java扒取网页,获取所需要内容列表展示
Posted irishua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java扒取网页,获取所需要内容列表展示相关的知识,希望对你有一定的参考价值。
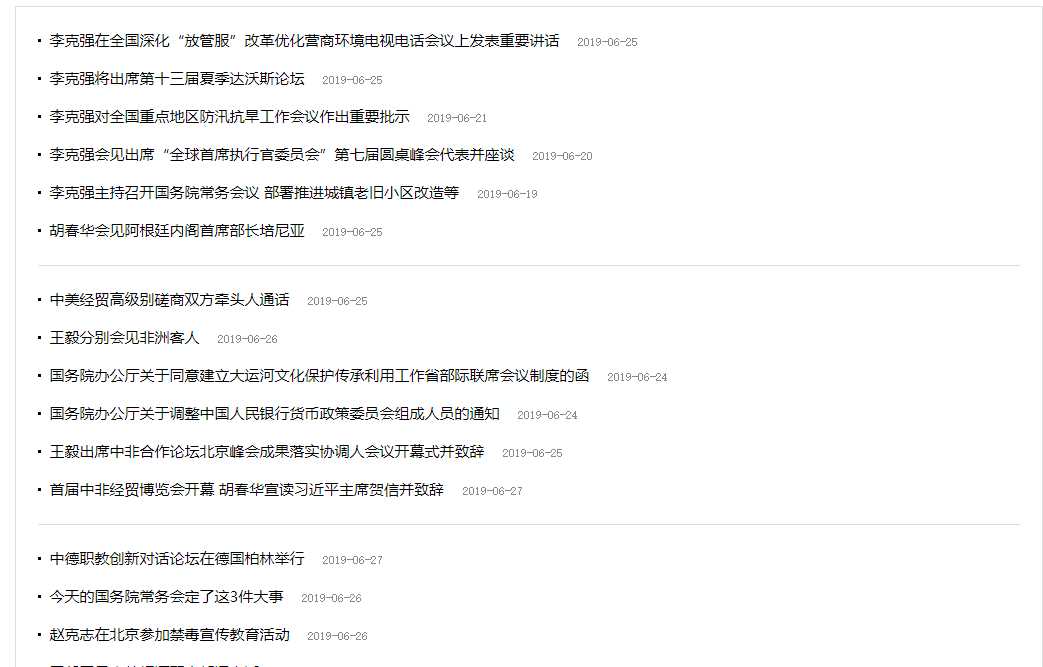
1.扒取原网页内容:
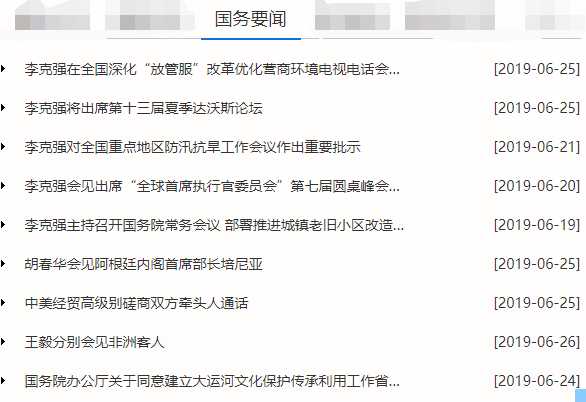
2.本地展示效果
3.代码
3 @ResponseBody 4 public Map<String, Object> findGuoWuYaoWen(HttpServletRequest request, ModelMap model, String area,String city) 5 Map<String, Object> map = new HashMap<String, Object>(); 6 Map<String, Object> result = new HashMap<String, Object>(); 7 List<NationalNews> nationalList = new ArrayList<>(); 8 String title,newsUrl,time; 9 10 Elements elements = getUrlElements(); 11 System.out.println("========================"+elements.toString()); 12 List<Element> subList = elements.subList(0, 9); 13 for (Element element : subList) 14 String title123 = element.text(); 15 title =title123.substring(0, title123.length()-10) ; 16 newsUrl = element.select("a").attr("href"); 17 if(!newsUrl.contains("www")) 18 newsUrl="http://www.gov.cn"+newsUrl; 19 20 time = title123.substring(title123.length()-10,title123.length()); 21 22 NationalNews nationalNews = new NationalNews(title, newsUrl, time); 23 24 System.out.println(title+"=========================="+newsUrl+"=========================="+time); 25 26 nationalList.add(nationalNews); 27 28 result.put("dataList", nationalList); 29 return result; 30
1 private Elements getUrlElements() 2 System.out.println("=======================================抓取国家政府网内容任务开始了======================================="); 3 String url = "http://www.gov.cn/pushinfo/v150203/index.htm"; 4 CloseableHttpClient httpClient = HttpClients.createDefault(); 5 Elements elementsByTag = null; 6 7 try 8 HttpGet httpGet = new HttpGet(url); 9 CloseableHttpResponse response = httpClient.execute(httpGet); 10 try 11 HttpEntity entity = response.getEntity(); 12 //设置编码格式否则乱码 13 String html = new String(EntityUtils.toString(entity).getBytes("iso8859-1")); 14 15 Document document = Jsoup.parse(html); 16 elementsByTag = document.getElementsByTag("li"); 17 finally 18 response.close(); 19 20 catch (ClientProtocolException e1) 21 e1.printStackTrace(); 22 catch (IOException e1) 23 e1.printStackTrace(); 24 finally 25 // 关闭连接,释放资源 26 try 27 httpClient.close(); 28 catch (IOException e) 29 e.printStackTrace(); 30 31 32 33 return elementsByTag; 34
以上是关于java扒取网页,获取所需要内容列表展示的主要内容,如果未能解决你的问题,请参考以下文章