Spark(五十二):Spark Scheduler模块之DAGScheduler流程
Posted yy3b2007com
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark(五十二):Spark Scheduler模块之DAGScheduler流程相关的知识,希望对你有一定的参考价值。
导入
从一个Job运行过程中来看DAGScheduler是运行在Driver端的,其工作流程如下图:
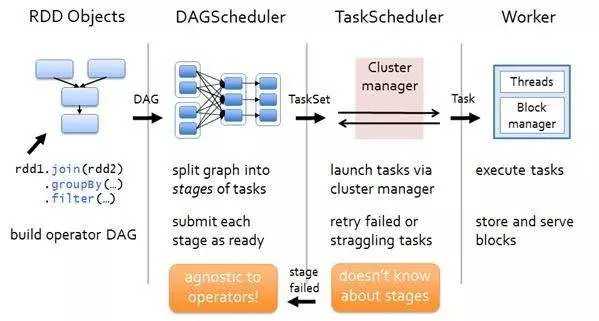
图中涉及到的词汇概念:
1. RDD——Resillient Distributed Dataset 弹性分布式数据集。
2. Operation——作用于RDD的各种操作分为transformation和action。
3. Job——作业,一个JOB包含多个RDD及作用于相应RDD上的各种operation。
4. Stage——一个作业分为多个阶段。
5. Partition——数据分区, 一个RDD中的数据可以分成多个不同的区。
6. DAG——Directed Acycle graph,有向无环图,反应RDD之间的依赖关系。
7. Narrow dependency——窄依赖,子RDD依赖于父RDD中固定的data partition。
8. Wide Dependency——宽依赖,子RDD对父RDD中的所有data partition都有依赖。
9. Caching Managenment——缓存管理,对RDD的中间计算结果进行缓存管理以加快整体的处理速度。
在Driver端,运行一个job时,涉及到DAGSheduler的流程如下:
1)调用applicaiton_jar.jar(应用程序入口函数),应用程序的运行过程依赖SparkContext,且需要初始化SparkContext sc,通过sc就可以创建RDD了(因为RDD是调用sc来创建的);
2)初始化SparkContext过程中会初始化DAGScheduler,并调用SparkContext.createTaskScheduler(this, master, deployMode)来初始化TaskScheduler、ShedulerBackend;
3)应用程序实际上是执行的RDD的transform或者action函数,当RDD#action函数触发时,实际上这样的action函数内部会调用sc.submitJob(...)方法,在SparkContext#submitJob(...)方法内部会根据action创建ResultStage,并找到其依赖的所有ShuffleMapStage。stage之间按照顺序执行,待前一个stage执行完成成功,才能执行下一个stage,所有stage执行成功后,该job才算执行完成。
4)stage实际上可以看作为TaskSet,它实际上代表的就是一个独立的Task集合,DAGScheduler将调用TaskScheduler来对TaskSet进行作业调度;
5)TaskScheduler调度过程是将task序列化通过RPC传递给Executor,Executor上会使用TaskRunner来运行task;
6)TaskScheduler上task如果运行失败,TaskScheduler会重试处理;同样在stage失败后,DAGScheduler也会触发stage重试处理。需要注意:这里如果stage失败,对当前stage重算,而不是从上一个stage开始,这样也是DAG划分stage的原因。
DAGScheduler源码分析
DAGScheduler功能:
1)最高层的调度层,实现了stage-oriented(面向阶段)调度。DAGScheduler为每个作业计算出一个描述stages的DAG,跟踪哪些RDD和stage输出实现,并找到运行作业的最小计划。然后,它将stages封装为TaskSets提交给在集群上运行它们的底层TaskScheduler实现(TaskScheduler唯一实现类是TaskSchedulerImpl)。任务集包含完全独立的一组任务,这些任务可以根据群集中已经存在的数据(例如,前几个阶段的映射输出文件)立即运行,但如果此数据不可用,它可能会失败。
2)Spark stages 是将RDD图在Shuffle边界处断开来创建的。具有“窄(narrow)”依赖关系的RDD操作(如map()和filter())在每个阶段中被流水线连接到一组任务中,但是具有shuffle依赖关系的操作需要多个阶段(一个阶段写入一组映射输出文件,另一个阶段在屏障后读取这些文件)。最后,每个阶段将只具有对其他阶段的shuffle依赖,并且可以在其中计算多个操作。这些操作的实际管道化发生在各种RDD的rdd.compute()函数中。
3)除了划分stages的DAG之外,DAGScheduler还根据当前缓存状态确定运行每个task的首选位置,并将这些位置传递给底层TaskScheduler(任务调度器)。此外,它还处理由于shuffle输出文件丢失而导致的故障,在这种情况下,可能需要重新提交旧stages。在内部TaskScheduler会处理stage中不是由shuffle文件丢失引起的失败,它会在取消整个stage之前对每个任务重试几次。
4)要从故障中恢复,同一阶段可能需要多次运行,这称为“attempts”。如果 TaskScheduler 报告某个任务由于前一阶段的映射输出文件丢失而失败,则DAGScheduler将重新提交该丢失的阶段。这是通过具有FetchFailed的CompletionEvent或ExecutorLost事件检测到的。DAGScheduler将等待一小段时间来查看其他节点或任务是否失败,然后为计算丢失任务的任何丢失阶段重新提交TaskSets(任务集)。作为这个过程的一部分,我们可能还必须为以前清理stage objects的旧(已完成)stage创建stage objects。由于stage的旧“attempts”中的任务可能仍在运行,因此必须小心映射在正确的stage对象中接收到的任何事件。
查看此代码时,有几个关键概念:
-Jobs:(由[ActiveJob]表示)是提交给调度程序的顶级工作项。例如,当用户调用诸如count()之类的操作时,作业将通过sc.submitJob()方法提交。每个作业可能需要执行多个阶段来构建中间数据。
-Stages:Stage是一组任务(TaskSet),用于计算作业中的中间结果,其中每个任务在同一个RDD的分区上计算相同的函数。
Stage在shuffle边界处分离,这会引入一个屏障(我们必须等待上一阶段完成获取输出)。
有两种类型的Stage(阶段):【ResultStage】(对于执行操作的最后阶段);【ShuffleMapStage】(为shuffle写入映射输出文件)。
如果这些作业重用同一个RDD,则Stage(阶段)通常在多个作业之间共享。
-Tasks:是单独的工作单元,每个工作单元发送到一台机器。
-Cache tracking: DagScheduler会找出缓存哪些RDD以避免重新计算它们,同样会记住哪些shuffle map stage已经生成了输出文件,以避免重复shuffle的映射端。
-Preferred locations:DAGScheduler还根据其底层RDD的首选位置,或缓存或无序处理数据的位置,计算在阶段中运行每个任务的位置。
-Cleanup:当依赖于它们的正在运行的作业完成时,所有数据结构都会被清除,以防止长时间运行的应用程序中发生内存泄漏。
DAGScheduler的生命周期
那么下边将会结合代码对DAGScheduler整个生命周期进行介绍,DAGScheduler的生命周期:
1)初始化DAGScheduler
2)根据RDD DAG划分Stages
3)对Stage进行调度、Stage容错
4)实例销毁
1)DAGScheduler之初始化
2)DAGScheduler之根据RDD DAG划分Stages
3)DAGScheduler之对Stage进行调度、容错
4)DAGScheduler之实例销毁
参考:
1)《Spark运行机制之DAG原理》
2)《Spark Scheduler模块详解-DAGScheduler实现》
以上是关于Spark(五十二):Spark Scheduler模块之DAGScheduler流程的主要内容,如果未能解决你的问题,请参考以下文章