数据之路 - Python爬虫 - Scrapy框架
Posted iceredtea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据之路 - Python爬虫 - Scrapy框架相关的知识,希望对你有一定的参考价值。
一、Scrapy框架入门
1.Scrapy框架介绍
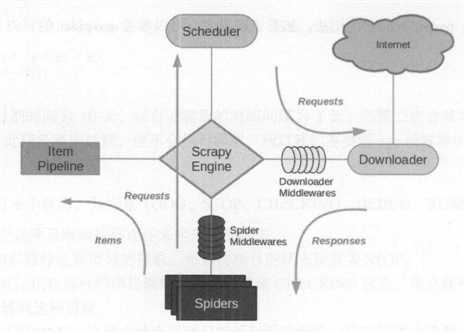
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,其架构清晰,榄块之间的榈合程度低,可扩展性极强,可以灵活完成各种需求。
-
Engine:引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
-
Item:项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
-
Scheduler:调度器,接受引擎发过来的请求并将其加入队列中, 在引擎再次请求的时候将请求提供给引擎。
-
Downloader:下载器,下载网页内容,并将网页内容返回给蜘蛛。
-
Spiders:蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
-
Item Pipeline:项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
-
Downloader Middlewares:下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
-
Spider Middlewares:蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
2.数据流
Scrapy中的数据流由引擎控制,数据流的过程如下:
-
Engine首先打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL。
-
Engine从Spider中获取到第一个要爬取的URL,并通过Scheduler以Request 的形式调度。
-
Engine向Scheduler请求下一个要爬取的URL。
-
Scheduler返回下一个要爬取的URL给Engine, Engine将URL通过DownloaderMiddJewares转发给Downloader下载。
-
一旦页面下载完毕,Downloader生成该页面的Response,并将其通过DownloaderMiddlewares发送给Engine。
-
Engine从下载器中接收到l Response,并将其通过SpiderMiddlewares发送给Spider处理。
-
Spider处理Response,并返回爬取到的Item及新的Request给Engine。
-
Engine将Spider返回的Item给ItemPipeline,将新的Request给Scheduler。
-
重复第 2 步到第 8 步,直到Scheduler中没有更多的Request, Engine关闭该网站,爬取结束。
3.Scrapy入门
- 创建项目
# 项目文件可以直接用scrapy命令生成 scrapy startproject tutorial # Scrapy部署时的配置文件 scrapy.cfg # 项目的模块, 需要从这里引入 tutorial __init__.py # Items的定义,定义爬取的数据结构 items.py # Middlewares的定义,定义爬取时的中间件 middlewares.py # Pipelines的定义,定义数据管道 pipelines.py # 配置文件 settings.py # 放置Spiders的文件夹 spiders __init__.py
- 创建Spider
- 创建item
- 解析Response
- 使用
以上是关于数据之路 - Python爬虫 - Scrapy框架的主要内容,如果未能解决你的问题,请参考以下文章