OpenStack RPC框架浅析
Posted luohaixian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenStack RPC框架浅析相关的知识,希望对你有一定的参考价值。
1 消息队列Rabbitmq介绍
Rabbitmq的整体架构图
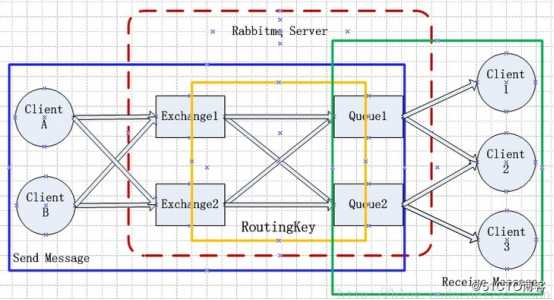
(1)Rabbitmq Server:中间那部分就是Rabbitmq Server,也叫broken server,主要是负责消息的传递,保证client A、B发送的消息Cleint 1、2、3能够正确的接收到。
(2)Client A、B:在消息队列里我们称之为生产者-Producer,发送消息的客户端。
(3)Client 1、2、3:在消息队列里我们称之为消费者-Consume,接收消息的客户端。
(4)Exchange:我们可以称之为消息队列的路由,根据发送的消息的routing key来转发到对应的队列上。有四种类型的Exchange,对应四种不同的转发策略:
direct Exchange:完全匹配,比如routing key是abc,就对应binding key为abc对应的queue。
topic Exchange:正则匹配,比如routing key是ab*,可以用来匹配binding key为abc或abd等的queue。
fanout Exchange:广播策略,忽略掉routing key,转发给所有绑定在这个Exchange的queue。
headers Exchange:不依赖于routing key,会根据发送的消息的内容的headers属性来进行匹配。
(5)Queue:队列,消息存放的地方。
(6)Connection (连接)和 Channel (通道):生产者和消费者需要和 RabbitMQ 建立 TCP 连接。一些应用需要多个connection,为了节省TCP 连接,可以使用 Channel,它可以被认为是一种轻型的共享 TCP 连接的连接。连接需要用户认证,并且支持 TLS (SSL)。连接需要显式关闭。
(7)vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离
(8)Message(消息):在通道上传输的二进制对象,结构为Headers(头)、Properties (属性)和 Data (数据)。
以下是消息的几个重要属性:
routing key:Exchange根据该key来转发消息到对应的队列中
delivery_mode:消息模式,有持久模式和非持久模式,持久模式则是将消息保存到磁盘中,非持久模式则是消息保存在内存中
reply_to:RPC调用时处理结果返回需传送到的队列名,称为回调队列
correlation_id:RPC调用返回时需要用到的参数,一个请求id
content_type:这个编码类型是给生产者和消费者使用的,rabbitmq只是按原样传输的
对应到OpenStack的平台则是:
Client端的生产者可以是nova-api,nova-conductor等,以虚拟机开机为例,则nova-api是生产者,nova-api收到一个http请求,产生一个开机消息,exchange是’nova’,发送的队列名compute.hostname,routing key为队列名,然后发送到Rabbitmq Server上去,消息队列服务保存到对应的队列上,然后将消息派发给消费者。因为消费者跟rabbitmq服务是建立了一条channel连接的,所以派发消息就相当于是通过这条channel传送数据。
消费者则对应是nova-compute,nova-compute接收到消息后进行解析,然后调用对应的函数进行处理,然后将处理结果返回。
2 Rabbitmq集群模式
Rabbitmq集群工作原理图:
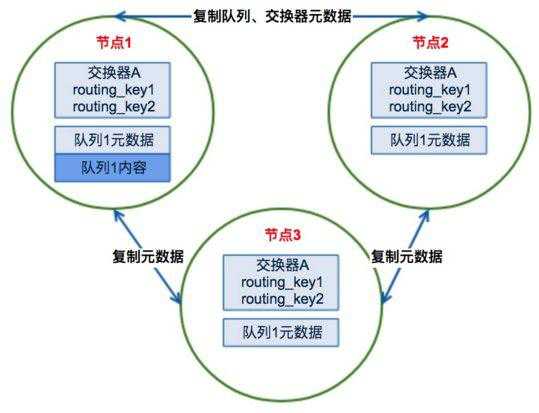
Rabbitmq是用Erlang语言写的,该语言天生有分布式特性,本身支持原生的HA模式。
普通的消息队列集群会始终同步四种类型的内部元数据:
(1)队列元数据:队列名称和它的属性
(2)交换器元数据:交换器名称、类型和属性
(3)绑定(binding)元数据:一张简单的表格展示如何将消息路由到对应的队列
(4)Vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性
但普通模式并没有对消息队列的消息进行同步,需要设置成镜像模式,才会对消息进行同步。
2.1 同步原理
通过镜像模式,Rabbitmq会将镜像队列放置于多个消息队列服务节点上,消息的生产和消费都会在节点间进行同步,镜像队列包含一个master和多个slave,当master退出时,时间最长的则升为master。
每个消息队列进程会创建一个gm(guaranteed multicast)进程,镜像队列中的所有gm进程会组成一个gm进程组用于广播和接收消息。Gm组将集群中的节点组成一个环,主节点收到或处理完一个消息都会发起消息同步,消息沿着环形链走,当主节点接收到自己发的消息后则表示消息已经同步到所有的节点。
消息的发布和消费都是通过 master 队列完成,master 队列对消息进行处理同时将消息的处理动作通过 gm 广播给所有 slave 队列。
2.2 消息走向路径
以开机一个虚拟机为例,环境状况:244的nova-api对245上的虚拟机进行关机操作,245的compute.hostname的主队列在242上
nova-api会将消息发到给主队列242上的消息队列服务器保存,242进行gm广播,242通过channel将消息传送到245上,245接收到消息进行处理
2.3 消息确认机制
程序中是在拿到消息后和开始处理前期间进行了message.acknowledge()的调用,调用后即是告诉消息队列服务,该消息已经被处理完了,可以进行删除了。
从实践来看确实是acknowledge调用了后才删除的,但程序是实际调用后才开始执行消息处理函数,期间如果有异常报错没有处理成功则也不会重新处理了。
Openstack平台没有对no_ack进行设置,查看kombu的代码默认no_ack是false的,也就是需要进行确认才会删除消息。
也可以发送nack的方式表示消息处理有问题,这时如果队列的requeue设置为true,则会重新进入队列交由其它消费者进行处理,默认是为false。
dead lettering机制:当调用了reject或nack且requeue是false时或者消息过期时,该机制会将失败的消息放入到dead-lettered队列中。
3 OpenStack RPC框架
3.1 接收消息(以nova-compute服务为例)
云平台消息队列RPC处理框架图:
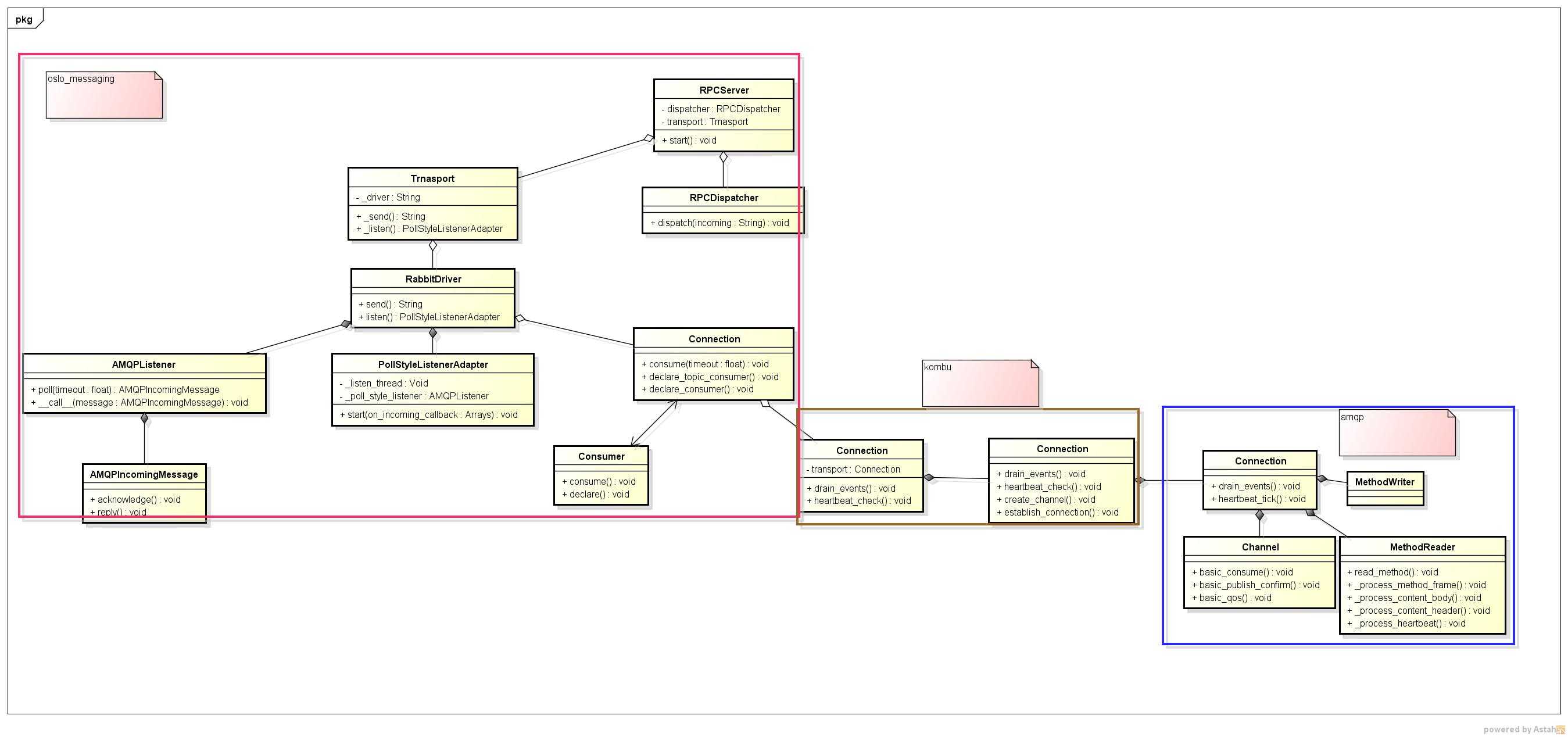
1.这里以nova-compute服务启动为例进行讲解,nova-compute服务启动,会通过配置文件解析获取一个Transport类对象,Transport对象里引用了RabbitDriver类对象
(1)Transport类作用:通过配置文件获取对应的_driver,使用_driver来发送消息
(2)RabbitDriver类作用:用于发送消息和创建监听类
2.nova-compute通过调用get_server函数获取RPCServer类对象,类对象聚合了Transport类对象和RPCDispatcher类对象
(1)RPCServer类作用:初始化rpc监听服务,创建队列
(2)RPCDispatcher类作用:收到消息后进行解析找到相对应的函数进行调用
3.调用RPCServer类对象的start方法,里面调用 _create_listener方法创建监听者AMQPListener类对象,用于作为绑定为消费者的回调对象,该类对象引用了一个Connection类对象conn。使用conn定义队列,最后返回一个PollStyleListenerAdapter类对象
(1)AMQPListener类作用:作为消费者绑定的回调对象,同时poll方法用于获取消息
(2)PollStyleListenerAdapter类作用:创建线程不断获取消息
(3)Connection类作用:获取了kombu的connection对象,用于进行消费者、队列定义和重连接等逻辑相关操作,使用Consumer类来管理消费者
(4)Consumer类作用:一个Consumer类对象代表一个消费者,里面保存了消费者信息和定义消费者的方法
(5)AMQPIncomingMessage类作用:消息进行解析后初始化为该类对象,代表一个消息的结构,里面有reply方法用于返回消息处理结果给发布消息者
4.PollStyleListenerAdapter类调用start方法开启一个线程while循环专门调用AMQPListener类对象的poll方法进行消息获取
5.poll函数会读取incomings队列里有没有消息,如果有则表示拿到一个未处理消息发给Dispatcher类去处理这个消息,如果该队列空了,则调用drain_events方法去获取各channel上传过来的消息并将它们存到inconings队列中。
6.drain_events方法机理:从strace工具看到该nova-compute服务有大量的epoll_wait方法调用,可知采用了事件触发的方式。
3.2 发送消息
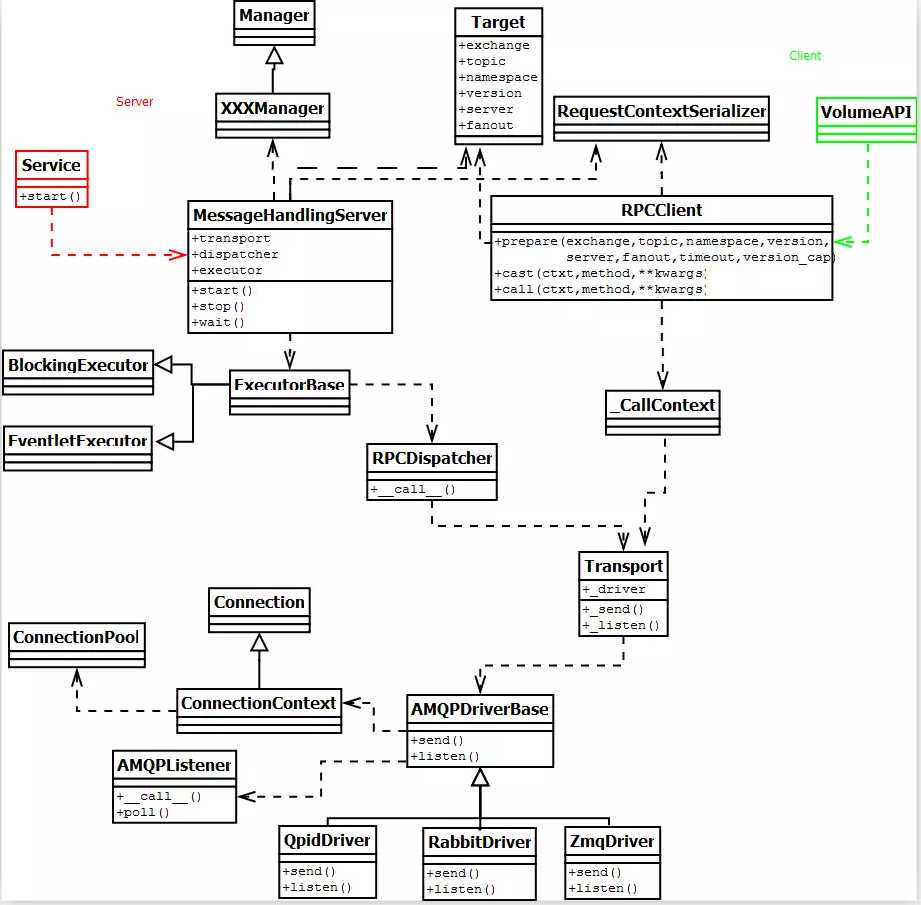
由于是发送消息,所以只要看右边的RPCClient端那部分就可以了:
1.跟接收消息一样,会根据target生成一个Transport类对象,该对象根据配置文件会获取一个driver对象,我们的是RabbitDriver对象,继承于AMQPDriverBase类;
2.获取一个_CallContext类对象,引用了Transport类对象
(1)_CallContext类作用:用来发送消息,对消息进行序列化并调用Transport类对象的driver来进行消息发送
3.获取Connection类对象进行消息发送
4.Connection类中通过kombu中的Producer类的发送方法进行消息发出
3.3 重连机制
每个消费者都是建立在一个channel上的,channel是建立在Tcp连接上的,如果连接的rabbitmq服务节点关闭了,则连接会断开,因此需要重新在其它未关闭节点上建立连接,重新建立channel和消费者。
重连机制的代码存在于impl_driver.py中的Connection类的consume函数中
这里有两个地方是可以检测到连接断开了,需要重连的,一个是在读取socket时发现,一个是在心跳检测机制里发现。
读socket时抛异常触发的重连:
1. 由上面分析我们知道程序会不断调用Connection的consume函数进行获取消息,该函数会调用到kombu的Connection类的autoretry函数,同时传入了_consume函数作为参数
2. autoretry又调用到ensure函数,该函数主要作用是调用传进来的_consume函数,如果有异常抛出,则进入异常重连处理,调用on_error函数,再调用ensure_connection函数确保重新建立好一条新的连接,然后在连接上建立新的channel,最后将channel进行更新。
心跳检测机制触发的重连:
1. 在服务启动后就有一个专门的线程定时发包检测连接是否正常,超时60秒则触发异常
2. 触发异常后调用ensure_connection函数将当前channel置为None,从而触发重建channel
消费者的重新建立:
1.在_consume函数中每次都会去判断self._new_tags集合是不是不为空,如果不为空则会重新建立这些tag的消费者,执行建立函数后就会把它remove掉,关键代码逻辑:
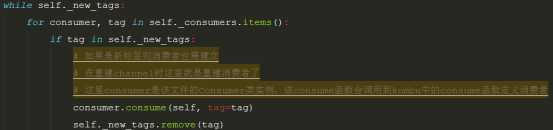
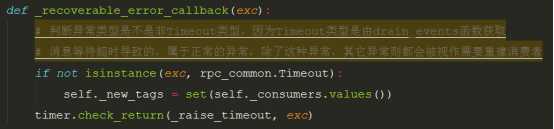
2.而_new_tags的获取则是根据异常抛出,检测异常类型来重新赋予之前消费者的tags,以此重新建立消费者,关键代码逻辑:
4 代码流程解析
4.1 nova-compute启动流程
Openstack的服务启动都是先从cmd目录下的main函数开始执行的,比如nova-compute服务的启动则是nova/cmd/compute.py文件中的main函数开始执行:
File:nova/cmd/compute.py
def main(): # 调用nova/service.py文件的Service类的create类方法实例化一个service类 server = service.Service.create(binary=‘nova-compute‘, topic=CONF.compute_topic) service.serve(server) service.wait()
得到server后调用server函数进行服务运行:
File:nova/service.py
def serve(server, workers=None): global _launcher if _launcher: raise RuntimeError(_(‘serve() can only be called once‘)) # 这里的service是指oslo_service包导入的service了 # 调用到oslo_service/service.py的launch方法 _launcher = service.launch(CONF, server, workers=workers)
launch函数调用oslo_service包的service.py的launch方法初始化一个ServiceLauncher实例,并调用launch_service函数:
File:oslo_service/service.py
def launch(conf, service, workers=1, restart_method=‘reload‘): if workers is not None and workers <= 0: raise ValueError(_("Number of workers should be positive!")) # 默认传入的是None if workers is None or workers == 1: # 这里是初始化一个继承了Launcher类的ServiceLauncher类实例 launcher = ServiceLauncher(conf, restart_method=restart_method) else: launcher = ProcessLauncher(conf, restart_method=restart_method) # 调用Launcher类里的launch_service方法,launch_service方法运行给定的service launcher.launch_service(service, workers=workers) return launcher
Launch_service函数调用了父类的实现:
File:oslo_service/service.py Launch:launch_service
def launch_service(self, service, workers=1): if workers is not None and workers != 1: raise ValueError(_("Launcher asked to start multiple workers")) _check_service_base(service) service.backdoor_port = self.backdoor_port # 调用Services类的add方法来运行给定service # 其实最后也就是开辟了个绿色线程池和获取一个绿色线程运行service的start方法 self.services.add(service)
我们可以直接看service的start方法:
File:nova/service.py Service:start
def start(self): ...... # 初始化oslo_messaging/target.py的Target类 target = messaging.Target(topic=self.topic, server=self.host) endpoints = [ self.manager, baserpc.BaseRPCAPI(self.manager.service_name, self.backdoor_port) ] endpoints.extend(self.manager.additional_endpoints) # 获取nova/objects/base.py中的NovaObjectSerializer类实例 # 用来序列化nova服务中的对象 serializer = objects_base.NovaObjectSerializer() # 获取一个oslo_messaging/rpc/RPCServer类实例 self.rpcserver = rpc.get_server(target, endpoints, serializer) # 调用到oslo_messaging/server.py的MessageHandlingServer类的start方法 self.rpcserver.start() ......
看下get_server实现:
File:nova/rpc.py
def get_server(target, endpoints, serializer=None): # TRANSPORT一个transport类对象,里面包含发消息的driver实现对象,如果是rabbit则对应到实现rabbit的driver类 # 获取TRANSPORT对象:<class ‘oslo_messaging.transport.Transport‘> # 更重要的是transport对象里的driver对象: oslo_messaging._drivers.impl_rabbit.RabbitDriver assert TRANSPORT is not None if profiler: serializer = ProfilerRequestContextSerializer(serializer) else: serializer = RequestContextSerializer(serializer) # get_rpc_server在oslo_messaging/rpc/server.py文件中 # 获取一个RPCServer实例 return messaging.get_rpc_server(TRANSPORT, target, endpoints, executor=‘eventlet‘, serializer=serializer)
查看get_rpc_server实现:
File:oslo_messaging/rpc/server.py
def get_rpc_server(transport, target, endpoints, executor=‘blocking‘, serializer=None, access_policy=None): # 获取一个消息调度员,它能识别收到的消息的结构 # 用于接收到消息后进行消息分发处理 A message dispatcher which understands RPC messages # oslo_messaging/rpc/dispatcher.py类的RPCDispatcher类 # 解析消息然后调用相对应的方法进行处理 dispatcher = rpc_dispatcher.RPCDispatcher(endpoints, serializer, access_policy) # 该类有个关键函数_process_incoming是在接收到消息时进行回调的 return RPCServer(transport, target, dispatcher, executor)
获取到RPCServer实例后,调用start方法,因为RPCServer继承于MessageHandlingServer但没有实现,所以是调用父类的start方法:
File:oslo_messaging/server.py MessageHandlingServer:start
def start(self, override_pool_size=None): ...... try: # 这里程序调用到的是oslo_messaging/rpc/server.py的RPCServer类的_create_listener方法 self.listener = self._create_listener() except driver_base.TransportDriverError as ex: raise ServerListenError(self.target, ex) ...... self.listener.start(self._on_incoming)
File:oslo_messaging/rpc/server.py RPCServer:_create_listener
def _create_listener(self): # oslo_messaging/transport/Transport类_listen方法 return self.transport._listen(self._target, 1, None)
File:oslo_messaging/transport.py Transport:_listen
def _listen(self, target, batch_size, batch_timeout): if not (target.topic and target.server): raise exceptions.InvalidTarget(‘A server\\‘s target must have ‘ ‘topic and server names specified‘, target) # 这个_driver对应的是oslo_messaging._drivers.impl_rabbit.RabbitDriver return self._driver.listen(target, batch_size, batch_timeout)
File:oslo_messaging/_drivers/amqpdriver.py AMQPDriverBase:listen
def listen(self, target, batch_size, batch_timeout): # 这里是从连接池里获取一个连接对象 # conn是oslo_messaging/_drivers/impl_rabbit.py的类Connection实例 conn = self._get_connection(rpc_common.PURPOSE_LISTEN) # 这个listen很关键,它被绑定为消费者的回调对象,也就是收到消息时是调用该对象,该对象实现了__call__方法 # 所以可直接调用 listener = AMQPListener(self, conn) conn.declare_topic_consumer(exchange_name=self._get_exchange(target), topic=target.topic, callback=listener) conn.declare_topic_consumer(exchange_name=self._get_exchange(target), topic=‘%s.%s‘ % (target.topic, target.server), callback=listener) conn.declare_fanout_consumer(target.topic, listener) # 返回一个实现poll模式监听消息到来的类 return base.PollStyleListenerAdapter(listener, batch_size, batch_timeout)
创建好监听类后,调用start方法:
File:oslo_messaging/_drivers/base.py PollStyleListenerAdapter:start
def start(self, on_incoming_callback): super(PollStyleListenerAdapter, self).start(on_incoming_callback) self._started = True # _listen_thread在__init__方法中定义了,如下行所示 # self._listen_thread = threading.Thread(target=self._runner) # 所以是开启一个线程运行_runner函数 self._listen_thread.start()
再来看下_runner函数:
File:oslo_messaging/_drivers/base.py PollStyleListenerAdapter:_runner
def _runner(self): while self._started: # 这里poll调用oslo_messaging/_drivers/amqpdriver.py的AMQPListener类poll函数 incoming = self._poll_style_listener.poll( batch_size=self.batch_size, batch_timeout=self.batch_timeout) # 读到有消息,调用回调函数进行处理 if incoming: # 该on_incoming_callback是oslo_messaging/server.py中self.listener.start(self._on_incoming)中传进来的 # 是该文件中MessageHandlingServer类的_on_incoming函数 # _on_incoming函数又调用到了RPCServer中的_process_incoming函数 self.on_incoming_callback(incoming)
这里先来看下poll函数实现:
File:oslo_messaging/_drivers/amqpdriver.py AMQPListener:poll
def poll(self, timeout=None): stopwatch = timeutils.StopWatch(duration=timeout).start() while not self._shutdown.is_set(): self._message_operations_handler.process() if self.incoming: # 从incoming列表中获取第一个消息返回 return self.incoming.pop(0) left = stopwatch.leftover(return_none=True) if left is None: left = self._current_timeout if left <= 0: return None try: # 获取所有队列的消息 # oslo_messaging/dr_drivers/impl_rabbit.py的Connection类的consume函数 # 将获取到的消息经过解析存到incoming列表中 self.conn.consume(timeout=min(self._current_timeout, left)) except rpc_common.Timeout: self._current_timeout = max(self._current_timeout * 2, ACK_REQUEUE_EVERY_SECONDS_MAX) else: self._current_timeout = ACK_REQUEUE_EVERY_SECONDS_MIN # NOTE(sileht): listener is stopped, just processes remaining messages # and operations self._message_operations_handler.process() if self.incoming: return self.incoming.pop(0) self._shutoff.set()
这里关键函数是调用consume进行消息获取,调用到了Connection类的consume函数,以下是该函数的关键语句:
# 调用kombu/connection.py的Connection类的drain_events方法,等待来自服务器的单个事件,所以这是事件触发型的
# 其中里面的supports_librabbitmq()=False(因为环境支持’eventlet’,所以未采用’default’,所以返回False
# 最后是调用到kombu/transport/pyamqp.py的drain_events方法
# 再调用到amqp包的Connection类的drain_events(amqp/connection.py)
File:oslo_messaging/_drivers/impl_rabbit.py Connection:consume
self.connection.drain_events(timeout=poll_timeout)
amqp包的drain_events实现
File:amqp/connection.py Connection: drain_events
def drain_events(self, timeout=None): """Wait for an event on a channel.""" # 等待事件通知 chanmap = self.channels chanid, method_sig, args, content = self._wait_multiple( chanmap, None, timeout=timeout, ) channel = chanmap[chanid] if (content and channel.auto_decode and hasattr(content, ‘content_encoding‘)): try: content.body = content.body.decode(content.content_encoding) except Exception: pass amqp_method = (self._method_override.get(method_sig) or channel._METHOD_MAP.get(method_sig, None)) if amqp_method is None: raise AMQPNotImplementedError( ‘Unknown AMQP method 0!r‘.format(method_sig)) if content is None: return amqp_method(channel, args) else: return amqp_method(channel, args, content)
到amqp包我们就不深究下去了
4.1 收到消息时行为
接着看下有消息到来时执行的回调函数,从前面我们可知在创建消费者时我们绑定了个listen对象作为callback,如下:
File:oslo_messaging/_drivers/amqpdriver.py AMQPDriverBase:listen
listener = AMQPListener(self, conn) conn.declare_topic_consumer(exchange_name=self._get_exchange(target), topic=target.topic, callback=listener)
所以当收到消息时会调用AMQPListener类的__call__函数:
def __call__(self, message): # 收到消息后解析消息结构体并构建成AMQPIncomingMessage结构 # type(message)对应类:<class ‘oslo_messaging._drivers.impl_rabbit.RabbitMessage‘> ctxt = rpc_amqp.unpack_context(message) unique_id = self.msg_id_cache.check_duplicate_message(message) if ctxt.msg_id: LOG.debug("received message msg_id: %(msg_id)s reply to " "%(queue)s", ‘queue‘: ctxt.reply_q, ‘msg_id‘: ctxt.msg_id) else: LOG.debug("received message with unique_id: %s", unique_id) self.incoming.append(AMQPIncomingMessage( self, ctxt.to_dict(), message, unique_id, ctxt.msg_id, ctxt.reply_q, self._obsolete_reply_queues, self._message_operations_handler))
可以看到收到message后,解析message并构建为AMQPIncomingMessage实例append到incoming队列中。
消息到队列中之后,当我们取到一个消息后做的事情,也就是回到_runner函数中的逻辑:
File:oslo_messaging/_drivers/base.py PollStyleListenerAdapter:_runner
def _runner(self): while self._started: # 这里poll调用oslo_messaging/_drivers/amqpdriver.py的AMQPListener类poll函数 incoming = self._poll_style_listener.poll( batch_size=self.batch_size, batch_timeout=self.batch_timeout) # 读到有消息,调用回调函数进行处理 if incoming: # 该on_incoming_callback是oslo_messaging/server.py中self.listener.start(self._on_incoming)中传进来的 # 是该文件中MessageHandlingServer类的_on_incoming函数 # _on_incoming函数又调用到了RPCServer中的_process_incoming函数 self.on_incoming_callback(incoming)
可知是调用了_process_incoming函数来处理消息:
# 这里poll调用oslo_messaging/_drivers/amqpdriver.py的AMQPListener类poll函数
# 处理消息
File:oslo_messaging/rpc/server.py RPCServer:__process_incoming
def _process_incoming(self, incoming): message = incoming[0] try: # 这里进行了消息确认发送 # 会调用到kombu/message.py的Message类的ack函数 # 表示该消息已经进行消费了,队列中可以删除该消息了 message.acknowledge() except Exception: LOG.exception(_LE("Can not acknowledge message. Skip processing")) return failure = None try: # 调用oslo_messaging/rpc/dispatcher.py的RPCDispatcher类来处理消息 # 该类的职责是找到消息对应的方法并执行 res = self.dispatcher.dispatch(message) except rpc_dispatcher.ExpectedException as e: failure = e.exc_info LOG.debug(u‘Expected exception during message handling (%s)‘, e) except Exception: # current sys.exc_info() content can be overridden # by another exception raised by a log handler during # LOG.exception(). So keep a copy and delete it later. failure = sys.exc_info() LOG.exception(_LE(‘Exception during message handling‘)) try: # 将执行结果返回 if failure is None: message.reply(res) else: message.reply(failure=failure) except Exception: LOG.exception(_LE("Can not send reply for message")) finally: # NOTE(dhellmann): Remove circular object reference # between the current stack frame and the traceback in # exc_info. del failure
核心函数是dispatch函数:
File:oslo_messaging/rpc/dispatcher.py RPCDispatcherr:dispatch
def dispatch(self, incoming): """Dispatch an RPC message to the appropriate endpoint method. :param incoming: incoming message :type incoming: IncomingMessage :raises: NoSuchMethod, UnsupportedVersion """ message = incoming.message ctxt = incoming.ctxt method = message.get(‘method‘) args = message.get(‘args‘, ) namespace = message.get(‘namespace‘) version = message.get(‘version‘, ‘1.0‘) found_compatible = False # endpoints值是两个类 # [<nova.compute.manager.ComputeManager object at 0x7f6eef157dd0>, <nova.baserpc.BaseRPCAPI object at 0x7f6ee4724c90>] # 从类中查找出方法进行调用 for endpoint in self.endpoints: target = getattr(endpoint, ‘target‘, None) if not target: target = self._default_target if not (self._is_namespace(target, namespace) and self._is_compatible(target, version)): continue if hasattr(endpoint, method): if self.access_policy.is_allowed(endpoint, method): return self._do_dispatch(endpoint, method, ctxt, args) found_compatible = True if found_compatible: raise NoSuchMethod(method) else: raise UnsupportedVersion(version, method=method)
File:oslo_messaging/rpc/dispatcher.py RPCDispatcherr:dispatch
def _do_dispatch(self, endpoint, method, ctxt, args): ctxt = self.serializer.deserialize_context(ctxt) new_args = dict() for argname, arg in args.items(): new_args[argname] = self.serializer.deserialize_entity(ctxt, arg) func = getattr(endpoint, method) # 调用方法 result = func(ctxt, **new_args) return self.serializer.serialize_entity(ctxt, result)
4.3 发送消息流程
这里看一个发送开机指令到宿主机执行的流程。
首先由novaclient发送http请求到nova-api服务,对应调用到_start_server函数:
File:nova/api/openstack/compute/server.py ServersController:_start_server
def _start_server(self, req, id, body): ..... try: # nova/compute/api.py self.compute_api.start(context, instance) except (exception.InstanceNotReady, exception.InstanceIsLocked) as e: .....
查看start方法实现:
File:nova/compute/api.py API:start
def start(self, context, instance): ..... instance.task_state = task_states.POWERING_ON instance.save(expected_task_state=[None]) self._record_action_start(context, instance, instance_actions.START) self.compute_rpcapi.start_instance(context, instance) .....
可以看到是先将task_state状态改为了POWERING_ON后再发送消息,查看start_instance方法的实现:
File:nova/compute/rpcapi.py ComputeAPI:start_instance
def start_instance(self, ctxt, instance): version = ‘4.0‘ # self.router.by_instance(ctxt, instance)获取oslo_messaging/rpc/client.py的RPCClient类实例 # prepare方法是用于设置一些属性并生成一个oslo_messaging/rpc/client.py的_CallContext类实例 cctxt = self.router.by_instance(ctxt, instance).prepare( server=_compute_host(None, instance), version=version) # 该call方法是调用到oslo_messaging/rpc/client.py的_BaseCallContext(_CallContext的父类)类的call方法 return cctxt.call(ctxt, ‘start_instance‘, instance=instance)
查看call方法实现:
File:oslo_messaging/rpc/client.py _BaseCallContext:call
def call(self, ctxt, method, **kwargs): """Invoke a method and wait for a reply. See RPCClient.call().""" if self.target.fanout: raise exceptions.InvalidTarget(‘A call cannot be used with fanout‘, self.target) # 生成一个msg msg = self._make_message(ctxt, method, kwargs) # 序列化ctxt msg_ctxt = self.serializer.serialize_context(ctxt) timeout = self.timeout if self.timeout is None: timeout = self.conf.rpc_response_timeout self._check_version_cap(msg.get(‘version‘)) try: # 调用transport中的_send方法 # _send方法中又是使用_driver对象调用send方法 # _driver对象是oslo_messaging._drivers.impl_rabbit.RabbitDriver # 所以是调用RabbitDriver类里的send方法,实际是调用它父类AMQPDriverBase的send方法 result = self.transport._send(self.target, msg_ctxt, msg, wait_for_reply=True, timeout=timeout, retry=self.retry) except driver_base.TransportDriverError as ex: raise ClientSendError(self.target, ex) return self.serializer.deserialize_entity(ctxt, result)
查看send方法实现:
File:oslo_messaging/_drivers/amqpdriver.py AMQPDriverBase:_send
def _send(self, target, ctxt, message, wait_for_reply=None, timeout=None, envelope=True, notify=False, retry=None): msg = message if wait_for_reply: msg_id = uuid.uuid4().hex msg.update(‘_msg_id‘: msg_id) # _get_reply_q方法获取一个ReplyWaiter对象,开始poll模式等待获取返回消息 # 同时使用waiters(ReplyWaiter实例对象)管理返回的消息 msg.update(‘_reply_q‘: self._get_reply_q()) # 获取一个唯一uuid添加到msg字典中 rpc_amqp._add_unique_id(msg) unique_id = msg[rpc_amqp.UNIQUE_ID] # 把ctxt字典值也更新到msg中 rpc_amqp.pack_context(msg, ctxt) if envelope: msg = rpc_common.serialize_msg(msg) if wait_for_reply: # 把该消息加到waiters里去监控管理 self._waiter.listen(msg_id) log_msg = "CALL msg_id: %s " % msg_id else: log_msg = "CAST unique_id: %s " % unique_id try: # 根据target保存的发送模式发送消息 with self._get_connection(rpc_common.PURPOSE_SEND) as conn: if notify: exchange = self._get_exchange(target) log_msg += "NOTIFY exchange ‘%(exchange)s‘" " topic ‘%(topic)s‘" % ‘exchange‘: exchange, ‘topic‘: target.topic LOG.debug(log_msg) conn.notify_send(exchange, target.topic, msg, retry=retry) elif target.fanout: log_msg += "FANOUT topic ‘%(topic)s‘" % ‘topic‘: target.topic LOG.debug(log_msg) conn.fanout_send(target.topic, msg, retry=retry) else: topic = target.topic exchange = self._get_exchange(target) if target.server: topic = ‘%s.%s‘ % (target.topic, target.server) log_msg += "exchange ‘%(exchange)s‘" " topic ‘%(topic)s‘" % ‘exchange‘: exchange, ‘topic‘: topic LOG.debug(log_msg) # 发送topic模式的队列 # 调用oslo_messaging/_drivers/impl_rabbit.py中Connection类实例的topic_send方法 conn.topic_send(exchange_name=exchange, topic=topic, msg=msg, timeout=timeout, retry=retry) if wait_for_reply: # 等待返回或消息超时返回 # 轮询方式检测消息有没有被返回并放到对应的字典中 result = self._waiter.wait(msg_id, timeout) if isinstance(result, Exception): raise result return result finally: if wait_for_reply: self._waiter.unlisten(msg_id)
当消息返回或消息超时时就返回结果给call调用,这个请求就完成了
4.4 重连机制
当比如当前连接着的rabbitmq服务断开了时,则连接会断开,则需要重新建立连接,建立新的channel,然后重新建立消费者。
这个逻辑在Connection的consume函数中,是由监听类的poll函数进行不断调用的,我们看下该函数实现:
File:oslo_messaging/_drivers/impl_rabbit.py Connection:consume
def consume(self, timeout=None): """Consume from all queues/consumers.""" timer = rpc_common.DecayingTimer(duration=timeout) timer.start() def _raise_timeout(exc): LOG.debug(‘Timed out waiting for RPC response: %s‘, exc) raise rpc_common.Timeout() def _recoverable_error_callback(exc): # 判断异常类型是不是非Timeout类型,因为Timeout类型是由drain_events函数获取 # 消息等待超时导致的,属于正常的异常,除了这种异常,其它异常则都会被视作需要重建消费者 if not isinstance(exc, rpc_common.Timeout): self._new_tags = set(self._consumers.values()) timer.check_return(_raise_timeout, exc) def _error_callback(exc): # 将异常交给_recoverable_error_callback函数进行处理 _recoverable_error_callback(exc) LOG.error(_LE(‘Failed to consume message from queue: %s‘), exc) def _consume(): # NOTE(sileht): in case the acknowledgment or requeue of a # message fail, the kombu transport can be disconnected # In this case, we must redeclare our consumers, so raise # a recoverable error to trigger the reconnection code. # 这里是判断了连接是否还正常,如果不正常,我们需要重新获取连接并且重新定义consumer if not self.connection.connected: # 这里抛错以进入重连机制 raise self.connection.recoverable_connection_errors[0] while self._new_tags: for consumer, tag in self._consumers.items(): if tag in self._new_tags: # 如果是新标签则消费者也需建立 # 在重建channel时这里就是重建消费者了 # 这里consumer是该文件的Consumer类实例,该consume函数会调用到kombu中的consume函数定义消费者 consumer.consume(self, tag=tag) self._new_tags.remove(tag) poll_timeout = (self._poll_timeout if timeout is None else min(timeout, self._poll_timeout)) while True: if self._consume_loop_stopped: return if self._heartbeat_supported_and_enabled(): # 心跳检查,如果连不通则抛错 # 抛错则会在kombu中进行重连机制 self._heartbeat_check() try: # 调用kombu/connection.py的Connection类的drain_events方法,等待来自服务器的单个事件,所以这是事件触发型的 # 其中里面的supports_librabbitmq()=False(因为环境支持’eventlet’,所以未采用’default’,所以返回False # 最后是调用到kombu/transport/pyamqp.py的drain_events方法 # 再调用到amqp包的Connection类的drain_events(amqp/connection.py) self.connection.drain_events(timeout=poll_timeout) return except socket.timeout as exc: # 超时会进入这个逻辑,check_return会raise一个Exception,从而导致ensure中抛异常被捕获调用了error_callback函数 # error_callback函数又调用了recoverable_error_callback函数 # 从而导致日志中经常可以看到_recoverable_error_callback poll_timeout = timer.check_return( _raise_timeout, exc, maximum=self._poll_timeout) with self._connection_lock: self.ensure(_consume, recoverable_error_callback=_recoverable_error_callback, error_callback=_error_callback)
这里很多内嵌函数都会通过传参的方式传入到其它方法中处理,然后由其它方法在检测到异常时执行。我们可以看到最终是执行了ensure函数,我们看下ensure函数的实现:
File:oslo_messaging/_drivers/impl_rabbit.py Connection:ensure
def ensure(self, method, retry=None, recoverable_error_callback=None, error_callback=None, timeout_is_error=True): ..... # 在kombu中如果进入了异常重连处理机制会回调该函数 def on_error(exc, interval): LOG.debug("[%s] Received recoverable error from kombu:" % self.connection_id, exc_info=True) # 执行_recoverable_error_callback函数处理异常 recoverable_error_callback and recoverable_error_callback(exc) interval = (self.kombu_reconnect_delay + interval if self.kombu_reconnect_delay > 0 else interval) info = ‘err_str‘: exc, ‘sleep_time‘: interval info.update(self._get_connection_info()) if ‘Socket closed‘ in six.text_type(exc): LOG.error(_LE(‘[%(connection_id)s] AMQP server‘ ‘ %(hostname)s:%(port)s closed‘ ‘ the connection. Check login credentials:‘ ‘ %(err_str)s‘), info) else: LOG.error(_LE(‘[%(connection_id)s] AMQP server on ‘ ‘%(hostname)s:%(port)s is unreachable: ‘ ‘%(err_str)s. Trying again in ‘ ‘%(sleep_time)d seconds. Client port: ‘ ‘%(client_port)s‘), info) ...... # 当在kombu中执行autoretry时抛出异常了并在异常处理时重新连接了其它节点 # 则会回调该函数 def on_reconnection(new_channel): # 更新channel self._set_current_channel(new_channel) self.set_transport_socket_timeout() def execute_method(channel): # 更新channel self._set_current_channel(channel) # 这个method指的就是_consume函数 # 注意我这里指的是consume调入的时候该method就是_consume函数 # 因为该ensure函数是很多函数都会调用的,每个函数都会传入它的method函数进行回调 # 我这里是为了方便理解就这样指明了,文中还有很多地方也是如此指明,就不一一解释了 method() # NOTE(sileht): Some dummy driver like the in-memory one doesn‘t # have notion of recoverable connection, so we must raise the original # exception like kombu does in this case. has_modern_errors = hasattr( self.connection.transport, ‘recoverable_connection_errors‘, ) if has_modern_errors: recoverable_errors = ( self.connection.recoverable_channel_errors + self.connection.recoverable_connection_errors) else: recoverable_errors = () try: autoretry_method = self.connection.autoretry( execute_method, channel=self.channel, max_retries=retry, errback=on_error, interval_start=self.interval_start or 1, interval_step=self.interval_stepping, interval_max=self.interval_max, on_revive=on_reconnection) ret, channel = autoretry_method() self._set_current_channel(channel) return ret except recoverable_errors as exc: LOG.debug("Received recoverable error from kombu:", exc_info=True) # 在kombu重建立连接失败时会跑入该逻辑,调用error_callback # 如果是consume函数调入该函数的话,则该函数是_error_callback函数 error_callback and error_callback(exc) self._set_current_channel(None) # NOTE(sileht): number of retry exceeded and the connection # is still broken info = ‘err_str‘: exc, ‘retry‘: retry info.update(self.connection.info()) msg = _(‘Unable to connect to AMQP server on ‘ ‘%(hostname)s:%(port)s after %(retry)s ‘ ‘tries: %(err_str)s‘) % info LOG.error(msg) raise exceptions.MessageDeliveryFailure(msg) except rpc_amqp.AMQPDestinationNotFound: # NOTE(sileht): we must reraise this without # trigger error_callback raise except Exception as exc: error_callback and error_callback(exc) Raise
这个函数也是如此,定义了很多内嵌函数,然后作为参数传递到kombu中的autoretry函数中进行处理,方便有异常时就行异常处理且回调相对应的函数。查看autoretry函数实现:
File:kombu/connection.py Connection:autoretry
def autoretry(self, fun, channel=None, **ensure_options): channels = [channel] create_channel = self.channel class Revival(object): __name__ = getattr(fun, ‘__name__‘, None) __module__ = getattr(fun, ‘__module__‘, None) __doc__ = getattr(fun, ‘__doc__‘, None) def revive(self, channel): channels[0] = channel def __call__(self, *args, **kwargs): if channels[0] is None: self.revive(create_channel()) # 执行oslo_messaging中impl_rabbit的ensure中的execute_method函数 # execute_method最终又是回调到_consume函数 return fun(*args, channel=channels[0], **kwargs), channels[0] revive = Revival() # 返回了一个_ensure闭包函数 # 但oslo_messaging的ensure函数中的下一行便是执行该闭包函数 return self.ensure(revive, revive, **ensure_options)
这里最后又调用了ensure函数,该ensure函数是关键,它里面进行了连接重连机制。查看ensure实现:
File:kombu/connection.py Connection:ensure
def ensure(self, obj, fun, errback=None, max_retries=None, interval_start=1, interval_step=1, interval_max=1, on_revive=None): def _ensured(*args, **kwargs): got_connection = 0 conn_errors = self.recoverable_connection_errors chan_errors = self.recoverable_channel_errors has_modern_errors = hasattr( self.transport, ‘recoverable_connection_errors‘, ) for retries in count(0): # for infinity try: # 调用了Revival类的__call__函数 # 在进行的一系列调用中如果有异常抛出则进入下面的重连机制 return fun(*args, **kwargs) except conn_errors as exc: if got_connection and not has_modern_errors: raise if max_retries is not None and retries > max_retries: raise self._debug(‘ensure connection error: %r‘, exc, exc_info=1) self._connection = None self._do_close_self() errback and errback(exc, 0) remaining_retries = None if max_retries is not None: remaining_retries = max(max_retries - retries, 1) # 尝试重新建立连接,确保有连接建立成功 self.ensure_connection(errback, remaining_retries, interval_start, interval_step, interval_max) # 在连接上获取新的channel new_channel = self.channel() self.revive(new_channel) obj.revive(new_channel) if on_revive: # 调用oslo_messaging中的on_reconnection函数 # 将获得的新channel赋给Connection类的channel on_revive(new_channel) got_connection += 1 except chan_errors as exc: if max_retries is not None and retries > max_retries: raise self._debug(‘ensure channel error: %r‘, exc, exc_info=1) errback and errback(exc, 0) _ensured.__name__ = "%s(ensured)" % fun.__name__ _ensured.__doc__ = fun.__doc__ _ensured.__module__ = fun.__module__ return _ensured
可以看到如果是触发了异常则进入下面的异常处理,进行重连和回调函数调用等操作,所以如果进行了重连,就会触发到oslo_messaging那边定义的很多内嵌函数来协助处理重连逻辑。
以上是关于OpenStack RPC框架浅析的主要内容,如果未能解决你的问题,请参考以下文章