JAVA自定义连接池原理设计
Posted boanxin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA自定义连接池原理设计相关的知识,希望对你有一定的参考价值。
一,概述
本人认为在开发过程中,需要挑战更高的阶段和更优的代码,虽然在真正开发工作中,代码质量和按时交付项目功能相比总是无足轻重。但是个人认为开发是一条任重而道远的路。现在本人在网上找到一个自定义连接池的代码,分享给大家。无论是线程池还是db连接池,他们都有一个共同的特征:资源复用,在普通的场景中,我们使用一个连接,它的生命周期可能是这样的:
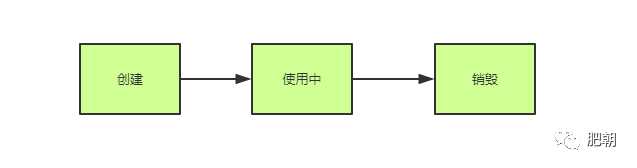
一个连接,从创建完毕到销毁,期间只被使用一次,当周期结束之后,另外的调用者仍然需要这个连接去做事,就要重复去经历这种生命周期。因为创建和销毁都是需要对应服务消耗时间以及系统资源去处理的,这样不仅浪费了大量的系统资源,而且导致业务响应过程中都要花费部分时间去重复的创建和销毁,得不偿失,而连接池便被赋予了解决这种问题的使命!
二,连接池简要需求
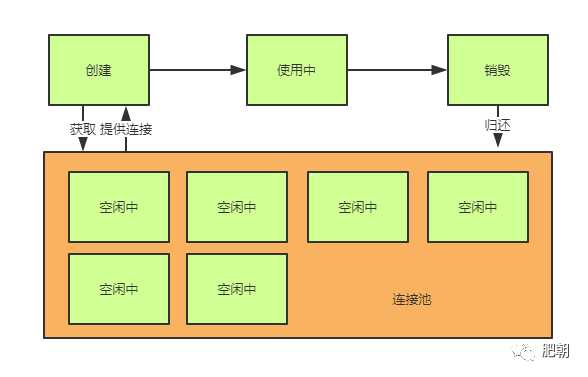
和原始周期相比,连接池多了一下特性:
1,创建并不是真的创建,而是从池子中选出空闲连接。
2,销毁并不是真的销毁,而是将使用中的连接放回池中。
3,真正的创建和销毁由线程池的特性机制来决定。
 ’
’
4,保存连接的容器是必不可少的,另外,该容器也要支持连接的添加和移除功能,并保证线程安全。
5,我们需要因为要对连接的销毁做逻辑调整,我们需要重写它的close以及isClosed方法。
6,我们需要有个入口对连接池做管理,例如回收空闲连接,连接池不仅仅只是对Connection生命周期的控制,还应该加入一些特色,例如初始连接数,最大连接数,最小连接数、最大空闲时长以及获取连接的等待时长,这些我们也简单支持一下。
容器连接池的选型:
1,要保证线程安全,我们可以将目标瞄准在JUC包下的神通们,设我们想要的容器为X,那么X不仅需要满足基本的增删改查功能,而且也要提供获取超时功能,这是为了保证当池内长时间没有空闲连接时不会导致业务阻塞,即刻熔断。另外,x需要满足双向操作,这是为了连接池可以识别出饱和的空闲连接,方便回收操作。
综上所述,LinkedBlockingDeque是最合适的选择,它使用InterruptibleReentrantLock来保证线程安全,使用Condition来做获取元素的阻塞,另外支持双向操作。
另外,我们可以将连接池分为3个类型:
工作池:存在正在被使用的连接。
空闲池:存在空闲连接。
回收池:已经被回收(物理关闭)的连接。
其中,工作池和回收池大可不必用双向队列,或许用单向队列或者set都可以代替之:
private LinkedBlockingQueue<HoneycombConnection> workQueue; private LinkedBlockingQueue<HoneycombConnection> idleQueue; private LinkedBlockingQueue<HoneycombConnection> freezeQueue;
Connection 的装饰
连接池的输出是Connection,它代表着一个db连接,上游服务使用它做完操作后,会直接调用它的close方法来释放连接,而我们必须做的是在调用者无感知的情况下改变它的关闭逻辑,当调用close的方法时,我们将它放回空闲队列中,保证其的可复用性!
因此,我们需要对原来的Connection做装饰,其做法很简单,但是很累,这里新建一个类来实现Connection接口,通过重写所有的方法来实现一个“可编辑”的Connection,我们称之为Connection的装饰者:
public class HoneycombConnectionDecorator implements Connection protected Connection connection; protected HoneycombConnectionDecorator(Connection connection) this.connection = connection; 此处省略对方法实现的三百行代码...
之后,我们需要新建一个自己的Connection来继承这个装饰者,并重写相应的方法:
public class HoneycombConnection extends HoneycombConnectionDecorator implements HoneycombConnectionSwitcher @Override public void close() do some things @Override public boolean isClosed() throws SQLException do some things 省略...
DataSource的重写
DataSource是JDK为了更好的统合和管理数据源而定义出的一个规范,获取连接的入口,方便我们在这一层更好的扩展数据源(例如增加特殊属性),使我们的连接池的功能更加丰富,我们需要实现一个自己的DataSource:
public class HoneycombWrapperDatasource implements DataSource protected HoneycombDatasourceConfig config; 省略其它方法的实现... @Override public Connection getConnection() throws SQLException return DriverManager.getConnection(config.getUrl(), config.getUser(), config.getPassword()); @Override public Connection getConnection(String username, String password) throws SQLException return DriverManager.getConnection(config.getUrl(), username, password); 省略其它方法的实现...
我们完成了对数据源的实现,但是这里获取连接的方式是物理创建,我们需要满足池化的目的,需要重写HoneycombWrapperDatasource中的连接获取逻辑,做法是创建一个新的类对父类方法重写:
public class HoneycombDataSource extends HoneycombWrapperDatasource private HoneycombConnectionPool pool; @Override public Connection getConnection() throws SQLException 这里实现从pool中取出连接的逻辑 省略...
特性扩展
在当前结构体系下,我们的连接池逐渐浮现出了雏形,但远远不够的是,我们需要在此结构下可以做自由的扩展,使连接池对连接的控制更加灵活,因此我们可以引入特性这个概念,它允许我们在其内部访问连接池,并对连接池做一系列的扩展操作:
public abstract class AbstractFeature public abstract void doing(HoneycombConnectionPool pool);
AbstractFeature抽象父类需要实现doing方法,我们可以在方法内部实现对连接池的控制,其中一个典型的例子就是对池中空闲连接左回收:
public class CleanerFeature extends AbstractFeature @Override public void doing(HoneycombConnectionPool pool) 这里做空闲连接的回收
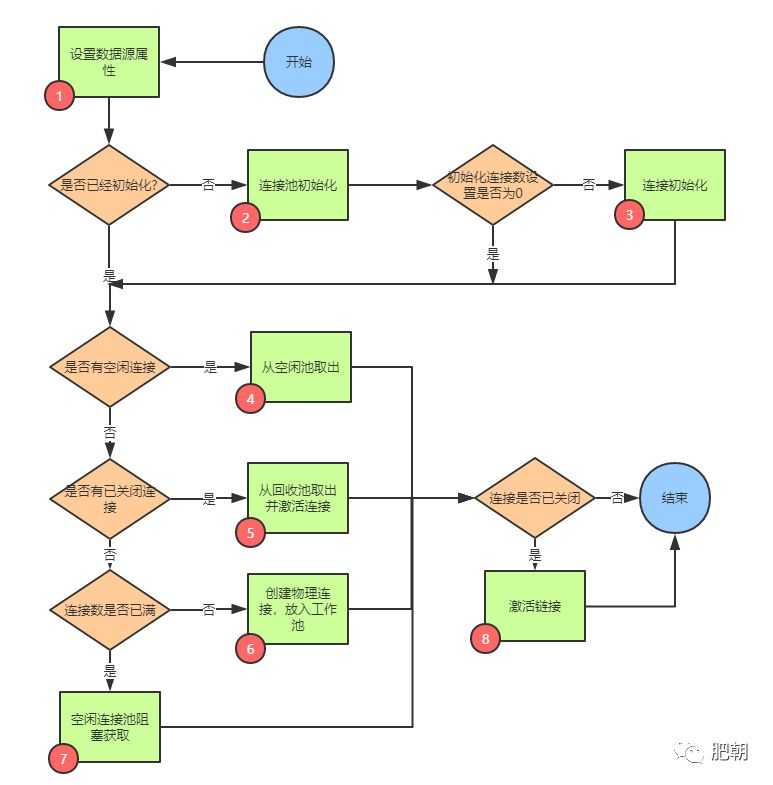
三,落实计划
以上是关于JAVA自定义连接池原理设计的主要内容,如果未能解决你的问题,请参考以下文章