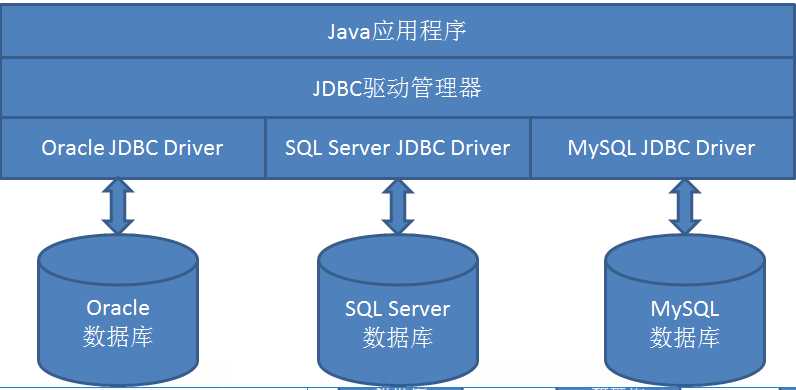
(1) JDBC(Java Database Connectivity),即Java数据库连接。用于在Java程序中实现数据库操作功能。
(2)是一种用于执行SQL语句的Java API,使用户以相同的方式连接不同的数据库。
(3)JDBC提供一套标准接口,即访问数据库通用的API,不同的数据库厂商会根据各自的数据库特点去实现这些接口。
2、JDBC工作步骤
(1)加载驱动(使用Class.forName),建立连接(DriverManager)并返回连接(Connection)。
(2)创建语句对象。(Connection 创建一个 Statement 或 PreparedStatement , 用于执行SQL语句)
(3)执行SQL语句。(Statement 或 PreparedStatement执行SQL语句)
(4)处理结果集。(SELECT产生结果集ResultSet)
(5)关闭连接。(依次将ResultSet、Statement、PreparedStatement、Connection对象关闭,释放资源。)
3、为什么要释放资源、关闭连接?
(1)释放资源:
由于JDBC驱动在底层通常通过网络I/O实现SQL命令以及数据传输的,所以资源的释放有利于系统的运行。且由于是操作I/O,所以代码块需要抛出异常(即代码块写在try-catch语句或者通过throws抛出。)。
(2)关闭连接:
JDBC只有建立与数据库的连接才能访问数据库,而与数据库连接是非常重要的连接,若不能及时释放,会浪费资源。同时每次使用createStatement()方法以及prepareStatement()方法都会在数据库中打开一个游标(cursor),若不能即使关闭,可能导致程序抛出异常。
二、加载驱动、建立连接
使用JDBC连接Oracle数据库时,涉及I/O操作,需要捕获异常,可以写在try-catch中。如果抛出异常:java.lang.ClassNotFoundException,则可能是未导入连接数据库的相关jar包。
1、oracle
//加载JDBC驱动,通过反射机制加载 Class.forName("oracle.jdbc.driver.OracleDriver"); //连接路径,用于连接数据库 String url = "jdbc:oracle:thin:@localhost:1521:xe"; String userName = "LYH"; //默认用户名 String userPwd = "SYSTEM"; //密码 //建立连接 Connection conn = DriverManager.getConnection(url, userName, userPwd); 注: Oracle连接方式: jdbc:oracle:thin:@<IP地址>:<port端口号>:<SID> 路径,jdbc:oracle:thin:@是固定写法, localhost是主机号(IP地址),1521是端口号(Port),xe是SID(用于标识数据库)。 LYH是数据库(用户)名 SYSTEM是密码(口令)
2、mysql(8.0之后的版本)
//加载JDBC驱动,通过反射机制加载 Class.forName("com.mysql.cj.jdbc.Driver"); //连接路径,用于连接数据库 //String url = "jdbc:mysql://localhost:3306/test"; String url = "jdbc:mysql://localhost:3306/test?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=false"; String userName = "LYH"; //默认用户名 String userPwd = "SYSTEM"; //密码 //建立连接 Connection conn = DriverManager.getConnection(url, userName, userPwd); 注: mySql连接方式: jdbc:mysql://<IP地址>:<port端口号>/<dbname相当于SID> JDBC连接mysql 5需用com.mysql.jdbc.Driver 即: Class.forName("com.mysql.jdbc.Driver"); url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&useSSL=false
3、sql server 2005
//加载JDBC驱动,通过反射机制加载 Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); //连接路径,用于连接数据库 tempdb String url = "jdbc:sqlserver://localhost:1433;DatabaseName=tempdb"; String userName = "sa"; //默认用户名 String userPwd = "123456"; //密码 //建立连接 Connection conn = DriverManager.getConnection(url, userName, userPwd);
三、Statement、PreparedStatement 、CallableStatement、ResultSet、ResultSetMetaData
1、Statement
(1)Statement主要用于执行静态SQL语句(不带参数),即内容固定不变的SQL语句。
(2)Statement每执行一次都要对传入的SQL语句编译一次,效率较差。
创建Statement的方式: Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:xe", "LYH", "SYSTEM"); Statement state = conn.createStatement(); 1、执行DDL语句: 格式: boolean flag = state.execute(sql); 2、执行DML语句:(返回值为DML影响的数据库中的数据总条数) 格式: int length = state.executeUpdate(sql); 3、执行DQL语句:(SELECT语句) 格式: ResultSet rs = state.executeQuery(sql); 注:sql语句中不要带分号(;)。
2、PreparedStatement(可以预防sql注入攻击)
(1) PreparedStatement可用于动态SQL语句,即SQL部分参数改变,其余条件不变。适用于多次执行SQL语句的时候,以提高效率。
(2)PreparedStatement是一个接口,继承Statement。但其execute等三个方法不需要参数了。
(3)PreparedStatement实例包含已编译的SQL语句。以符号(?)作为占位符,?表示一个任何类型的参数。
创建PreparedStatement的方式: Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:xe", "LYH", "SYSTEM"); prepareStatement pstate = conn.createStatement(); sql = "select * from where id = ?"; pstate = conn.prepareStatement(sql); //预编译sql语句 设定参数 pstate.setString(1, "12345"); 1、执行DDL语句: 格式: boolean flag = pstate.execute(); 2、执行DML语句:(返回值为DML影响的数据库中的数据总条数) 格式: int length = pstate.executeUpdate(); 3、执行DQL语句:(SELECT语句) 格式: ResultSet rs = pstate.executeQuery(); 注:sql语句中不要带分号(;)。
3、 CallableStatement
提供了用来调用数据库存储过程的接口,如果有输出参数需要注册,则说明是输出参数。其调用存储过程有两种方式:带结果参数(一种输出参数,是存储过程的返回值) 与 不带结果参数。CallableStatement继承了PreparedStatement处理输入参数的方法,且还增加了调用数据库的存储过程和函数以及设置输出类型参数的功能。
4、ResultSet、ResultSetMetaData
ResultSet表示的是DQL语句的结果集,但其结果集仍在数据库上(每次只取一定数量的数据放入内存,具体数量由不同的数据库驱动决定),若想取数据,需使用next方法每次取一条,其是与数据库一直连接的,当查询结束后,最好将其关闭,要不然可能会抛出异常。
ResultSet获取结果集
格式:
ResultSet Statement.executeQuery(sql);
ResultSet PreparedStatement.executeQuery();
ResultSetMetaData获取结果集的元数据,元数据指数据的数据,用于描述数据的属性、信息。
格式:
ResultSetMetaData ResultSet.getMetaData();
5、PreparedStatement相比于Statement的优点
(1)效率更高。
使用PreparedStatement对象执行SQL语句时,命令会被数据库进行编译和解析,并将其放在命令缓冲区。每次执行PreparedStatement对象时,由于在缓冲区可以找到预编译命令,虽然会被解析一次,但是不会被再次编译,可以重复使用,从而提高了效率。
(2)代码可读性与可维护性更高。
由于PreparedStatement使用setInt()或者setString()方法为参数进行赋值,而Statement需要在SQL语句中写出,相比之下PreparedStatement更加清晰。
(3)安全性更好。
使用PreparedStatement可以有效防止SQL注入攻击。所谓SQL注入攻击,通常指的是将SQL语句通过插入到Web表单提交输入域名或者查询页面请求的查询字符串,最终达到欺骗服务器并且执行恶意SQL命令的目的。由于Statement是将输入的字符串当成SQL语句进行拼接,再进行编译,所以其不能防范SQL注入攻击,而PreparedStatement是将输入的字符串当成一个值来处理,避免了SQL注入攻击的问题。
【sql注入举例:】 SQL语句为: String str = " SELECT * FROM emp WHERE name = ‘" + name + "‘ AND password = ‘" + password‘"; 即相当于SQL语句 SELECT * FROM emp WHERE name = ‘?‘ AND password = ‘?‘ 如果输入name = "aa", password = "bb‘ OR ‘1‘ = ‘1" 那么相当于SQL语句: SELECT * FROM emp WHERE name = ‘aa‘ AND password = ‘bb‘ OR ‘1‘ = ‘1‘ 那么不管输入是否正确,此WHERE条件均是成立的。即SQL注入攻击成功。
四、使用连接池(DBCP)连接JDBC
1、什么是连接池?
连接池是管理与创建数据库连接的缓冲池技术,将连接提前准备好,方便使用。连接池也是一个接口,具体由不同厂商进行实现。
2、未使用DBCP时
一次数据库连接对应着一次物理连接,而每次操作数据都要打开、关闭这个连接,会消耗大量资源。
3、使用DBCP时
系统启动并连接数据库后,会自动创建一定数目的连接,并将这些连接组成一个连接池。每次连接时,会从连接池中取出一个连接,使用完后,将该连接放回连接池(注:此处不是关闭连接)。这样可以使连接重复使用,提高程序运行效率。
4、DBCP原则:
(1)系统启动时,连接到数据库后,会初始化创建一定数目的连接,并将其组成一个池。
(2)每次连接时,从池内取出已有连接,使用完后,将连接归还(不是关闭连接)给连接池。
(3)若池内无连接或达到最小连接数时,按增量增加新连接。
(4)保持最小连接数,其有动态检查、静态检查的方法。
动态检查:定时检查池,若数量小于最小连接数,则补充连接。
静态检查:当连接不足时,才检查数量是否小于最小连接数。
5、连接池导包
使用连接池,需要导包。
commons-dbcp-1.4.jar ;用于连接池的实现 commons-pool-1.5.jar ;连接池实现的依赖库 commons-collections4-4.0.jar ;
五、实例:
1、使用普通的JDBC,直接在代码中赋值
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; /** * 使用JDBC连接Oracle数据库 * 涉及I/O操作,需要捕获异常,可以写在try-catch中。 * * 如果抛出异常:java.lang.ClassNotFoundException, * 那么表示未导入包,比如:Oracle 11g JDBC_ojdbc6.jar。 * */ public class Test public static void main(String[] args) try //1、加载驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //建立连接,并返回Connection连接 Connection conn = DriverManager.getConnection( "jdbc:oracle:thin:@localhost:1521:xe", "LYH", "SYSTEM"); //2、创建Statement对象 Statement state = conn.createStatement(); //定义sql语句 String sql = "SELECT * FROM emp"; //执行SQL查询语句,结果集由ResultSet保存 ResultSet rs = state.executeQuery(sql); //循环输出结果集 while(rs.next()) int id = rs.getInt("id"); String name = rs.getString("name"); double salary = rs.getDouble("salary"); System.out.println("id = " + id + ",name = " + name + ",salary = " + salary); rs.close();//关闭SQL连接 conn.close();//关闭数据库连接 catch(Exception e) e.printStackTrace();
2、使用properties的配置文件赋值
通过修改配置文件来实现代码功能的改变,可以不用修改class文件,便于开发。
【格式:】 string1 = string2 # 尾部没有分号(;) # 表示注释 java.util.Properties;该类用于读取properties文件,并以Map集合的形式存储文件内容。 【读取文件步骤:】 1、先使用InputStream is(或其他输入流)读取文件。 2、再使用load(is) 加载文件。 3、使用getProperty(String key),通过等号左边(key)值,获取等号右边(value)值。 4、有一个线程ThreadLocal<Connection>,其内部操作的为一个Map集合,相当于<Thread, Connection>,将线程作为key。 ThreadLocal有个set方法,会将当前线程作为key,并将给定的值放入Map中,这样便于知道具体某个值是哪个线程所调用的,方便操作。 【举例:】 //定义一个连接数据库,并可以关闭数据库的类。 //DefineConnection.class import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.util.Properties; /** * 自定义一个连接数据库的类, * 写在Static块中,用于从properties文件中获取值,并加载驱动。 * * 声明一个连接数据库方法,一个关闭数据库方法。 * */ public class DefineConnection private static String driver; //保存驱动 private static String url; //保存路径 private static String user; //保存数据库(用户)名 private static String password; //保存密码(口令) private static ThreadLocal<Connection> tl = new ThreadLocal<Connection>(); //用于管理不同的线程获取的连接。 static try //实例化一个Properties类,用于读取properties文件 Properties prop = new Properties(); //通过相对路径获取文件 InputStream is = DefineConnection.class.getClassLoader().getResourceAsStream("config.properties"); //加载文件,并以类似Map的形式保存 prop.load(is); //关闭输入流 is.close(); //从文件中将等号左边作为Key,获取等号右边的值 driver = prop.getProperty("driver"); url = prop.getProperty("url"); user = prop.getProperty("user"); password = prop.getProperty("password"); //加载驱动 Class.forName(driver); catch (Exception e) e.printStackTrace(); /** * 用于连接数据库 * @return * @throws Exception */ public static Connection getConnection() throws Exception try Connection conn = DriverManager.getConnection(url, user, password); tl.set(conn); return conn; catch (Exception e) e.printStackTrace(); throw e; //通知调用者,调用出错 /** * 用于关闭数据库 * @param conn * @throws Exception */ public static void closeConnection() throws Exception try /* * 通过ThreadLocal指定的线程,获取指定的连接,并将其断开。 * 使用ThreadLocal可以不给方法加指定参数,就能获取该值。 * 适用于多个线程混合调用,获取具体值的时候。 */ Connection conn = tl.get(); if(conn != null) conn.close(); tl.remove(); catch (Exception e) e.printStackTrace(); throw e; //定义一个测试类: //Test.class import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; public class Test public static void main(String[] args) try //获取连接 Connection conn = DefineConnection.getConnection(); //获取Statement对象 Statement state = conn.createStatement(); //定义SQL语句 String sql = "SELECT * FROM emp"; //执行SQL语句,得结果集 ResultSet rs = state.executeQuery(sql); //遍历结果集 while(rs.next()) int id = rs.getInt("id"); String name = rs.getString("name"); double salary = rs.getDouble("salary"); System.out.println("id = " + id + ", name = " + name + ", salary = " + salary); //关闭SQL连接 rs.close(); //关闭数据库连接 DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace();
3、使用连接池
//config.properties //配置文件,用于存储数据库的一些信息 driver=oracle.jdbc.driver.OracleDriver user=LYH password=SYSTEM url=jdbc:oracle:thin:@localhost:1521:xe max=30 initialsize=10 //自定义一个类,定义一个数据库连接池,用于连接数据库. //DefineConnection.class import java.io.InputStream; import java.sql.Connection; import java.util.Properties; import org.apache.commons.dbcp.BasicDataSource; /** * 自定义一个数据库连接池,并使用其连接数据库 * */ public class DefineConnection //声明连接池 private static BasicDataSource dbs; //声明线程 private static ThreadLocal<Connection> tl = new ThreadLocal<Connection>();; static try //实例化一个Properties类 Properties prop = new Properties(); //读取一个类 InputStream is = DefineConnection.class.getClassLoader().getResourceAsStream("config.properties"); prop.load(is); //初始化连接池 dbs = new BasicDataSource(); //设置驱动 dbs.setDriverClassName(prop.getProperty("driver")); //设置连接路径 dbs.setUrl(prop.getProperty("url")); //设置数据库(用户)名 dbs.setUsername(prop.getProperty("user")); //设置密码(口令) dbs.setPassword(prop.getProperty("password")); //设置连接最大值 dbs.setMaxActive(Integer.parseInt(prop.getProperty("max"))); //设置初始连接数 dbs.setInitialSize(Integer.parseInt(prop.getProperty("initialsize"))); is.close(); catch (Exception e) e.printStackTrace(); /** * 使用连接池连接数据库 * @return * @throws Exception */ public static Connection getConnection() throws Exception try //连接数据库 Connection conn = dbs.getConnection(); tl.set(conn); return conn; catch (Exception e) e.printStackTrace(); throw e; /** * 返回数据库连接进连接池 * @throws Exception */ public static void closeConnection() throws Exception try Connection conn = tl.get(); if(conn != null) conn.close();//归还连接给连接池,并关闭连接 tl.remove();//删除不需要的线程 catch (Exception e) e.printStackTrace(); throw e; //定义一个测试类,使用自定义数据库连接类,连接数据库进行测试 //Test.class; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; public class Test public static void main(String[] args) try Connection conn = DefineConnection.getConnection(); Statement state = conn.createStatement(); String sql = "SELECT id, name FROM emp"; ResultSet rs = state.executeQuery(sql); while(rs.next()) int id = rs.getInt("id"); String name = rs.getString("name"); System.out.println("id = " + id + ", name = " + name); rs.close(); DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace();
六、JDBC事务隔离级别(5种)
1、为什么有事务隔离?
为了解决多个线程请求相同数据的情况,事务间通常用锁进行隔离,从而衍生出事务隔离级别。事务隔离级别越高,避免冲突的操作越繁琐。可以通过Connection对象的setTransactionLevel()方法来设置隔离级别,通过conn.getTransactionLevel()方法确定当前事务级别。
2、相关概念:
(1)读“脏”数据:指一个事务读取了另一个事务尚未提交的数据,即读取到无效数据。比如:A与B事务并发执行,事务A进行更新操作后,B读取A尚未提交的数据,此时A由于某原因进行回滚,那么此时B读到的数据即为无效的脏数据。
(2)不可重复读:指一个事务的操作导致另一个事务前后两次读取的数据不一致。比如:事务A与B并发执行,某时刻事务A更新了事务B读取的数据,当B再次读取数据时,会得到不同的数据。
(3)虚读:指一个事务的操作导致另一个事务前后两次查询的数据量不同。比如:事务A与B并发执行,某时刻事务A删除或增加了事务B所查询的表的记录,那么当事务B再次查询该表时,会得到不存在或者缺少的记录。
3、事务隔离级别(5种,以下级别由低到高):
(1)TRANSACTION_NONE_JOB(transaction_none_job):不支持事务。
(2)TRANSACTION_READ_UNCOMMITTED(transaction_read_uncommitted):未提交的读,说明此时一个事务未提交前,可以看到另外一个事务的变化。允许 读“脏”数据,不可重复读,虚读。
(3)TRANSACTION_READ_COMMITTED(transaction_read_committed):已提交的读,此时不能读取未提交的数据(即不能读脏数据),但仍允许不可重复读,虚读。
(4)TRANSACTION_REPEATABLE_READ(transaction_repeatable_read):可重复读,此时读取相同数据不会失败,但仍允许虚读。
(5)TRANSACTION_SERIALIZABLE(transaction_serializable):可序列化,最高事务隔离级别。防止读脏数据、不可重复读、虚读。
七、批处理、分页机制
1、批处理优势
(1)批处理:将一组发送到数据库的语句(多条语句)作为一个单元处理。
(2)批处理降低了应用程序和数据库间的相互调用。
(3)相比单个SQL语句处理,批处理更加高效。
(4)批处理一般用于DML操作。
2、批处理相关方法
Statement方法: Statement.addBatch(String sql);将多条sql语句添加到Statement对象的SQL语句列表中。 PreparedStatement方法: PreparedStatement.addBatch();将多条预编译sql语句添加到PreparedStatement对象的SQL语句列表中。 int[] executeBatch();返回值为每一条语句影响的数据量。 将Statement对象或PreparedStatement对象SQL语句列表中的所有SQL语句发给数据库进行处理。 clearBatch() 清空当前SQL语句列表。
3、分页机制
(1)第一种机制:
每次只向数据库中请求一页的数据量,内存压力小,适合大数据量的数据表。
(2)第二种机制:(基于缓存的分页技术,又称假分页)
第一次一次性将数据全部取出到缓存,根据用户输入的页数(page)和每页记录数(pagesize)来计算哪些数据显示,将可滚动结果集的指针移到指定位置。只访问数据库一次,适合小数据量。
MySql的分页实现: SELECT * FROM emp LIMIT begin(从第几条开始), pagesize(每页条数); Oracle分页实现: SELECT * FROM( SELECT ROWNUM rn, t.* FROM( SELECT * FROM tableName ORDER BY colName ) t ) WHERE rn BETWEEN ? AND ? 【举例:】 import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.util.Scanner; public class Page public static void main(String[] args) Scanner scan = new Scanner(System.in); System.out.println("请输入要查看的表名:"); String tableName = scan.nextLine().trim(); System.out.println("请输入一页显示的页数:"); int pagesize = Integer.parseInt(scan.nextLine().trim()); System.out.println("请输入查看的页数:"); int page = Integer.parseInt(scan.nextLine().trim()); System.out.println("请输入排序的列名:"); String colName = scan.nextLine().trim(); try Connection conn = DefineConnection.getConnection(); /* * 分页步骤: * 1、排序。 * 2、编号。 * 3、取范围。 * SELECT * FROM( * SELECT ROWNUM rn, t.* FROM( * SELECT * FROM tableName ORDER BY colName * ) t * ) * WHERE rn BETWEEN ? AND ? */ String sql = "SELECT * FROM( " + "SELECT ROWNUM rn, t.* FROM( " + "SELECT * FROM "+tableName + " ORDER BY "+colName+" " + ") t " + ") " + "WHERE rn BETWEEN ? AND ?"; PreparedStatement ps = conn.prepareStatement(sql); int start = (page-1)*pagesize + 1; int end = page*pagesize; ps.setInt(1, start); ps.setInt(2, end); ResultSet rs = ps.executeQuery(); while(rs.next()) int rw = rs.getInt(1); int id = rs.getInt(2); String name = rs.getString(3); System.out.println("rw = "+rw +", id = " + id + ", name =" +name); catch (Exception e) e.printStackTrace(); finally try DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace();
4、自动返回主键
(1)PreparedStatement支持一个方法,可以在执行插入操作后,获取该语句在数据库表中产生记录中的每个字段的值。因此,每次向表中插入数据时,可以获取该主键作为外键插入,而不用单独为获取主键进行一次查询。
(2)用法:
创建PreparedStatement,可以使用Connection重载方法,第二个参数要求传入一个字符串数组,用来指定当通过ps执行插入操作后,记录想获取的字段所在的值。
PreparedStatement ps = conn.prepareStatement(sql, new String[]"id", "phone"); ResultSet rs = ps.getGeneratedKeys();//获取插入记录时想返回的字段值。 if(rs.next()) int id = rs.getInt("id"); //也可以写成int id = rs.getInt(1); String phone = rs.getString("phone");
八、补充
1、getString() 与 getObject()区别
JDBC提供getString(), getInt(), getData()等方法从ResultSet中获取数据,这些方法适用于数据量小且不考虑性能的情况。由于这些方法都是一次性将数据读取到内存中,然后再从内存中读取数据,如果数据量太大,可能造成写入内存缓慢甚至不能完全写入,这时将会抛出异常(以Oracle为例,ORA-01000)。
getObject()可以解决上面问题,其不会将数据一次性读取到内存中,每次调用均会到数据库中获取数据,使用此方法不会因数据量过大而报错。
2、JDBC事务采用方法
(1)事务:指的是数据库一个单独执行的单元(一条或多条SQL语句组成的不可分割的单元),要么完全执行,要么不执行。
(2)JDBC中一般采用commit()(用于提交) 和 rollback()(用于回滚)方法用来结束事务。位于java.sql.Connection类中。一般事务默认自动提交,即操作成功就提交,操作失败就回滚。
(3)可以通过调用setAutoCommit(false)方法来禁止自动提交,此时可以操作多个SQL语句后再提交,可在try-catch中调用rollback()方法进行事务回滚。此方法可以保持对数据库多次操作后仍能保持数据一致性。
3、什么是JDO?
(1)JDO指Java Data Object(Java数据对象),用于存取某种数据仓库中的对象的标准化API,从而使开发人员能够间接地访问数据库。
(2)JDO是JDBC的一个补充,提供了透明的对象存储,即开发人员不需要考虑存储数据对象的额外代码(由数据库开发商解决),只需考虑业务逻辑。
(3)JDO比JDBC更加灵活、通用,提供了任何底层数据的存储功能,可移植性更强。
4、什么是DAO?
(1)DAO(Data Access Object),指数据访问对象。其方法一般不为静态方法。
(2)建立在数据库和业务层之间,封装所有对数据库的访问。通过DAO将java对象转为数据库数据,或将数据库数据转为java对象。
(3)目的:将数据访问业务与业务逻辑分开。操作数据库变成面向对象化(Hibernate精髓)。
(4)DAO封装(面向接口编程):将所有对数据源的访问操作抽象到一个公共API中。先建立一个接口,并在接口中定义应用程序会用到的所有事务方法。再建立接口的实现类,实现接口对应的所有方法,与数据库进行交互。则在应用程序中,需要进行与数据源交互时,直接使用DAO接口,不用涉及任何数据库的具体操作。
即DAO包括:一个DAO工厂类,一个DAO接口,一个实现DAO接口的具体类,数据传递对象。
(5)DAO层需要定义对数据库中表的访问。对象关系映射(ORM,Object Relation Mapping)描述对象和数据表间的映射,将java程序中的对象对应到关系数据库的表中。
即表与类(实体类)对应,表中字段与类的属性对应,记录与对象对应。
实体类:用于描述数据库中的一张表。
//自定义数据库连接类: //DefineConnection.class //package DAO; import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.util.Properties; /** * 自定义一个连接数据库的类, * 写在Static块中,用于从properties文件中获取值,并加载驱动。 * * 声明一个连接数据库方法,一个关闭数据库方法。 * */ public class DefineConnection private static String driver; //保存驱动 private static String url; //保存路径 private static String user; //保存数据库(用户)名 private static String password; //保存密码(口令) private static ThreadLocal<Connection> tl = new ThreadLocal<Connection>(); //用于管理不同的线程获取的连接。 static try //实例化一个Properties类,用于读取properties文件 Properties prop = new Properties(); //通过相对路径获取文件 InputStream is = DefineConnection.class.getClassLoader().getResourceAsStream("config.properties"); //加载文件,并以类似Map的形式保存 prop.load(is); //关闭输入流 is.close(); //从文件中将等号左边作为Key,获取等号右边的值 driver = prop.getProperty("driver"); url = prop.getProperty("url"); user = prop.getProperty("user"); password = prop.getProperty("password"); //加载驱动 Class.forName(driver); catch (Exception e) e.printStackTrace(); /** * 用于连接数据库 * @return * @throws Exception */ public static Connection getConnection() throws Exception try Connection conn = DriverManager.getConnection(url, user, password); tl.set(conn); return conn; catch (Exception e) e.printStackTrace(); throw e; //通知调用者,调用出错 /** * 用于关闭数据库 * @param conn * @throws Exception */ public static void closeConnection() throws Exception try /* * 通过ThreadLocal指定的线程,获取指定的连接,并将其断开。 * 使用ThreadLocal可以不给方法加指定参数,就能获取该值。 * 适用于多个线程混合调用,获取具体值的时候。 */ Connection conn = tl.get(); if(conn != null) // 恢复连接为自动提交事务, conn.setAutoCommit(true); conn.close(); tl.remove(); catch (Exception e) e.printStackTrace(); throw e; //实体类:用于描述数据库中的user1表。 //User1.class: //package DAO; /** * 实体类,用于表示数据库的一张表, * 例如: * 实体类User1,用于表示数据库中的user1表 * */ public class User1 private int id; private String name; private String password; private int money; private String email; public int getId() return id; public void setId(int id) this.id = id; public String getName() return name; public void setName(String name) this.name = name; public String getPassword() return password; public void setPassword(String password) this.password = password; public int getMoney() return money; public void setMoney(int money) this.money = money; public String getEmail() return email; public void setEmail(String email) this.email = email; public User1(int id, String name, String password, int money, String email) super(); this.id = id; this.name = name; this.password = password; this.money = money; this.email = email; public User1() public String toString() return "id=" + id + ", name=" + name + ", password=" + password + ", money=" + money + ", email=" + email; //DAO层,用于将数据库中的数据与java类进行相互转换。 //User1DAO.class //package DAO; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Statement; import java.util.ArrayList; import java.util.List; /** * User1DAO, * 用于操作数据库user1表的DAO * */ public class User1DAO //预设一些SQL语句 private static final String FIND_BY_ID_SQL = "SELECT * " + "FROM user1 WHERE id = ?"; private static final String FIND_ALL_SQL = "SELECT * FROM user1"; private static final String MAX_ID_SQL = "SELECT MAX(id) FROM user1"; private static int maxId = 1; private static final String SAVE_SQL ="INSERT INTO user1 VALUES(?, ?, ?, ?, ?)"; /** * 根据ID查询对应的user1表中的记录 * @param id * @return */ public User1 findId(int id) try Connection conn = DefineConnection.getConnection(); PreparedStatement ps = conn.prepareStatement(FIND_BY_ID_SQL); ps.setInt(1, id); ResultSet rs = ps.executeQuery(); if(rs.next()) int i = rs.getInt("id"); String name = rs.getString("name"); String pwd = rs.getString("password"); int money = rs.getInt("money"); String email = rs.getString("email"); User1 user = new User1(i,name,pwd,money,email); return user; rs.close(); ps.close(); catch (Exception e) e.printStackTrace(); finally try DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace(); return null; /** * 查询所有的User1表的记录 * @return */ public List<User1> findALL() try Connection conn = DefineConnection.getConnection(); Statement state = conn.createStatement(); ResultSet rs = state.executeQuery(FIND_ALL_SQL); List<User1> users = new ArrayList<User1>(); while(rs.next()) int i = rs.getInt("id"); String name = rs.getString("name"); String pwd = rs.getString("password"); int money = rs.getInt("money"); String email = rs.getString("email"); User1 user = new User1(i,name,pwd,money,email); users.add(user); rs.close(); state.close(); return users; catch (Exception e) e.printStackTrace(); finally try DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace(); return null; /** * 获取User1表中最大的id值 * @return */ public int findMaxId() try Connection conn = DefineConnection.getConnection(); PreparedStatement ps = conn.prepareStatement(MAX_ID_SQL); ResultSet rs = ps.executeQuery(); if(rs.next()) maxId = rs.getInt(1); rs.close(); ps.close(); return maxId; catch (Exception e) e.printStackTrace(); finally try DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace(); return maxId; /** * 保存一个User信息到User1表 * @param user * @return */ public boolean save(User1 user) try maxId = findMaxId();//查询最大ID值 Connection conn = DefineConnection.getConnection();//获取连接 //使用Connection的重载方法,以便于返回自增的id。 PreparedStatement ps = conn.prepareStatement(SAVE_SQL, new String[] "id"); //设置参数 ps.setInt(1, user.getId()+1); ps.setString(2, user.getName()); ps.setString(3, user.getPassword()); ps.setInt(4, user.getMoney()); ps.setString(5, user.getEmail()); //若插入操作成功 if(ps.executeUpdate()>0) //获取自增的字段 ResultSet rs = ps.getGeneratedKeys(); rs.next(); //设置最大值id,主要为了看自增的效果,没啥实际意义 user.setId(rs.getInt(1)); //关流 rs.close(); ps.close(); return true; //未成功插入,也要关闭 ps.close(); catch (Exception e) e.printStackTrace(); finally try DefineConnection.closeConnection(); catch (Exception e) e.printStackTrace(); return false; //测试类,用于测试DAO效果。 //MyUserService.class //package DAO; import java.util.List; /** * 业务层, * 此时已经与数据库分开,由User1DAO分开。 * */ public class MyUserService public static void main(String[] args) //创建一个DAO层对象 User1DAO dao = new User1DAO(); //根据ID,找数据库中对应的信息 User1 user = dao.findId(1); System.out.println(user); //获取id最大值 int maxId = dao.findMaxId(); System.out.println("最大id为:"+maxId); //插入新的数据 user = new User1(maxId, "jarry", "123456", 10000, "[email protected]"); //成功的话,显示插入后最大的id,此处没实际意义,只为了显示自增的效果 if(dao.save(user)) System.out.println("插入数据成功!"); System.out.println("最大id为:"+user.getId()); //输出所有的信息 List<User1> users = dao.findALL(); for(User1 use : users) System.out.println(use);
5、JDBC 与 Hibernate区别
(1)Hibernate是JDBC的封装,采用配置文件的形式将数据库的连接参数写到XML文件中,但对数据库的访问还是通过JDBC来完成。
(2)Hibernate是一个持久层框架,将表的信息映射到XML文件中,再从XML文件中映射到相应的持久化类中,这样可以使用Hibernate独有的HQL语言(Hibernate Query Language),其返回结果为List<Object[.]>类。而JDBC的Statement的SQL查询语句,返回的是ResultSet结果集,需要自己将其封装在List集合中。
(3)Hibernate具有访问层(DAO类层,Data Access Object,数据访问接口),该层是唯一的HQL语句出现的地方,其上层不会再出现查询语句。此时假如有100个类都有SQL查询语句,当某个表名改变时,如果采用JDBC的方式,需要修改所有的类。而采用Hibernate时,只需要DAO层的类修改即可,因此Hibernate具有很好的维护性以及可扩展性。
以上是关于Java基础--JDBC的主要内容,如果未能解决你的问题,请参考以下文章