Solr5.5.1 IK中文分词配置与使用
Posted 歪头儿在帝都
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr5.5.1 IK中文分词配置与使用相关的知识,希望对你有一定的参考价值。
前言
用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词。其中包含一个词典。 那么既然用到了这种国际化的框架,那么就避免不了中文分词。尤其是国内特殊行业比较多。比如油田系统从勘探、打井、投产等若干环节都涉及一些专业词汇。 再像电商,手机、手机配件、笔记本、笔记本配件之类。汽车,品牌、车系、车型等等,这一系列数据背后都涉及各自领域的专业名次,所以中文分词就最终的目的还是为了解决搜索结果的精确度和匹配度的问题。
IK搜索预览
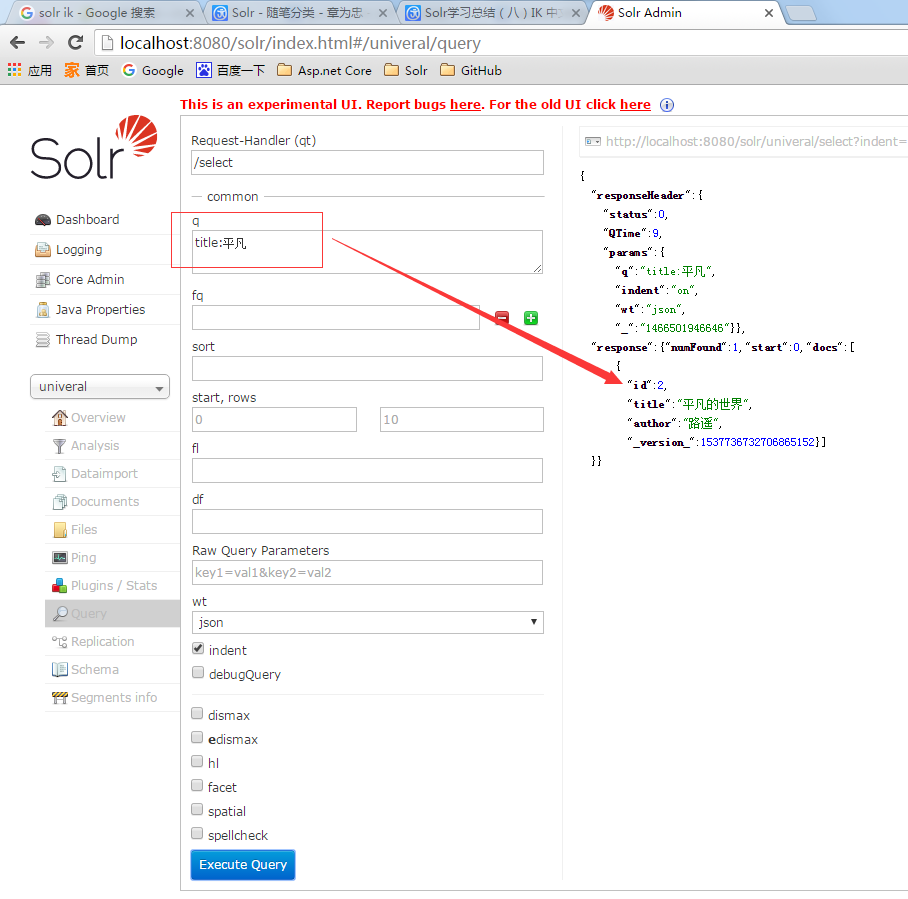
我的univeral Core里包含两条数据,第二条数据的title和author都是中文的。 然后我用关键字q=title:平凡来搜索,搜索出来第二条数据。 如果你在你的索引库里没搜索出来也不要奇怪,配置下IK中文分词就可以了。
中文语义分析
在索引库Core左侧菜单Analysis中,你可以输入复杂的查询【关键字】,选择对应字段,点击【Analysis Values】会帮你分析出当前这个复杂的词组都会分解出那几个搜索关键字或关键词来。如果这里满足不了你的专业词汇,那就该从词典下手了。我这里输入了:平凡的世界。分析后得出两个词:平凡、世界。 也就是我在上一张图中用平凡搜索的结果。

中文分词的配置和使用
1、下载对应IK版本。我本地部署的Solr5.5.1。 所以就下载最新版本。
2、把ik目录下的文件复制到tomcat/webapps/solr/WEB-INF/lib目录下。 ik目录里有一个ext.dic、stopword.dic。 可以打开看一看里面内容。
3、修改schema.xml。我本地是univeral/conf/managed-schema。 增加中文分词配置节点,内容如下
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
4、修改对应field的类型。我修改了两个字段
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" /> <field name="author" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
参考教程:http://www.cnblogs.com/zhangweizhong/p/5593909.html
备注
如果之前你已经创建了索引,那么配置IK中文分词后先修改schema.xml中的field对应类型。 清空索引后重新创建索引。 OK。大功搞成。
以上是关于Solr5.5.1 IK中文分词配置与使用的主要内容,如果未能解决你的问题,请参考以下文章