[python][pandas]DataFrame的基本操作
Posted wildkid1024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[python][pandas]DataFrame的基本操作相关的知识,希望对你有一定的参考价值。
问题来源
在实验中经常需要将数据保存到易于查看的文件当中,由于大部分都是vector数据,所以选择pandas的dataframe来保存到csv文件是最简单的方法。
基本操作
下图是DataFrame的一些基本概念,可以看出与基本的csv结构是保持一致的。
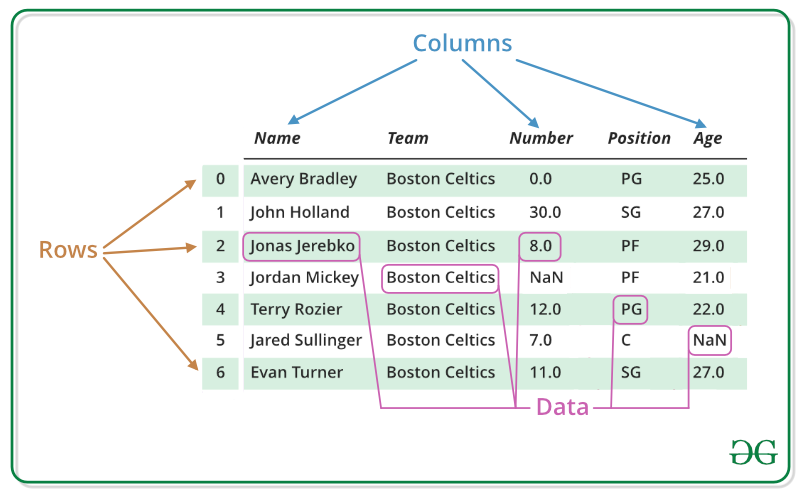
1. 创建DataFrame
创建DataFrame通常有两种方法,从list中创建和从dict中创建:
从dict创建,key的名字会作为名,如下所示:
>>> d = 'col1': [1, 2], 'col2': [3, 4] >>> df = pd.DataFrame(data=d) >>> df col1 col2 0 1 3 1 2 4从list创建, 列名会以[0,n]来显示:
>>> d = [2, 3, 4, 5] >>> df = pd.DataFrame(data=d) >>> df 0 0 2 1 3 2 4 3 5当然也可以指定列名:
>>> df2 = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), ... columns=['a', 'b', 'c']) >>> df2 a b c 0 1 2 3 1 4 5 6 2 7 8 9
note:对于不带小数点的数字,df默认的datatype为int64,如果需要修改datatype,那么需要在创建的时候声明datatype:
>>> df = pd.DataFrame(data=d, dtype=np.int8)2. 行列选择
行列查找,可以分为单行/列查找和多行/列查找,思路都一样。
单/多行查找是通过loc函数进行查找的,例子如下:
>>> data = pd.read_csv("nba.csv", index_col ="Name")
>>> data.loc["Avery Bradley"]) # 查找一行
>>> data.loc[["Avery Bradley","R.J. Hunter"]] #查找多行需要注意的是,先对数据进行索引,默认的索引为[0,n]。
单/多列的查找更简单一些,可以直接使用下标的方式来进行查找,猜测在df内部存储的方式是以列优先的。例子如下:
>>> data = 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']
>>> df = pd.DataFrame(data)
>>> df['Name'] # 查找为Name一列的所有数据
>>> df[['Name','Address']] #查找Name和Address的数据通过索引下标查找,通过数组下标来查找,可以通过iloc方法来查找,例子如下:
>>> data = pd.read_csv("nba.csv", index_col ="Name")
>>> row2 = data.iloc[3] # 查找第4行
>>> row2 = data.iloc [[3, 5, 7]] # 查找多行查找分块矩阵也类似于上诉的方法,例子如下:
>>> data = pd.read_csv("nba.csv", index_col ="Name")
>>> row2 = data.iloc[[3, 4], [1, 2]]
>>> row2 = data.iloc [:, [1, 2]]3. 调整行号
如果是使用dict生成的df,那么其对应的列的顺序是按照字母序进行排列的,这时需要进行按添加顺序进行排序。可以通过以下方式调整顺序:
>>> data = 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']
>>> df = pd.DataFrame(data)
>>> df = df[['Name','Age','Address','Qualification']]当然还有一些需求,比如需要修改行的编号,修改行号为日期,那么可以使用下面的方法:
>>> df = pd.DataFrame(data)
>>> df.index = df.index + 1 #行号从1开始
>>> df.index = pd.date_range('20190101',periods=len(df)) #行号为日期引用
[1]. https://www.geeksforgeeks.org/python-pandas-dataframe/
[2]. https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
以上是关于[python][pandas]DataFrame的基本操作的主要内容,如果未能解决你的问题,请参考以下文章