音频特征:mfcc提取
Posted freeself
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频特征:mfcc提取相关的知识,希望对你有一定的参考价值。
除了调用FFmpeg来做多媒体开发,另一方面,是对音频特征进行研究。有很多具体的音频特征,比如频率、振幅、节拍(bpm)、过零率、短时能量、MFCC等,在很多时候,提取这些特征是进一步分析音频的基础。
如果你想对音频进行一个分类,比如分出快慢歌、分出爵士跟hiphop、分出钢琴与吉他、分出男高音与鸟叫声,等等,这时,基本上,你离不开音频特征的提取。在众多的音频特征中,频率与MFCC,是经常用到的两个特征。
本文主要介绍MFCC的概念,以及如何提取MFCC。
这里先回顾一下频率的概念,然后再介绍MFCC的提取。
(1)频率
频率,就是1秒内振动的次数。
音频的频率,反映了音调的高低,比如400HZ,相当于小蜜蜂嗡嗡的声音。
现在流行的机器学习,普遍以图片作为输入样本,所以把频率图像化是一个有效的办法。频率图像化,最自然的做法,就是绘制成频谱图,比如小程在另一篇文章介绍用python的pyplot来绘制,这个样子:
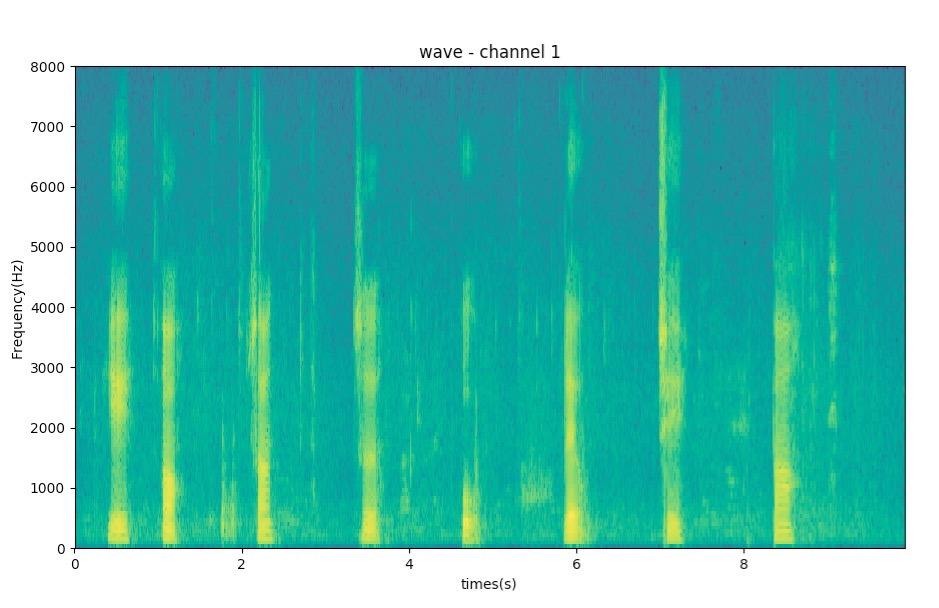
一般来说,用于机器学习时,并不能把整个语谱图作为输入,还需要进行合理的切片,甚至是清洗处理,然后再作为输入,但这个不是这里的内容。
(2)MFCC
MFCC,Mel-FrequencyCepstralCoefficients,缩写为MFCC,梅尔频率倒谱系数。
MFCC是一组特征向量,反映了频谱的轮廓(包络),可用于音色分类。从实用的角度,MFCCs,可以应用于音频分类的机器学习,作为输入样本数据。
接下来,小程使用python的librosa库,提取梅尔倒谱系数,并绘制成图片。跟上面介绍的频率一样,转成图片,是用于机器学习的一个有效的办法。
代码如下:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import numpy, scipy, librosa, audioread, wave
import librosa.display
import sys, os
def showmfcc(wavpath):
t, spe = librosa.load(wavpath)
mfccs = librosa.feature.mfcc(t, sr=spe)
print(mfccs.shape)
librosa.display.specshow(mfccs, sr=spe, x_axis='time')
plt.show()
def decode2wav(srcname, outname):
f = audioread.audio_open(filename)
nsample = 0
for buf in f:
nsample += 1
f.close()
with audioread.audio_open(filename) as f:
print("input file: channels=%d, samplerate=%d, duration=%d" % (f.channels, f.samplerate, f.duration))
channels = f.channels
samplewidth = 2
samplerate = f.samplerate
compresstype = "NONE"
compressname = "not compressed"
outwav = wave.open(outname, 'wb')
outwav.setparams((channels, samplewidth, samplerate, nsample, compresstype, compressname))
for buf in f:
outwav.writeframes(buf)
outwav.close()
def pcm2wav(srcname, outname, channels, samplewidth, samplerate):
fs = os.path.getsize(srcname)
nsample = fs / samplewidth
outwav = wave.open(outname, 'wb')
outwav.setparams((channels, samplewidth, samplerate, nsample, "NONE", "not cmopressed"))
fsrc = open(srcname, 'rb')
outwav.writeframes(fsrc.read())
fsrc.close()
outwav.close()
if __name__ == '__main__':
filename = sys.argv[1]
filename = os.path.abspath(os.path.expanduser(filename))
if not os.path.exists(filename):
print("input file not found, then exit")
exit(1)
path, ext = os.path.splitext(filename)
wavpath = path + ".wav"
if ext != '.wav':
if ext == ".pcm":
if len(sys.argv) < 5:
print("when input pcm, parameters should be [pcmfilename, channelcount, samplewidth_byte, samplerate]")
exit(1)
chcout = int(sys.argv[2])
bitwidth = int(sys.argv[3])
samplerate = int(sys.argv[4])
pcm2wav(filename, wavpath, chcout, bitwidth, samplerate)
else:
decode2wav(filename, wavpath)
showmfcc(wavpath)
上面的代码,有较大的幅度是在做音频转码,即转码成wav文件,这个跟“绘制音频的波形图”(另一篇文章)的处理一样。
实际上,librosa支持各种格式的解码,只要audioread能支持即可,所以并不需要特意转成wav再来调用librosa,只需要直接调用librosa即可。
关键的代码,也就是提取mfcc的代码,只有这一小部分:

执行这段代码,看到效果是这样的:

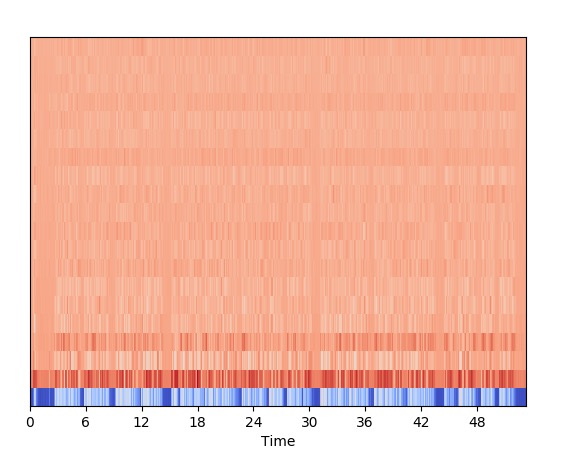
总结一下,本文简单介绍了MFCC的概念,并且使用librosa演示了MFCC提取的实现。频率与MFCC的提取,是许多音频分析工作的基础。

以上是关于音频特征:mfcc提取的主要内容,如果未能解决你的问题,请参考以下文章