orderby工作原理 + 最小代价取随机数
Posted jimmyhe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了orderby工作原理 + 最小代价取随机数相关的知识,希望对你有一定的参考价值。
orderby是如何工作的
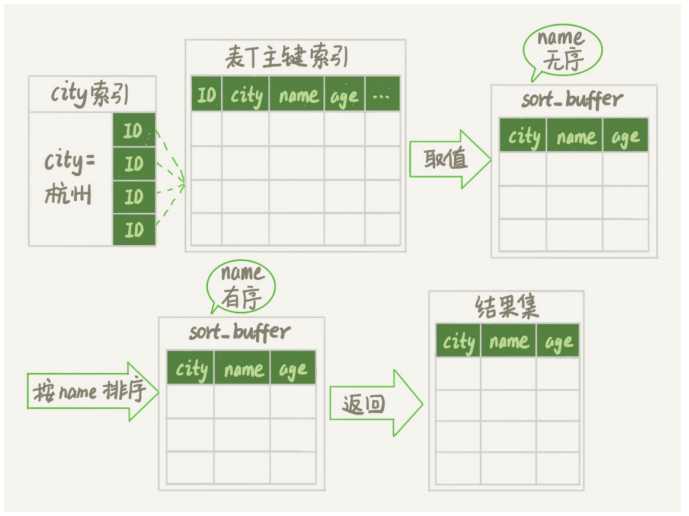
- 场景例子:假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回 前1000个人的姓名、年龄。
- 表结构:

? SQL语句:select city,name,age from t where city="杭州" order by name limit 1000;
全字段排序

- Extra字段中Using filesort表示需要排序,mysql会给每个线程分配一块内存用于排序
执行流程
初始化sort_buffffer,确定放入name、city、age这三个字段;
从索引city找到第一个满足city=‘杭州’条件的主键id
到主键id索引取出整行,取name、city、age三个字段的值,存入sort_buffffer中;
从索引city取下一个记录的主键id;
重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
对sort_buffffer中的数据按照字段name做快速排序;
按照排序结果取前1000行返回给客户端。
sort_buffffer_size,就是MySQL为排序开辟的内存(sort_buffffer)的大小。如果要排序的数据量 小于sort_buffffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不 利用磁盘临时文件辅助排序。
这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么sort_buffffer里面 要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。 所以如果单行很大,这个方法效率不够好。
rowid
- max_length_for_sort_data,是MySQL中专门控制用于排序的行数据的长度的一个参数。
city、name、age 这三个字段的定义总长度是36,我把max_length_for_sort_data设置为16, 我们再来看看计算过程有什么改变。
新的算法放入sort_buffffer的字段,只有要排序的列(即name字段)和主键id。但这时,排序的结果就因为少了city和age字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
初始化sort_buffffer,确定放入两个字段,即name和id;
从索引city找到第一个满足city=‘杭州’条件的主键id,也就是图中的ID_X;
到主键id索引取出整行,取name、id这两个字段,存入sort_buffffer中;
从索引city取下一个记录的主键id;
重复步骤3、4直到不满足city=‘杭州’条件为止,也就是图中的ID_Y;
对sort_buffffer中的数据按照字段name进行排序;
遍历排序结果,取前1000行,并按照id的值回到原表中取出city、name和age三个字段返回 给客户端。
实际上MySQL服务端从排序后的sort_buffffer 中依次取出id,然后到原表查到city、name和age这三个字段的结果,不需要在服务端再耗费内 存存储结果,是直接返回给客户端的。
全字段排序 VS rowid排序结论
如果MySQL实在是担心排序内存太小,会影响排序效率,才会采用rowid排序算法,这样排序过 程中一次可以排序更多行,但是需要再回到原表去取数据。
如果MySQL认为内存足够大,会优先选择全字段排序,把需要的字段都放到sort_buffffer中,这 样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了MySQL的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。 对于InnoDB表来说,rowid排序会要求回表多造成磁盘读,因此不会被优先选择。
你可以设想下,如果能够保证从city这个索引上取出来的行,天然就是按照name递增排序的话, 是不是就可以不用再排序了呢?
所以,我们可以在这个市民表上创建一个city和name的联合索引
在这个索引里面,我们依然可以用树搜索的方式定位到第一个满足city=‘杭州’的记录,并且额外 确保了,接下来按顺序取“下一条记录”的遍历过程中,只要city的值是杭州,name的值一定是有序的。
从索引(city,name)找到第一个满足city=‘杭州’条件的主键id;
到主键id索引取出整行,取name、city、age三个字段的值,作为结果集的一部分直接返 回;
- 从索引(city,name)取下一个记录主键id;
重复步骤2、3,直到查到第1000条记录,或者是不满足city=‘杭州’条件时循环结束。
- 这个查询过程不需要临时表,也不需要排序。
最小代价取随机数
场景例子:某个英语学习app,每次用户打开都会取随机3个单词。
表结构,假设有10000条数据。

内存临时表
- 用sql语句:select word from words order by rand() limit 3;

- extra字段中显示不仅需要临时表还需要执行排序,即表示需要在临时表上排序。
- 对于innodb表来说,会执行全字段排序来减少磁盘访问,优先选择,对于内存表来说,仅仅是简单的根据数据行的位置没直接访问内存得到数据,用于排序的行越少越好,所以mysql会选择rowid排序。
- 以上这条语句这姓流程如下:
- 创建一个临时表,使用的是memory引擎,第一个字段是double,暂记为字段R,第二个字段是varchar,记为字段W,并且此表无索引。
- 从words表中,按主键顺序取出所有的word值,对于每一个word值,调用rand()函数生成一个大于0或小于1的随机小数,并且把随机小数和word分别存入临时表字段R和W中,到此扫描行10000.
- 在临时表的10000行数据上按照字段R排序
- 初始化sort_buffer(用来排序的内存空间),有两个字段,一个是double类型,一个是整型。
- 从内存表逐行的取出R值和位置信息,分别存入sort_buffer这两个字段里,这个过程要对临时表做全表扫描,此时扫描10000
- 在sortbuffer中根据R值进行排序,这个过程不涉及表的操作,不增加扫描行
- 排序完成后,取前三个位置信息,依次到内存临时表取word值,返回给客户端,访问了3行数据,总扫描行20003
- 每个引擎唯一标识数据行的信息:rowid,6字节。对于有主键地表来说就是主键id,对于没主键的表就是系统生成的。
- 用sql语句:select word from words order by rand() limit 3;
磁盘临时表
- tmp_table_size限制了内存临时表的大小,默认16M,如果临时表大小超过了这个数值,就会转化成磁盘临时表。
对于select word from words order by rand() limit 3语句,其实没有用到临时文件,而是使用优先队列排序算法,只取前3,后面的顺序并不管,节省了很多计算量。
即使如此也需要扫描20003行数据,有什么办法可以随机排序呢?
- 取得整个表的行数记为C,扫描了C行
- 取Y=floor(c*rand()),floor表示取整
- 再用limit Y,1
整个语句扫描了C+Y+1行,代价要小于order by rand()
以上是关于orderby工作原理 + 最小代价取随机数的主要内容,如果未能解决你的问题,请参考以下文章