多线程(十四ConcurrentHashMap原理一节点)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程(十四ConcurrentHashMap原理一节点)相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap介绍针对JDK1.8看ConcurrentHashMap是如何实现的
结构图:
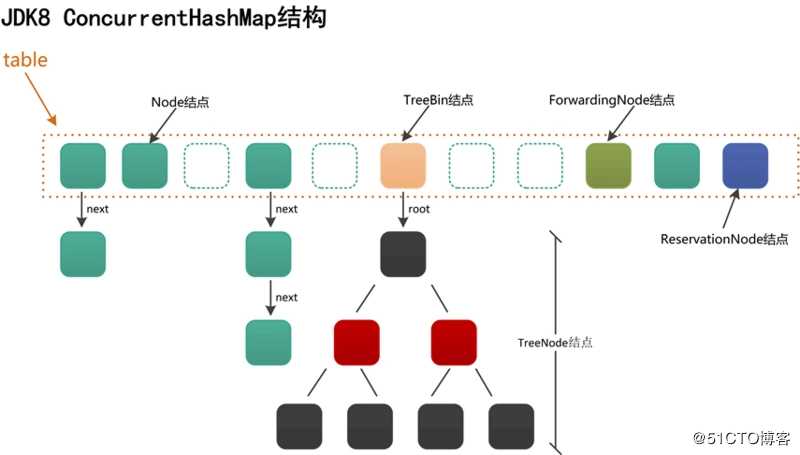
1、ConcurrentHashMap内部是一个Node节点的数组table,数组的每一个位置table[i]代表一个桶。根据键的hash值映射到不同的桶内。
transient volatile Node<K,V>[] table;2、Node节点一共有5种类型
1、Node节点,是所有节点的父类,可以单独放入桶内,也可以作为链表的头放入桶内。
2、TreeNode节点,继承自Node,是红黑树的节点,此节点不能直接放入桶内,只能是作为红黑树的节点。
3、TreeBin节点,TreeNode的代理节点,可以放入桶内,这个节点下面可以连接红黑树的根节点,所以叫做TreeNode的代理节点。
4、ForwardingNode节点,扩容节点,只是在扩容阶段使用的节点,当前桶扩容完毕后,桶内会放入这个节点,此时查询会跳转到查询扩容后的table,不存储实际数据
5、ReservationNode节点,内部方法使用,暂时可以忽略。
2.1 Node节点
默认桶上的结点就是Node结点。
当出现hash冲突时,Node结点会首先以链表的形式链接到table上,当结点数量超过一定数目时,链表会转化为红黑树。因为链表查找的平均时间复杂度为O(n),而红黑树是一种平衡二叉树,其平均时间复杂度为O(logn)。
Node只有一个next指针,是一个单链表,提供find方法实现链表查询
2.2 TreeNode节点
TreeNode就是红黑树的结点,TreeNode不会直接链接到table[i]——桶上面,而是由TreeBin链接,TreeBin会指向红黑树的根结点。
提供了基于树查找的findTreeNode方法。
2.3 TreeBin节点
TreeBin会直接链接到table[i]——桶上面,该结点提供了一系列红黑树相关的操作,以及加锁、解锁操作。
另外TreeBin提供了一系列的操作
1、TreeBin(TreeNode<K,V> b),将以b为头结点的链表转换为红黑树.
2、lockRoot(),对红黑树的根结点加写锁
3、unlockRoot(),释放写锁
4、find(int h, Object k),从根结点开始遍历查找,找到“相等”的结点就返回它,没找到就返回null,当存在写锁时,以链表方式进行查找,不阻塞读锁。
5、removeTreeNode(TreeNode<K, V> p),删除红黑树的结点:
- 红黑树规模太小时,返回true,然后进行 树 -> 链表 的转化
- 红黑树规模足够时,不用变换成链表,但删除结点时需要加写锁
6、红黑树的左旋,右旋等一系列算法。
2.4 ForwardingNode节点
1、ForwardingNode是一种临时结点,在扩容进行中才会出现,hash值固定为-1,且不存储实际数据。
2、如果旧table数组的一个hash桶中全部的结点都迁移到了新table中,则在这个桶中放置一个ForwardingNode。
3、读操作碰到ForwardingNode时,将操作转发到扩容后的新table数组上去执行;写操作碰见它时,则尝试帮助扩容,扩容是支持多线程一起扩容的。
4、提供了在新的数组nextTable上进行查找的方法find
2.5 ReservationNode节点
1、保留结点.
2、hash值固定为-3, 不保存实际数据
3、只在computeIfAbsent和compute这两个函数式API中充当占位符加锁使用
以上是关于多线程(十四ConcurrentHashMap原理一节点)的主要内容,如果未能解决你的问题,请参考以下文章
多线程(十五ConcurrentHashMap原理二类和方法分析)
Java多线程系列:ConcurrentHashMap的实现原理(JDK1.7和JDK1.8)
Java多线程系列:ConcurrentHashMap的实现原理(JDK1.7和JDK1.8)
Java多线程核心技术演进ConcurrentHashMap—Java进阶