机器学习之集成学习
Posted dyl222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之集成学习相关的知识,希望对你有一定的参考价值。
详细参考:https://www.cnblogs.com/pinard/p/6131423.html
首先明确集成学习它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。
集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策略,将这些个体学习器集合成一个强学习器。对于个体学习器第一种就是所有的个体学习器都是一个种类的,或者说是同质的。比如都是决策树个体学习器,或者都是神经网络个体学习器。第二种是所有的个体学习器不全是一个种类的,或者说是异质的。比如我们有一个分类问题,对训练集采用支持向量机个体学习器,逻辑回归个体学习器和朴素贝叶斯个体学习器来学习,再通过某种结合策略来确定最终的分类强学习器。
目前来说,同质个体学习器的应用是最广泛的,一般我们常说的集成学习的方法都是指的同质个体学习器。而同质个体学习器使用最多的模型是CART决策树和神经网络。同质个体学习器按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成,代表算法是boosting系列算法,第二个是个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,代表算法是bagging和随机森林(Random Forest)系列算法。
集成策略有投票法,平均法,学习法等等。
1.bagging
bagging的个体弱学习器的训练集是通过随机采样得到的。通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略(一般对于分类问题集成策略选用投票法,对于回归问题集成策略选择平均法)来得到最终的强学习器(具有代表性的bagging思想的集成学习模型是随机森林(RF))。
随机采样一般采用的是自助采样法(Bootstrap sampling),即对于m个样本的原始训练集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集m次,最终可以得到m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
2.boosting
Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器(具有代表性的采用boosting思想的模型有Adaboost以及GBDT和XGBoost)。
3.stacking(模型融合)
详细解析可以参考:
https://zhuanlan.zhihu.com/p/26890738
https://www.zhihu.com/question/24598447/answer/232954415
https://zhuanlan.zhihu.com/p/33589222
如何做
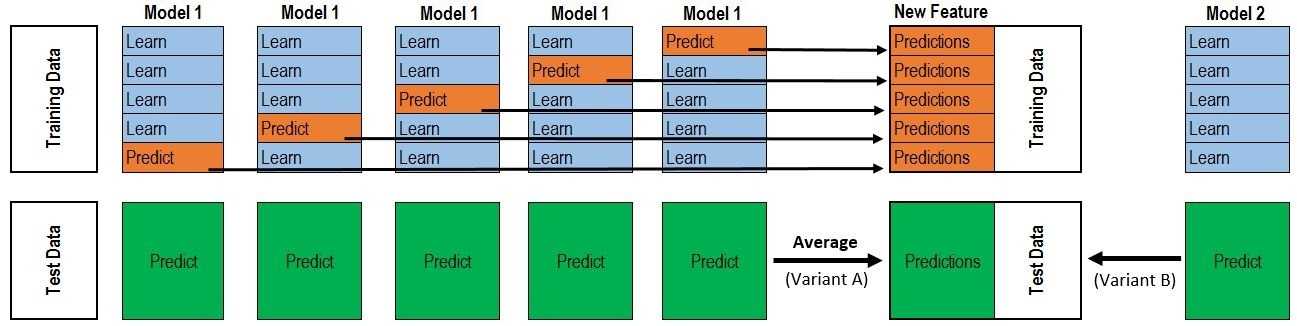
假设弱学习器为(A1,A2,A3)强学习器为B,对训练数据进行五折交叉,以弱学习器A1为例(对应上图上面部分的Model1),五折交叉对应五次的Model1,每次通过上图蓝色的4份learn训练模型,通过训练出的模型预测橙色的Predict验证集部分,得到结果Predictions(维度记为[v1,1]),对五次交叉获得的Predictions进行连接组成新的数据(维度记为[v1*5,1]),同时数据集整体记为P1.同时没个fold训练出模型之后还需要对上图绿色的测试集进行预测得到的结果(维度记为[t1,1])五折则结果的维度为[t1*5,1],然后对数据取平均得到的数据维度记为[at1,1],数据整体记住T1.
对于弱学习器A2,A3同样如此,A2能够获得的数据维度记为[v2*5,1]),同时数据集整体记为P2,以及[at2,1],数据整体记住T2,A3能够获得的数据维度记为[v3*5,1]),同时数据集整体记为P3,以及[at3,1],数据整体记住T3.对P1,P2,P3组合获得数据维度[V,3]作为强学习器B的训练数据,T1,T2,T3组合获得数据维度[AT,3]作为强学习器的验证数据。
一般来说,一个好的融合的子模型应该符合以下两个假设:
1)准确性(accuracy):大部分子模型要能对最终输出有所帮助,而不是帮倒忙,应该至少比随机猜测更准确。
2)多样性(diversity):子模型间需要有所不同,长处和短处各异,(高度相关的)同质化的子模型无法互补。
于是我们想要同时提高“准确性”和“多样性”,但很快就发现它们是此消彼长、互相制约的关系。
先不考虑准确性问题,仅对多样性这方面进行考虑,可以通过如下这些方法提高多样性:
1)选用不同类型的分类器,在整个X上进行训练。此时的模型的多样性取决于子模型对于数据不同的表达能力
2) 选用同类型的分类器,但使用不同的参数,此时模型的多样性取决于“不同超参数在同一模型上的差异”所决定。
3) 选用相同的分类器,但在不同的训练集上进行训练。此时的差异性来源于数据的差异性。
4) 使用相同的分类器,但在不同特征上进行训练。同理,此时的多样性来源于数据的差异性。
我们因此发现,构造子模型就已经非常复杂了,融合模型有无数种组合方式,没有唯一正确的方法。融合的底线就是尽量保持“准确性”和“多样性”间的平衡。因此我们特别注意,手动融合模型时一般很少构造大量的弱分类器,而是精挑细选少量的强模型进行融合。手动构造融合模型时,建议优先考虑准确性,再考虑多样性。
对于模型融合而言,子模型的选择尤为重要,选择子模型时应以准确度为首要,以多样性为次要。同时需要注意的是,子模型的输出不一定在同一个取值范围内,为了更好的进行融合,应该把各个模型的取值控制在相同的范围之内。
4.Stacking的输出层为什么一般用Logistic回归的效果比较好?
stacking的有效性主要来自于特征抽取,第一层已经通过不同的模型进行了特征的抽取,把这些抽取的特征作为新的输入,即为已经使用了复杂的非线性变换,因此在输出层不需要复杂的分类器。同时这也是在stacking中第二层数据中的特征中不该包括原始特征的原因,都是为了避免过拟合现象的发生。因此,stacking的输出层不需要过分复杂的函数,用逻辑回归还有额外的好处:
1)配合正则化还可以进一步防止过拟合
2)逻辑回归的输出结果还可被理解为概率
5.Stacking和神经网络
具体参考:https://zhuanlan.zhihu.com/p/32896968(非常赞的分析,多思考)
Stacking一般来说,就是训练一个多层(一般是两层)的学习器结构,第一层(也叫学习层)用n个异质分类器或者n个同质分类器(这时要保证特征不同或者训练数据不同)将得到预测结果合并为新的特征集,并作为下一层分类器的输入。
Stacking不需要多层一般两层就好,因为层数过多会带来更严重的过拟合问题,那为什么 在stacking中堆多几层,效果提升不明显,或由于过拟合而效果下降呢?专栏的博主认为原因是,stacking中的表示,不是分布表示。而深度起作用的前提是分布表示,所以堆多层不好。第一层分类器的数量对于特征学习应该有所帮助,经验角度看越多的基分类器越好。即使有所重复和高依赖性,我们依然可以通过特征选择来处理,问题不大。
在stacking中,通过第一层的多个学习器后,有效的特征被学习出来了。从这个角度来看,stacking的第一层就是特征抽取的过程。
Stacking的缺点也非常明显,stacking往往面临很大的运算开销,在预测时需要运行多个模型。
别的非常赞的想法:
Stacking和神经网络都属于表示学习(表示学习指的是模型从原始数据中自动抽取有效特征的过程)
Stacking中的第一层可以等价于神经网络中的前 n-1层,而stacking中的最终分类层可以类比于神经网络中最后的输出层。不同点在于,stacking中不同的分类器通过异质来体现对于不同特征的表示,神经网络是从同质到异质的过程且有分布式表示的特点(distributed representation)。Stacking中应该也有分布式的特点,主要表现在多个分类器的结果并非完全不同,而有很大程度的相同之处。
stacking的第一层与神经网络的所有隐藏层都是一个高度复杂的非线性特征转换器,样本的表示经过这个变换后,得到了新的表示更好的表示,即线性可分。这样stacking的第二层与神经网络的输出层使用简单模型就足够了。
不同之处:
stacking需要宽度,深度学习不需要
深度学习需要深度,而stacking不需要
我觉得stacking和深度学习有个区别,深度学习层与层之间梯度是能传回去的,所以所有层之间会“彼此协调”,stacking每层之间并没有之间的关联,训练后面的一层不会改变前面一层的权重值。
神经网络相比于Stacking的优势,神经网络能够通过迁移学习应用到先验知识。
以上是关于机器学习之集成学习的主要内容,如果未能解决你的问题,请参考以下文章