DPDK PCIe 与 包处理
Posted mysky007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DPDK PCIe 与 包处理相关的知识,希望对你有一定的参考价值。
参考文献:
《深入浅出DPDK》
linux 阅马场 公众号
..............................................................................................................
一. PCIe 介绍(参考 linux 阅马场文章)
首 先我们来看一下在x86系统中,PCIe是什么样的一个体系架构。下图是一个PCIe的拓扑结构示例,PCIe协议支持256个Bus, 每条Bus最多支持32个Device,每个Device最多支持8个Function,所以由BDF(Bus,device,function)构成了 每个PCIe设备节点的身份证号。
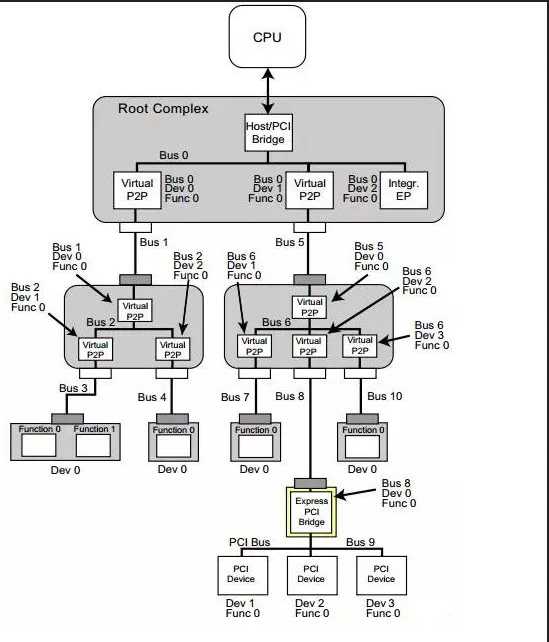
PCIe 体系架构一般由root complex,switch,endpoint等类型的PCIe设备组成,在root complex和switch中通常会有一些embeded endpoint(这种设备对外不出PCIe接口)。这么多的设备,CPU启动后要怎么去找到并认出它们呢? Host对PCIe设备扫描是采用了深度优先算法,其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。我们一般称 这个过程为PCIe设备枚举。枚举过程中host通过配置读事物包来获取下游设备的信息,通过配置写事物包对下游设备进行设置。
第 一步,PCI Host主桥扫描Bus 0上的设备(在一个处理器系统中,一般将Root complex中与Host Bridge相连接的PCI总线命名为PCI Bus 0),系统首先会忽略Bus 0上的embedded EP等不会挂接PCI桥的设备,主桥发现Bridge 1后,将Bridge1 下面的PCI Bus定为 Bus 1,系统将初始化Bridge 1的配置空间,并将该桥的Primary Bus Number 和 Secondary Bus Number寄存器分别设置成0和1,以表明Bridge1 的上游总线是0,下游总线是1,由于还无法确定Bridge1下挂载设备的具体情况,系统先暂时将Subordinate Bus Number设为0xFF。
第 二步,系统开始扫描Bus 1,将会发现Bridge 3,并发现这是一个switch设备。系统将Bridge 3下面的PCI Bus定为Bus 2,并将该桥的Primary Bus Number 和 Secondary Bus Number寄存器分别设置成1和2,和上一步一样暂时把Bridge 3 的Subordinate Bus Number设为0xFF。
第 三步,系统继续扫描Bus 2,将会发现Bridge 4。继续扫描,系统会发现Bridge下面挂载的NVMe SSD设备,系统将Bridge 4下面的PCI Bus定为Bus 3,并将该桥的Primary Bus Number 和 Secondary Bus Number寄存器分别设置成2和3,因为Bus3下面挂的是端点设备(叶子节点),下面不会再有下游总线了,因此Bridge 4的Subordinate Bus Number的值可以确定为3。
第 四步,完成Bus 3的扫描后,系统返回到Bus 2继续扫描,会发现Bridge 5。继续扫描,系统会发现下面挂载的NIC设备,系统将Bridge 5下面的PCI Bus设置为Bus 4,并将该桥的Primary Bus Number 和 Secondary Bus Number寄存器分别设置成2和4,因为NIC同样是端点设备,Bridge 5的Subordinate Bus Number的值可以确定为4。
第 五步,除了Bridge 4和Bridge 5以外,Bus2下面没有其他设备了,因此返回到Bridge 3,Bus 4是找到的挂载在这个Bridge下的最后一个bus号,因此将Bridge 3的Subordinate Bus Number设置为4。Bridge 3的下游设备都已经扫描完毕,继续向上返回到Bridge 1,同样将Bridge 1的Subordinate Bus Number设置为4。
第 六步,系统返回到Bus0继续扫描,会发现Bridge 2,系统将Bridge 2下面的PCI Bus定为Bus 5。并将Bridge 2的Primary Bus Number 和 Secondary Bus Number寄存器分别设置成0和5, Graphics card也是端点设备,因此Bridge 2 的Subordinate Bus Number的值可以确定为5
至此,挂在PCIe总线上的所有设备都被扫描到,枚举过程结束,Host通过这一过程获得了一个完整的PCIe设备拓扑结构。
系统上电以后,host会自动完成上述的设备枚举过程。除一些专有系统外,普通系统只会在开机阶段进行进行设备的扫描,启动成功后(枚举过程结束),即使插入一个PCIe设备,系统也不会再去识别它
在 linux操作系统中,我们可以通过lspci –v -t命令来查询系统上电阶段扫描到的PCIe设备,执行结果会以一个树的形式列出系统中所有的pcie设备。如下图所示,其中黄色方框中的PCIe设备是 北京忆芯科技公司(Bejing Starblaze Technology Co., LTD.)推出的STAR1000系列NVMe SSD主控芯片,图中显示的9d32是Starblaze在PCI-SIG组织的注册码,1000是设备系列号。
STAR1000设备的BDF也可以从上图中找出,其中bus是0x3C,device是0x00,function是0x0,BDF表示为3C:00.0,与之对应的上游端口是00:1d.0。
我 们可以通过“lspci –xxx –s 3C:00.0”命令来列出该设备的PCIe详细信息(技术发烧友或数字控请关注该部分)。这些内容存储在PCIe配置空间,它们描述的是PCIe本身的 特性。如下图所示(低位地址0x00在最左边),可以看到这是一个非易失性存储控制器,0x00起始地址是PCIe的Vendor ID和Device ID。Class code 0x010802表示这是一个NVMe存储设备。0x40是第一组capability的指针,如果你需要查看PCIe的特性,就需要从这个位置开始去查 询,在每组特征的头字段都会给出下一组特性的起始地址。从0x40地址开始依次是power management,MSI中断,链路控制与状态,MSI-X中断等特性组。这儿特别列出了链路特征中的一个0x43字段,表示STAR1000设备是 一个x4lane的链接,支持PCIe Gen3速率(8Gbps)
当然也可以使用lspci –vvv –s 3C:00.0命令来查看设备特性
二. 从pcie角度看包处理
pcie规范遵循开放系统互联网参考模型,自上而下分为事务传输层,数据链路层,物理层。
三. mbuf
Mbuf库提供了申请和释放mbufs的功能,DPDK应用程序使用这些buffer存储消息缓冲。 消息缓冲存储在mempool中
数据结构rte_mbuf可以承载网络数据包buffer或者通用控制消息buffer(由CTRL_MBUF_FLAG指示)。 也可以扩展到其他类型。 rte_mbuf头部结构尽可能小,目前只使用两个缓存行,最常用的字段位于第一个缓存行中
为了存储数据包数据(报价协议头部), 考虑了两种方法:
- 在单个存储buffer中嵌入metadata,后面跟着数据包数据固定大小区域
- 为metadata和报文数据分别使用独立的存储buffer。
第一种方法的优点是他只需要一个操作来分配/释放数据包的整个存储表示。 但是,第二种方法更加灵活,并允许将元数据的分配与报文数据缓冲区的分配完全分离。
DPDK选择了第一种方法。 Metadata包含诸如消息类型,长度,到数据开头的偏移量等控制信息,以及允许缓冲链接的附加mbuf结构指针。
用于承载网络数据包buffer的消息缓冲可以处理需要多个缓冲区来保存完整数据包的情况。 许多通过下一个字段链接在一起的mbuf组成的jumbo帧,就是这种情况。
对于新分配的mbuf,数据开始的区域是buffer之后 RTE_PKTMBUF_HEADROOM 字节的位置,这是缓存对齐的。 Message buffers可以在系统中的不同实体中携带控制信息,报文,事件等。 Message buffers也可以使用起buffer指针来指向其他消息缓冲的数据字段或其他数据结构。

Fig. 6.1 An mbuf with One Segment

Buffer Manager实现了一组相当标准的buffer访问操作来操纵网络数据包。
Buffer Manager 使用 Mempool Library 来申请buffer。 因此确保了数据包头部均衡分布到信道上并进行L3处理。 mbuf中包含一个字段,用于表示它从哪个池中申请出来。 当调用 rte_ctrlmbuf_free(m) 或 rte_pktmbuf_free(m),mbuf被释放到原来的池中。
Packet 及 control mbuf构造函数由API提供。 接口rte_pktmbuf_init() 及 rte_ctrlmbuf_init() 初始化mbuf结构中的某些字段,这些字段一旦创建将不会被用户修改(如mbuf类型、源池、缓冲区起始地址等)。 此函数在池创建时作为rte_mempool_create()函数的回掉函数给出。
分配一个新mbuf需要用户指定从哪个池中申请。 对于任意新分配的mbuf,它包含一个段,长度为0。 缓冲区到数据的偏移量被初始化,以便使得buffer具有一些字节(RTE_PKTMBUF_HEADROOM)的headroom。
释放mbuf意味着将其返回到原始的mempool。 当mbuf的内容存储在一个池中(作为一个空闲的mbuf)时,mbuf的内容不会被修改。 由构造函数初始化的字段不需要在mbuf分配时重新初始化。
当释放包含多个段的数据包mbuf时,他们都被释放,并返回到原始mempool。
这个库提供了一些操作数据包mbuf中的数据的功能。 例如:
- 获取数据长度
- 获取指向数据开始位置的指针
- 数据前插入数据
- 数据之后添加数据
- 删除缓冲区开头的数据(rte_pktmbuf_adj())
- 删除缓冲区末尾的数据(rte_pktmbuf_trim()) 详细信息请参阅 DPDK API Reference
部分信息由网络驱动程序检索并存储在mbuf中使得处理更简单。 例如,VLAN、RSS哈希结果(参见 Poll Mode Driver)及校验和由硬件计算的标志等。
mbuf中还包含数据源端口和报文链中mbuf数目。 对于链接的mbuf,只有链的第一个mbuf存储这个元信息。
例如,对于IEEE1588数据包,RX侧就是这种情况,时间戳机制,VLAN标记和IP校验和计算。 在TX端,应用程序还可以将一些处理委托给硬件。 例如,PKT_TX_IP_CKSUM标志允许卸载IPv4校验和的计算。
以下示例说明如何在vxlan封装的tcp数据包上配置不同的TX卸载:out_eth/out_ip/out_udp/vxlan/in_eth/in_ip/in_tcp/payload
-
计算out_ip的校验和:
mb->l2_len = len(out_eth) mb->l3_len = len(out_ip) mb->ol_flags |= PKT_TX_IPV4 | PKT_TX_IP_CSUM set out_ip checksum to 0 in the packet配置DEV_TX_OFFLOAD_IPV4_CKSUM支持在硬件计算。
-
计算out_ip 和 out_udp的校验和:
mb->l2_len = len(out_eth) mb->l3_len = len(out_ip) mb->ol_flags |= PKT_TX_IPV4 | PKT_TX_IP_CSUM | PKT_TX_UDP_CKSUM set out_ip checksum to 0 in the packet set out_udp checksum to pseudo header using rte_ipv4_phdr_cksum()配置DEV_TX_OFFLOAD_IPV4_CKSUM 和 DEV_TX_OFFLOAD_UDP_CKSUM支持在硬件上计算。
-
计算in_ip的校验和:
mb->l2_len = len(out_eth + out_ip + out_udp + vxlan + in_eth) mb->l3_len = len(in_ip) mb->ol_flags |= PKT_TX_IPV4 | PKT_TX_IP_CSUM set in_ip checksum to 0 in the packet这以情况1类似,但是l2_len不同。 配置DEV_TX_OFFLOAD_IPV4_CKSUM支持硬件计算。 注意,只有外部L4校验和为0时才可以工作。
-
计算in_ip 和 in_tcp的校验和:
mb->l2_len = len(out_eth + out_ip + out_udp + vxlan + in_eth) mb->l3_len = len(in_ip) mb->ol_flags |= PKT_TX_IPV4 | PKT_TX_IP_CSUM | PKT_TX_TCP_CKSUM 在报文中设置in_ip校验和为0 使用rte_ipv4_phdr_cksum()将in_tcp校验和设置为伪头这与情况2类似,但是l2_len不同。 配置DEV_TX_OFFLOAD_IPV4_CKSUM 和 DEV_TX_OFFLOAD_TCP_CKSUM支持硬件实现。 注意,只有外部L4校验和为0才能工作。
-
segment inner TCP:
mb->l2_len = len(out_eth + out_ip + out_udp + vxlan + in_eth) mb->l3_len = len(in_ip) mb->l4_len = len(in_tcp) mb->ol_flags |= PKT_TX_IPV4 | PKT_TX_IP_CKSUM | PKT_TX_TCP_CKSUM | PKT_TX_TCP_SEG; 在报文中设置in_ip校验和为0 将in_tcp校验和设置为伪头部,而不使用IP载荷长度
配置DEV_TX_OFFLOAD_TCP_TSO支持硬件实现。 注意,只有L4校验和为0时才能工作。
-
计算out_ip, in_ip, in_tcp的校验和:
mb->outer_l2_len = len(out_eth) mb->outer_l3_len = len(out_ip) mb->l2_len = len(out_udp + vxlan + in_eth) mb->l3_len = len(in_ip) mb->ol_flags |= PKT_TX_OUTER_IPV4 | PKT_TX_OUTER_IP_CKSUM | PKT_TX_IP_CKSUM | PKT_TX_TCP_CKSUM; 设置 out_ip 校验和为0 设置 in_ip 校验和为0 使用rte_ipv4_phdr_cksum()设置in_tcp校验和为伪头部配置DEV_TX_OFFLOAD_IPV4_CKSUM, DEV_TX_OFFLOAD_UDP_CKSUM 和 DEV_TX_OFFLOAD_OUTER_IPV4_CKSUM支持硬件实现。
Flage标记的意义在mbuf API文档(rte_mbuf.h)中有详细描述。 更多详细信息还可以参阅testpmd 源码(特别是csumonly.c)。
直接缓冲区是指缓冲区完全独立。 间接缓冲区的行为类似于直接缓冲区,但缓冲区的指针和数据便宜量指的是另一个直接缓冲区的数据。 这在数据包需要复制或分段的情况下是很有用的,因为间接缓冲区提供跨越多个缓冲区重用相同数据包数据的手段。
当使用接口 rte_pktmbuf_attach() 函数将缓冲区附加到直接缓冲区时,该缓冲区变成间接缓冲区。 每个缓冲区有一个引用计数器字段,每当直接缓冲区附加一个间接缓冲区时,直接缓冲区上的应用计数器递增。 类似的,每当间接缓冲区被分裂时,直接缓冲区上的引用计数器递减。 如果生成的引用计数器为0,则直接缓冲区将被释放,因为它不再使用。
处理间接缓冲区时需要注意几件事情。 首先,间接缓冲区从不附加到另一个间接缓冲区。 尝试将缓冲区A附加到间接缓冲区B(且B附加到C上了),将使得rte_pktmbuf_attach() 自动将A附加到C上。 其次,为了使缓冲区变成间接缓冲区,其引用计数必须等于1,也就是说它不能被另一个间接缓冲区引用。 最后,不可能将间接缓冲区重新链接到直接缓冲区(除非它已经被分离了)。
虽然可以使用推荐的rte_pktmbuf_attach()和rte_pktmbuf_detach()函数直接调用附加/分离操作, 但建议使用更高级的rte_pktmbuf_clone()函数,该函数负责间接缓冲区的正确初始化,并可以克隆具有多个段的缓冲区。
由于间接缓冲区不应该实际保存任何数据,间接缓冲区的内存池应配置为指示减少的内存消耗。 可以在几个示例应用程序中找到用于间接缓冲区的内存池(以及间接缓冲区的用例示例)的初始化示例,例如IPv4组播示例应用程序。
以上是关于DPDK PCIe 与 包处理的主要内容,如果未能解决你的问题,请参考以下文章