hadoop功能模块之hdfs
Posted zhangxiaofan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop功能模块之hdfs相关的知识,希望对你有一定的参考价值。
第一节:hdfs简介
用于海量数据存储的,就是一个文件系统,分布式文件系统。
hadoop distributed filesystem
第二节:设计思想
一、分而治之
将超级大的文件切分成每一个小文件(数据块)进行存储在不同的节点上。同时切分的数据块太大了,容易造成集群中节点的存储的负载不均衡。太小了会造成一个文件切分过多的块会造成namenode的压力过大。
hdfs进行文件存储的时候将文件进行切块,默认的一个块大小128M。
hadoop2中默认的每一个块的大小为128M;
hadoop1中默认的每一个块的大小64M;
hadoop3中每一个块默认大小为256M。

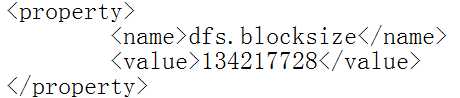
二、 冗余数据
1、简介
解决数据丢失的问题,hadoop基于普通廉价机的。用空间换取数据安全,在hdfs中每一个数据块都会进行备份存储。默认的情况下每一个数据块存储3份。

目前我们集群中配置的每一个数据块存储2个副本。这里的副本不是备份的意思,代表的是总存储份数,这里的副本每一个副本都是同等地位的,没有优先级,多个副本数据相互互为副本的,对外提供服务的时候谁有时间谁提供。
2、注意
(1)一个节点上可以存储多个数据块的,一个数据块只能存储在一个节点上。但是同一个节点的多个数据块中肯定没有相同的,同一个数据块的多个副本 不可能存储在一个节点的,不同的副本存储在不同的节点。
(2)真实副本<设置值
假设集群3个节点,副本配置2个,有一个块的一个副本的节点宕机了,会造成这个块的副本数低于配置的值,这个时候会复制出来这个块的一个副本存储在另一个节点上。
(3)集群节点<副本
集群节点3个,副本 4个。会存储3份,另外与一份 namenode会进行记账,当集群中的添加节点的时候将这个欠的副本复制出来。
(3)真实副本>设置
集群中某一个节点宕机,这个节点上存储的所有的副本都会复制一份出来 过了一段时间 这个节点活了,造成这个节点上存储的数据块的副本多了,真实的副本大于设置的副本个数,等待1h左右删除多余的副本。
第三节:hdfs的架构
一、简介
主从架构,一主多从的架构。
二、namenode(主节点)
1、存储元数据信息
(1)简介
元数据:描述数据的数据,用于描述原始数据的数据。
这里的元数据指的是描述datanode上的存储的真实的数据的数据,datanode上存储数据的块的对应关系。
存储路径:

元数据存储路径namenode节点的
/home/hadoop/data/hadoopdata/name/current 其中fsimage是核心元数据信息。namenode记录的元数据包括:抽象目录树、目录树中的文件和数据块的对应关系、数据块和节点的对应关系数据块存储位置。
(2)抽象目录树
通过目录树查看文件系统中存储的文件目录结构的。目录树是从/开始的目录结构。目录树不属于任何一个具体节点,是抽象的一个目录。例如:目前集群中3个从节点/指的是3个从节点共同组成的一个存储系统的抽象的/目录。
注意:目录树上显示的是存储文件,即判断是否有这个文件,具体的被切分完的数据块的存储位置在目录树上是没有显示的。
例子:/jdk-8u73-linux-x64.tar.gz 180M
(3)目录树中的文件和数据块的对应关系
/jdk-8u73-linux-x64.tar.gz 180M
0-128M blk_1073741825
129-180M blk_1073741826
注意:hadoop集群中每一个数据块都会有一个唯一编号全局唯一的
(4)数据块和节点的对应关系数据块存储位置
/jdk-8u73-linux-x64.tar.gz 180M
0-128M blk_1073741825 [hdp03 hdp01]
129-180M blk_1073741826 [hdp03 hdp01]
2、接受客户端的读写请求
客户端的所有的读写请求先经过namenode
三、datanode(从节点)
1、数据存储
数据块的存储目录:

数据块的存储目录
/home/hadoop/data/hadoopdata/data
current 核心数据
in_use.lock 锁文件
current目录下:
BP-1453129122-192.168.191.201-1556592207649 块池文件夹 存储namenode管理的所有数据块信息的,VERSION 版本信息。
数据块的存储目录:
/home/hadoop/data/hadoopdata/data/current/BP-1453129122-192.168.191.201-1556592207649/current/finalized/subdir0/subdir0
blk_1073741825
blk_1073741826 真实数据块
blk_1073741825_1001.meta
blk_1073741826_1002.meta 数据块的元数据信息用于数据校验的校验数据块的完整性的。
2、负责客户读写请求
四、secondarynamenode(助理)
1、帮助namenode备份元数据
防止namenode元数据丢失,namenode的冷备份节点namenode元数据损坏或丢失的时候可以通过 secondarynamenode进行恢复的。
2、减轻namenode的压力
帮助namenode做一些工作
帮助namenode进行元数据合并
第四节:hdfs的优缺点
一、缺点
1、延时性高
不适合实时读取
2、不适合存储大量的小文件
(1)不划算:寻址时间远远大于读取数据的时间
(2)会造成namenode的压力很大,一条元数据信息有150byte,一个数据块就有一条元数据。
3、不支持文件修改支持文件追加
一次写入多次读取
修改的成本太高,首先需要先确定修改的数据所属的数据块id 在进行修改所有的对应的数据块的副本,hdfs干脆关闭了修改的功能。
虽然支持文件追加,不建议使用。(可以利用>>)
二、优点
1、成本低
基于普通廉价机
2、高扩展性
集群的从节点,可以无限横向扩展,原则没有上线
3、高容错性
副本机制,保证数据的安全性,只要所有副本不同时宕机,就能访问数据。当副本个数=节点个数时数据安全性,容错机制最好。
用空间来换取数据安全。
4、高可用性
hadoop2 namenode的高可用方案
集群可以7*24 服务
5、适合批处理
大数据处理
以上是关于hadoop功能模块之hdfs的主要内容,如果未能解决你的问题,请参考以下文章