python3 selenium动态获取唯品会商品
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3 selenium动态获取唯品会商品相关的知识,希望对你有一定的参考价值。
http://list.vip.com/766479.html?q=0|0|0|0|0|2
我要获取这个:
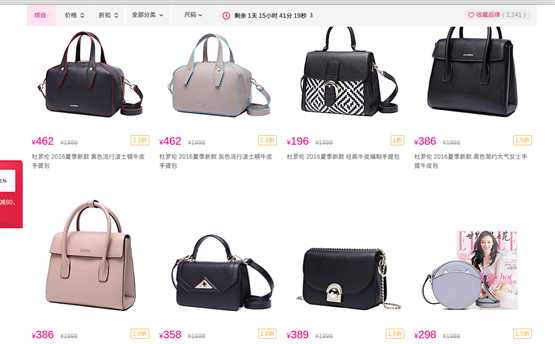
然而数据是AJAX异步加载的:

然后我的代码是:
# -*- coding:utf-8 -*- import re import urllib.request, urllib.parse, http.cookiejar import os, time,re import http.cookies from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import NoSuchElementException ## 说明 ## 安装包 ## pip3 install bs4 ## pip3 install -U selenium ## 抓取不会变的网址用gethtml,否则getFirefox() ## 得到原始网页 def getHtml(url,daili=‘‘,postdata={}): """ 抓取网页:支持cookie 第一个参数为网址,第二个为POST的数据 """ # COOKIE文件保存路径 filename = ‘cookie.txt‘ # 声明一个MozillaCookieJar对象实例保存在文件中 cj = http.cookiejar.MozillaCookieJar(filename) # cj =http.cookiejar.LWPCookieJar(filename) # 从文件中读取cookie内容到变量 # ignore_discard的意思是即使cookies将被丢弃也将它保存下来 # ignore_expires的意思是如果在该文件中 cookies已经存在,则覆盖原文件写 # 如果存在,则读取主要COOKIE if os.path.exists(filename): cj.load(filename, ignore_discard=True, ignore_expires=True) # 建造带有COOKIE处理器的打开专家 proxy_support = urllib.request.ProxyHandler({‘http‘:‘http://‘+daili}) # 开启代理支持 if daili: print(‘代理:‘+daili+‘启动‘) opener = urllib.request.build_opener(proxy_support, urllib.request.HTTPCookieProcessor(cj), urllib.request.HTTPHandler) else: opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # 打开专家加头部 opener.addheaders = [(‘User-Agent‘, ‘Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5‘), ] # 分配专家 urllib.request.install_opener(opener) # 有数据需要POST if postdata: # 数据URL编码 postdata = urllib.parse.urlencode(postdata) # 抓取网页 html_bytes = urllib.request.urlopen(url, postdata.encode()).read() else: html_bytes = urllib.request.urlopen(url).read() # 保存COOKIE到文件中 cj.save(ignore_discard=True, ignore_expires=True) return html_bytes ## 从火狐获取动态js,然后根据total得到页面数据,total表示全部,否则只能得到可视化的部分 def getFirefox(url,total=1,times=1): data="" browser = webdriver.Firefox() browser.get(url) time.sleep(times) try: if total==1: data=browser.page_source else: data=browser.find_element_by_xpath("html").text except NoSuchElementException: print("神马都没有") return browser,data def parse(data): # print(data) bai=re.compile(r‘<script>(.+)</script>‘) data=bai.match(data) if data: print(m.group()) else: print("神马都没有") print(data) #var config = {...} #</script> # soup = BeautifulSoup(data, ‘html.parser‘) # return soup.find_all("h4") if __name__ == ‘__main__‘: for i in range(246,247): url = "http://list.vip.com/766479.html?q=0|0|0|0|0|2" browers,data=getFirefox(url,0) maindata=browers.find_element_by_id("J_wrap_pro_add").text print(maindata) browers.close() #browser.quit() # url = "http://list.vip.com/766479.html?q=0|0|0|0|0|2" # try: # data =getHtml(url) # data = data.decode(‘utf-8‘,"ignore") # data=parse(data) # print(data) #解析网站用的 # except Exception as e: # if hasattr(e, ‘code‘): # print(‘页面不存在或时间太长.‘) # print(‘Error code:‘, e.code) # elif hasattr(e, ‘reason‘): # print("无法到达主机.") # print(‘Reason: ‘, e.reason) # else: # print(e)
想直接用getHtml()自己写的函数弄,然后正则得到script里面的东西,麻烦。不要!我们下一步开始,进入正题。
下面是运行方式。好吧,这就结束,自己看上面的代码哈。
pip3 install bs4
pip3 install -U selenium
python3 jiexi.py
以上是关于python3 selenium动态获取唯品会商品的主要内容,如果未能解决你的问题,请参考以下文章