python 字符串前加u r b的意义
Posted blogzyq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 字符串前加u r b的意义相关的知识,希望对你有一定的参考价值。
摘自:https://www.cnblogs.com/liangmingshen/p/9274021.html
1、字符串前加 u
例:u"我是含有中文字符组成的字符串。"
作用:
后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
2、字符串前加 r
例:r"\\n\\n\\n\\n” # 表示一个普通生字符串 \\n\\n\\n\\n,而不表示换行了。
作用:
去掉反斜杠的转移机制。
(特殊字符:即那些,反斜杠加上对应字母,表示对应的特殊含义的,比如最常见的”\\n”表示换行,”\\t”表示Tab等。 )
应用:
常用于正则表达式,对应着re模块。
3、字符串前加 b
例: response = b‘<h1>Hello World!</h1>‘ # b‘ ‘ 表示这是一个 bytes 对象
作用:
b" "前缀表示:后面字符串是bytes 类型。
用处:
网络编程中,服务器和浏览器只认bytes 类型数据。
如:send 函数的参数和 recv 函数的返回值都是 bytes 类型
附:
在 Python3 中,bytes 和 str 的互相转换方式是
str.encode(‘utf-8‘)
bytes.decode(‘utf-8‘)
字符串对象给人看的
字节对象是给计算机看的
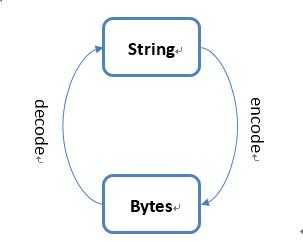
字符对象-->编码-->字节对象-->解码-->字符对象
acsii编码,只针对英文,一个Bytes代表一个字符
gb2312编码,支持中文,2Bytes代表一个字符
unicode编码,世界上的所有字符,2·4Bytes代表一个字符
utf-8是unicode的实现方式之一,对英文字符只用1Bytes表示,对中文字符用3Bytes
摘自:https://blog.csdn.net/hezh1994/article/details/78899683
以汉字“汉”为例,它的 Unicode 码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。这就导致了一些问题,计算机怎么知道你这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
UTF-8 是一个非常惊艳的编码方式,漂亮的实现了对 ASCII 码的向后兼容,以保证 Unicode 可以被大众接受。
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
Unicode 十六进制码点范围 UTF-8 二进制
0000 0000 - 0000 007F 0xxxxxxx
0000 0080 - 0000 07FF 110xxxxx 10xxxxxx
0000 0800 - 0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx
0001 0000 - 0010 FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
汉”的 Unicode 码点是 0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49 位于第三行的范围,那么得出其格式为 1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB7 0x89。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
以上是关于python 字符串前加u r b的意义的主要内容,如果未能解决你的问题,请参考以下文章