Elasticsearch-用于定义文档字段的核心类型-字符串类型
Posted enzodin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch-用于定义文档字段的核心类型-字符串类型相关的知识,希望对你有一定的参考价值。
ES-用于定义文档字段的核心类型
ES中一个字段可以是核心类型之一,如字符串、数值、日期、布尔型,也可以是一个从核心类型派生的复杂类型,如数组。
字符串类型
索引一类型为字符串的数据
doc1:
FengZhendeMacBook-Pro:bin FengZhen$ curl -XPUT ‘localhost:9200/music/album/2‘ -d ‘ > "name":"Late Night with Elasticsearch", > "date":"2019-06-24T22:17" > ‘
doc2:
FengZhendeMacBook-Pro:bin FengZhen$ curl -XPUT ‘localhost:9200/music/album/3‘ -d ‘ > "name":"latenight", > "date":"2019-06-24T22:20" > ‘
在name字符串字段里搜索单词late
FengZhendeMacBook-Pro:bin FengZhen$ curl -XGET ‘localhost:9200/music/album/_search?pretty‘ -d ‘ > "query": > "query_string": > "query":"late" > > > ‘ "took" : 11, "timed_out" : false, "_shards" : "total" : 5, "successful" : 5, "failed" : 0 , "hits" : "total" : 1, "max_score" : 0.095891505, "hits" : [ "_index" : "music", "_type" : "album", "_id" : "2", "_score" : 0.095891505, "_source" : "name" : "Late Night with Elasticsearch", "date" : "2019-06-24T22:17" ]
索引过程和搜索过程如下
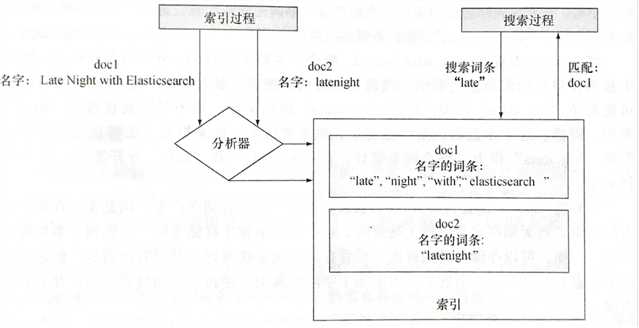
当索引"name":"Late Night with Elasticsearch"时,默认的分析器将所有字符转化为小写,然后将字符串分解为单词。
分析过程中生成了4个词条,即late、night、with和elasticsearch。查询的字符串经过同样的处理过程,”late”生成了同样的字符串”late”。因为查询生成的late词条和文档生成的late词条匹配了,所以文档(doc1)匹配上了搜索。doc2没有命中的原因是:在索引latenight时,默认的分析器只创建了一个词条--latenight。
一个词条是文本中的一个单词,是搜索的基本单位。在不同的情景下,单词可以意味着不同的事物,例如,它可以是一个名字,也可以是一个IP地址。如果只想严格匹配某个字段,应该将整个字段作为一个单词来对待。
映射会对这种分析过程起到作用。可以在映射中指定许多分析的选项。例如,可以配置分析,生成原始词条的同义词,这样同义词的查询同样可以匹配。
在设置映射时,有个index选项,可选值有:analyzed(默认)、not_analyzed或no。
将album类型的name字段设置为not_analyzed,映射如下
curl -XPUT ‘localhost:9200/music/_mapping/album‘ -d ‘ "album": "properties": "name": "type":"string", "index":"not_analyzed" ‘
index类型解释:
(1) analyzed:默认情况下,index会被设置为analyzed;分析器将所有字段转为小写,并将字符串分解为单词。当期望每个单词完整匹配时,可以使用此选项
如:期望通过”late”搜出"Late Night with Elasticsearch"
(2) not_analyzed:分析过程被忽略,整个字符串被当做单独的词条进行索引。当进行精准的匹配时,可使用此选项
如:期望通过”big data”搜出”big data”,通过”big”搜不出”big data”
(3) no : 如果设置为no,则索引过程会被略过,也没有词条产生,因此无法在那个字段上进行搜索。当无需在这个字段上搜索时,这个选项节省了存储空间,也缩短了索引和搜索的时间。
以上是关于Elasticsearch-用于定义文档字段的核心类型-字符串类型的主要内容,如果未能解决你的问题,请参考以下文章