)
Posted the-wolf-sky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了)相关的知识,希望对你有一定的参考价值。
既然决定了以知识图谱作为研究方向,文献综述是必不可少的。
本文主要总结《知识图谱发展报告(2018)-中国中文信息学会》
1. 知识图谱的研究目标与意义 (略)
2. 知识工程的发展历程
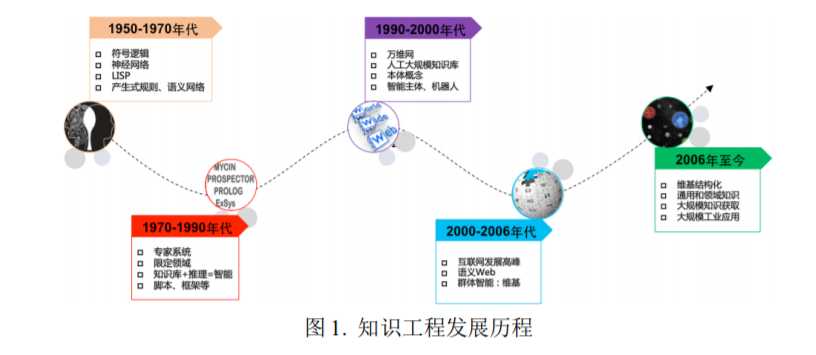
3. 知识图谱技术
人们通过概念掌握对客观世界的理解,概念是对客观世界事物的抽象,是将 人们对世界认知联系在一起的纽带。知识图谱以结构化的形式描述客观世界中概 念、实体及其关系。实体是客观世界中的事物,概念是对具有相同属性的事物的 概括和抽象。本体是知识图谱的知识表示基础,可以形式化表示为,O=C,H, P,A,I,
- C 为概念集合,如事物性概念和事件类概念,
- H 是概念的上下位关系 集合,也称为 Taxonomy 知识,
- P 是属性集合,描述概念所具有的特征,
- A 是规 则集合,描述领域规则,
- I 是实例集合,用来描述实例-属性-值。
Google 于 2012 年提出知识图谱,并在语义搜索中取得成功应用。知识图谱可以看做是本体知识 表示的一个大规模应用,Google 知识图谱的知识表示结构主要描述客观存在实体和实体的关系,对于每个概念都有确定的描述这个概念的属性集合。 知识图谱技术是知识图谱建立和应用的技术,是语义 Web、自然语言处理和 机器学习等的交叉学科。
我们将知识图谱技术分为三个部分 :
- 知识图谱构建技术
- 知识图谱查询和推理技术
- 知识图谱应用
在大数据环境下,从互联网开放 环境的大数据中获得知识,用这些知识提供智能服务互联网/行业,同时通过互 联网可以获得更多的知识。这是一个迭代的相互增强过程,可以实现从互联网信息服务到智能知识服务的跃迁。
3.1 知识图谱构建
知识表示与建模 知识表示将现实世界中的各类知识表达成计算机可存储和计算的结构。机器 必须要掌握大量的知识,特别是常识知识才能实现真正类人的智能。从有人工智 能的历史开始,就有了知识表示的研究。知识图谱的知识表示以结构化的形式描 述客观世界中概念、实体及其关系,将互联网的信息表达成更接近人类认知世界 的形式,为理解互联网内容提供了基础支撑。
知识表示学习 随着以深度学习为代表的表示学习的发展,面向知识图谱中实体和关系的表 示学习也取得了重要的进展。知识表示学习将实体和关系表示为稠密的低维向量, V 实现了对实体和关系的分布式表示,可以高效地对实体和关系进行计算,、缓解知 识稀疏、有助于实现知识融合,已经成为知识图谱语义链接预测和知识补全的重 要方法。由于知识表示学习能够显著提升计算效率,有效缓解数据稀疏,实现异 质信息融合,因此对于知识库的构建、推理和应用具有重要意义,值得广受关注、 深入研究。
实体识别与链接 实体是客观世界的事物,是构成知识图谱的基本单位(这里实体指个体或者 实例)。实体分为限定类别的实体(如常用的人名、地名、组织机构等)以及开 放类别实体(如药物名称、疾病等名称)。实体识别是识别文本中指定类别的实 体。实体链接是识别出文本中提及实体的词或者短语(称为实体提及),并与知 识库中对应实体进行链接。 实体识别与链接是知识图谱构建、知识补全与知识应用的核心技术。实体识 别技术可以检测文本中的新实体,并将其加入到现有知识库中。实体链接技术通 过发现现有实体在文本中的不同出现,可以针对性的发现关于特定实体的新知识。 实体识别与链接的研究将为计算机类人推理和自然语言理解提供知识基础。
实体关系学习 实体关系描述客观存在的事物之间的关联关系,定义为两个或多个实体之间 的某种联系,实体关系学习就是自动从文本中检测和识别出实体之间具有的某种语义关系,也称为关系抽取。实体关系抽取分类预定义关系抽取和开放关系抽取。 预定义关系抽取是指系统所抽取的关系是预先定义好的,比如知识图谱中定义好 的关系类别,如上下位关系、国家—首都关系等。开放式关系抽取。开放式关系抽取不预先定义抽取的关系类别,由系统自动从文本中发现并抽取关系。实体关 系识别是知识图谱自动构建和自然语言理解的基础。
事件知识学习 事件是促使事物状态和关系改变的条件,是动态的、结构化的知识。目前已 存在的知识资源(如谷歌知识图谱)所描述多是实体以及实体之间的关系,缺乏 对事件知识的描述。针对不同领域的不同应用,事件有不同的描述范畴。一种将 事件定义为发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个 或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。一种将事件 认为是细化了的主题,是由某些原因、条件引起,发生在特定时间、地点,涉及 某些对象,并 可能伴随某些必然结果的事情。事件知识学习,即将非结构化文本 文本中自然语言所表达的事件以结构化的形式呈现,对于知识表示、理解、计算 和应用意义重大。 知识图谱中的事件知识隐含互联网资源中,包括已有的结构化的语义知识、 VI 数据库的结构化信息、半结构化的信息资源以及非结构化资源,不同性质的资源 有不同的知识获取方法。
3.2 知识图谱查询和推理计算
知识存储和查询 知识图谱以图(Graph)的方式来展现实体、事件及其之间的关系。知识图 谱存储和查询研究如何设计有效的存储模式支持对大规模图数据的有效管理,实 现对知识图谱中知识高效查询。因为知识图谱的结构是复杂的图结构,给知识图 谱的存储和查询带来了挑战。当前目前知识图谱多以三元存在的 RDF 形式进行 存储管理,对知识图谱的查询支持 SPARQL 查询。
知识推理 知识推理从给定的知识图谱推导出新的实体跟实体之间的关系。知识图谱推 理可以分为基于符号的推理和基于统计的推理。在人工智能的研究中,基于符号 的推理一般是基于经典逻辑(一阶谓词逻辑或者命题逻辑)或者经典逻辑的变异 (比如说缺省逻辑)。基于符号的推理可以从一个已有的知识图谱推理出新的实体 间关系,可用于建立新知识或者对知识图谱进行逻辑的冲突检测。基于统计的方 法一般指关系机器学习方法,即通过统计规律从知识图谱中学习到新的实体间关 系。知识推理在知识计算中具有重要作用,如知识分类、知识校验、知识链接预 测与知识补全等。
3.3 知识图谱应用
通用和领域知识图谱 知识图谱分为通用知识图谱与领域知识图谱两类,两类图谱本质相同,其区 别主要体现在覆盖范围与使用方式上。通用知识图谱可以形象地看成一个面向通 用领域的结构化的百科知识库,其中包含了大量的现实世界中的常识性知识,覆 盖面广。领域知识图谱又叫行业知识图谱或垂直知识图谱,通常面向某一特定领 域,可看成是一个基于语义技术的行业知识库,因其基于行业数据构建,有着严 格而丰富的数据模式,所以对该领域知识的深度、知识准确性有着更高的要求。
语义集成 语义集成的目标就是将不同知识图谱融合为一个统一、一致、简洁的形式,为 使用不同知识图谱的应用程序间的交互提供语义互操作性。常用技术方法包括本体匹配(也称为本体 映射)、实例匹配(也称为实体对齐、对象共指消解)以及知识融合等。语义集成是知识图谱研究中的一个核心问题,对于链接数据和知识融合 至关重要。语义集成研究对于提升基于知识图谱的信息服务水平和智能化程度, VII 推动语义网以及人工智能、数据库、自然语言处理等相关领域的研究发展,具有 重要的理论价值和广泛的应用前景,可以创造巨大的社会和经济效益。
语义搜索 知识图谱是对客观世界认识的形式化表示,将字符串映射为客观事件的事务 (实体、事件以及之间的关系)。当前基于关键词的搜索技术在知识图谱的知识 支持下可以上升到基于实体和关系的检索,称之为语义搜索。语义搜索利用知识 图谱可以准确地捕捉用户搜索意图,借助于知识图谱,直接给出满足用户搜索意 图的答案,而不是包含关键词的相关网页的链接。
基于知识的问答 问答系统(Question Answering, QA)是指让计算机自动回答用户所提出的问 题,是信息服务的一种高级形式。不同于现有的搜索引擎,问答系统返回用户的不 再是基于关键词匹配的相关文档排序,而是精准的自然语言形式的答案。华盛顿 大学图灵中心主任 Etzioni 教授 2011 年曾在 Nature 上发表文章《Search Needs a Shake-Up》,其中明确指出:“以直接而准确的方式回答用户自然语言提问的自 动问答系统将构成下一代搜索引擎的基本形态”[Etzioni O., 2011]。因此,问答系 统被看做是未来信息服务的颠覆性技术之一,被认为是机器具备语言理解能力的 主要验证手段之一。
目录
第一章 知识表示与建模..............................................................................................1
第二章 知识表示学习................................................................................................12
第三章 实体识别与链接............................................................................................21
第四章 实体关系学习................................................................................................29
第五章 事件知识学习................................................................................................45
第六章 知识存储与查询............................................................................................65
第七章 知识推理........................................................................................................83
第八章 通用和领域知识图谱....................................................................................98
第九章 语义集成......................................................................................................124
第十章 语义搜索......................................................................................................134
第十一章 基于知识的问答......................................................................................145
第一章 知识表示与建模
1. 什么是知识表示?
上世纪 90 年代,MIT AI 实验室的 R. Davis 定义了知识表示的五大用途或 特点:
(1)客观事物的机器标示(A KR is a Surrogate),即知识表示首先需要定义 客观实体的机器指代或指称。
(2)一组本体约定和概念模型(A KR is a Set of Ontological Commitments), 即知识表示还需要定义用于描述客观事物的概念和类别体系。
(3)支持推理的表示基础(A KR is a Theory of Intelligent Reasoning),即知 识表示还需要提供机器推理的模型与方法。
(4)用于高效计算的数据结构(A KR is a medium for Efficient Computation), 即知识表示也是一种用于高效计算的数据结构。
(5)人可理解的机器语言(A KR is a Medium of Human Expression),即知 识表示还必须接近于人认知,是人可理解的机器语言。
不论是早期专家系统时代的知识表示方法,还是语义网时代的知识表示模型, 都属于以符号逻辑为基础的知识表示方法。符号知识表示的特点是易于刻画显性、 离散的知识,因而具有内生的可解释性。但由于人类知识还包含大量不易于符号 化的隐性知识,完全基于符号逻辑的知识表示通常由于知识的不完备而失去鲁棒 性,特别是推理很难达到实用。由此催生了采用连续向量方式来表示知识的研究。 基于向量的方式表示知识的研究由来已有。表示学习的发展,以及自然语言 处理领域词向量等嵌入(Embedding)技术手段的出现,启发了人们用类似于词 向量的低维稠密向量的方式表示知识的研究。通过嵌入(Embedding)将知识图 谱中的实体和关系投射到一个低维的连续向量空间,可以为每一个实体和关系学 习出一个低维度的向量表示。这种基于向量的知识表示可以实现通过数值运算来发现新事实和新关系,并能更有效的发现更多的隐性知识和潜在假设,这些隐性 知识通常是人的主观不易于观察和总结出来的。更为重要的是,知识图谱嵌入也 通常作为一种类型的先验知识辅助输入到很多深度神经网络模型中,用来约束和 监督神经网络的训练过程。

综上所述,知识图谱时代的知识表示方法与传统人工智能相比,已经发生了 很大的变化。一方面,现代知识图谱受到规模化扩展的要求,通常采用以三元组 为基础的较为简单实用的知识表示方法,并弱化了对强逻辑表示的要求;另外一 方面,由于知识图谱是很多搜索、问答和大数据分析系统的重要数据基础,基于 向量的知识图谱表示使得这些数据更加易于与深度学习模型集成,使得基于向量 空间的知识图谱表示得到越来越多的重视。 由于知识表示涉及大量传统人工智能的内容,并有其明确、严格的内涵及外 延定义,为避免混淆,本文主要侧重于知识图谱的表示方法的介绍,因此将“知 识表示”和“知识图谱的表示方法”加以了区分。
2. 知识图谱的表示方法
与传统专家系统时代的知识库不同,现代知识图谱通常规模巨大,这导致知 识图谱的表示方法也与传统的知识表示有所不同。下面从知识图谱的规模化发展 对知识表示带来的挑战出发,分别介绍了基于符号和基于向量的知识表示方法。
2.1 知识图谱的规模化带给知识表示的挑战
现代知识图谱对知识规模的要求源于“知识完备性”难题。冯诺依曼曾估计 单个个体的大脑中的全量知识需要 2.4*1020 个 bits 来存储。客观世界拥有不计 其数的实体,人的主观世界更加包含有无法统计的概念,这些实体和概念之间又 具有更多数量的复杂关系,导致大多数知识图谱都面临知识不完全的困境。在实 际的领域应用场景中,知识不完全也是困扰大多数语义搜索、智能问答、知识辅 助的决策分析系统的首要难题。
知识图谱对规模的扩展需求使得知识表示方法逐渐发生了四个方面的变化:
(1)从强逻辑表达转化为轻语义表达;
(2)从较为注重 TBox 概念型知识转化为更加注重 ABox 事实型知识;
(3)从以推理为主要应用目标转化为综合搜索、 问答、推理、分析等多方面的应用目标;
(4)从以离散的符号逻辑表示向以连续 的向量空间表示方向发展。
传统常识知识库如 Cyc 的知识表示语言主要以一阶谓词逻辑(FOPC)为基 础,扩展了等价(Equality)、缺省推理(Default reasoning)、斯科林化(Skolemization) 和部分二阶谓词逻辑等知识表示能力。基于描述逻辑(Description Logic)的本体 语言(Ontology),如 EL++,为可判定可扩展的自动推理提供了知识表示理论基 础,并更加侧重于 TBox 概念型知识。
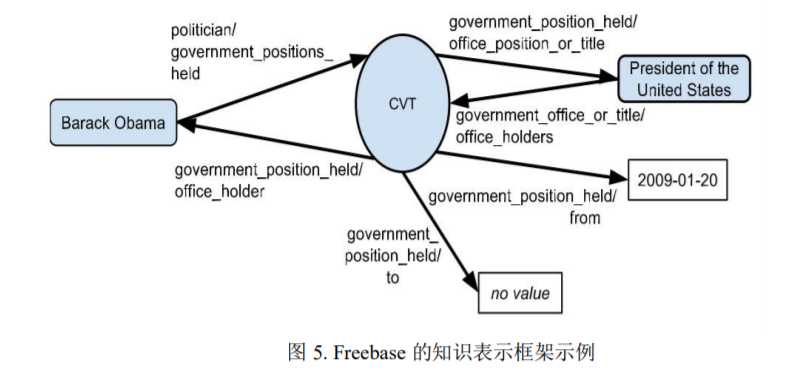
而现代知识图谱如 Freebase、Wikidata、Yago、Schema.Org 等都在逻辑的语 义表达方面降低了要求,并以事实型知识为主。例如,Freebase 的知识表示框架 只包含如下几个要素:
对象-Object
事实-Facts
类型-Types
属性-Properties
“Object”代表实体;一个“Object”可以有一个或多个“Types”;“Properties”用来描述 “Facts”;并使用复合值类型(CVT:Compound Value Types)来处理多元关系。 Schema.Org 只定义轻量的 Schema,突出 ABox 事实型数据的重要性。 此外,随着表示学习与深度神经网络的发展,一个重要的发展趋势是基于向量的知识表示方法得到越来越多的重视。传统基于逻辑的符号知识表示的优点是 基于显性知识表示,因而表示能力强,能处理较为复杂的知识结构,具有可解释 性,并支持复杂的推理。基于表示学习的连续向量表示优点是易于捕获隐性知识, 并易于与深度学习模型集成,缺点是对复杂知识结构的支持不够,可解释性差, 不能支持复杂推理。目前,基于符号和基于向量的知识图谱表示并存并逐步相互 融合。
2.2 基于符号的知识图谱表示方法
目前大多数知识图谱的实际存储方式都是以传统符号化的表示方法为主。大 多数开放域的知识图谱都是基于语义网的表示模型进行了扩展或删改。下面主要 以语义网的知识表示框架为例简要介绍基于符号的知识图谱表示方法。当然,语 义网只是符号知识表示框架和方法的一种。
RDF RDF是最常用的符号语义表示模型。RDF的基本模型是有向标记图(Directed Labeled Graph)。图中的每一条边对应于一个三元组(Subject-主语,Predicate-谓 语,Object-宾语)。一个三元组对于一个逻辑表达式或关于世界的陈述(Statement)。
RDFS RDF 提供了描述客观世界事实的基本框架,但缺少类、属性等 Schema 层的 定义手段。RDFS(RDF Schema)主要用于定义术语集、类集合和属性集合,主 要包括如下元语: Class, subClassOf, type, Property, subPropertyOf, Domain, Range 等。基于这些简单的表达构件可以构建最基本的类层次体系和属性体系。
OWL OWL 主要在 RDFS 基础之上扩展了表示类和属性约束的表示能力,这使得 可以构建更为复杂而完备的本体。这些扩展的本体表达能力包括:
1) 复杂类表达 Complex Classes,如:intersection, union 和 complement 等;
2) 属性约束 Property Restrictions,如:existential quantification, universal quantification, hasValue 等;
3) 基数约束 Cardinality Restrictions , 如 : maxQualifiedCardinality, minQualifiedCardinality, qualifiedCardinality 等;
4) 属性特征 Property Characteristics,如:inverseOf, SymmetricProperty, AsymmetricProperty, propertyDisjointWith, ReflexiveProperty, FunctionalProperty 等。
OWL 以描述逻辑为主要理论基础,在很多领域知识图谱的构建,如医疗、 金融、电商等有实际应用的价值。
2.3 基于向量的知识图谱表示学习模型
依据知识图谱嵌入表示模型建模原理将基于向量的知识表示模型划分为翻译模型、组合模型、神经网络模型。
翻译模型 的灵感来自 word2vec 中词汇关系 的平移不变性,典型的方法包括基于向量的三角形法则和范数原理的 TransE 模 型,通过超平面转化或线性变换处理多元关系的 TransH、TransR 和 TransD 模型, 通过增加一个稀疏度参数向量解决异构多元关系的 TranSparse 模型等。
组合模型 采用的是向量的线性组合和点积原理,典型特征是将实体建模为列 向量、关系建模为矩阵,然后通过头实体向量与关系矩阵的线性组合,再与尾实 体进行点积来计算打分函数。经典成员包括采用普通矩阵的 RESCAL、采用低秩 矩阵的 LFM、采用对角矩阵的 DistMult 和采用循环矩阵的 HolE。
神经网络模型 采用神经网络拟合三元组,典型模型包括采用单层线性或双线性网络的 SME、 采用单层非线性网络的 SLM、NTN 和 MLP,以及采用多层网络结构的 NAM 。 下一章对知识图谱的表示学习模型进行了详细介绍,此处不再赘述。
3. 常见知识库及知识图谱的知识表示方法
从人工智能的概念被提出开始,构建大规模的知识库一直都是人工智能、自 然语言理解等领域的核心任务之一。下面分别介绍了早期知识库和以语义网为基 础构建的知识图谱项目所采用的知识表示方法。不同的知识图谱项目都会根据实 际的需要选择不同的知识表示框架。这些框架有着不同的描述术语、表达能力、 数据格式等方面的考虑,但本质上有相似之处。
3.1 早期的知识库项目
Cyc 是持续时间最久,影响范围较广,争议也较多的知识库项目。Cyc 是在 1984 年由 Douglas Lenat 开始创建。最初的目标是要建立人类最大的常识知识库。 典型的常识知识如“Every tree is a plant” ,”Plants die eventually”等。Cyc 知识库 的知识表示框架主要由术语 Terms 和断言 Assertions 组成。Terms 包含概念、关 系和实体的定义。Assertions 用来建立 Terms 之间的关系,这既包括事实 Fact 描 述,也包含规则 Rule 的描述。最新的 Cyc 知识库已经包含有 50 万条 Terms 和 700 万条 Assertions。Cyc 的主要特点是基于形式化的知识表示方法来刻画知识。 形式化的优势是可以支持复杂的推理。但过于形式化也导致知识库的扩展性和应 用的灵活性不够。Cyc 提供开放版本 OpenCyc。
WordNet 是最著名的词典知识库,主要用于词义消歧。WordNet 由普林斯顿 大学认识科学实验室从1985年开始开发。WordNet的表示框架主要定义了名词、 动词、形容词和副词之间的语义关系。例如名词之间的上下位关系(如:“猫科 动物”是“猫”的上位词),动词之间的蕴含关系(如:“打鼾”蕴含着“睡眠”)等。 WordNet3.0 已经包含超过 15 万个词和 20 万个语义关系。
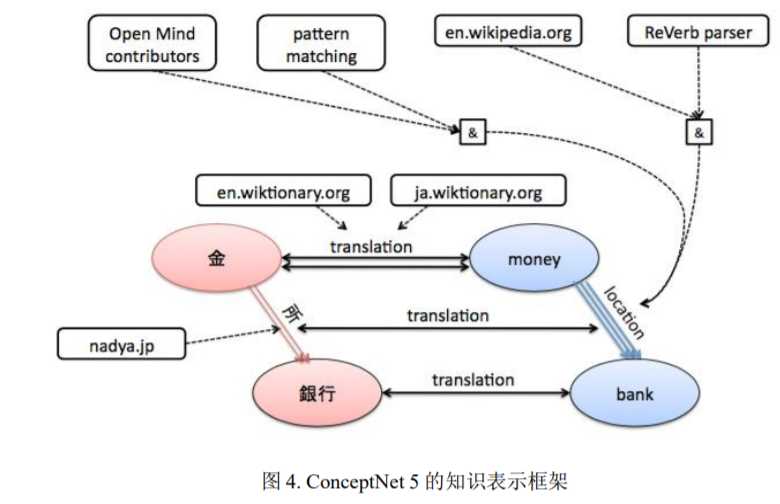
ConceptNet 是常识知识库。最早源于 MIT 媒体实验室的 Open Mind Common Sense (OMCS)项目。OMCS 项目是由著名人工智能专家 Marvin Minsky 于 1999 年建议创立。ConceptNet 主要依靠互联网众包、专家创建和游戏三种方法来构建。 ConceptNet 知识库以三元组形式的关系型知识构成。ConceptNet 5 版本已经包含 有 2800 万关系描述。与 Cyc 相比,ConceptNet 采用了非形式化、更加接近自然语言的描述,而不是像 Cyc 那样采用形式化的谓词逻辑。与链接数据和谷歌知识 图谱相比,ConceptNet 比较侧重于词与词之间的关系。从这个角度看,ConceptNet 更加接近于 WordNet,但是又比 WordNet 包含的关系类型多。此外,ConceptNet 完全免费开放,并支持多种语言。
ConceptNet5 的知识表示框架主要包含如下要素:概念-Concepts、词-Words、 短语-Phrases、断言 Assertions、关系-Relations、边-Edges。Concepts 由 Words 或 Phrases 组成,构成了图谱中的节点。与其它知识图谱的节点不同,这些 Concepts 通常是从自然语言文本中提取出来的,更加接近于自然语言描述,而不是形式化 的命名。Assertions 描述了 Concepts 之间的关系,类似于 RDF 中的 Statements。 Edges 类似于 RDF 中的 Property。一个 Concepts 包含多条边,而一条边可能有多 个产生来源。例如,一个“化妆 Cause 漂亮”的断言可能来源于文本抽取,也可 能来源于用户的手工输入。来源越多,该断言就越可靠。ConceptNet 根据来源的 多少和可靠程度计算每个断言的置信度。ConceptNet5 中的关系包含 21 个预定义 的、多语言通用的关系(如:IsA、UsedFor 等)和从自然语言文本中抽取的更加 接近于自然语言描述的非形式化的关系(如:on top of,caused by 等)。 ConceptNet5 对 URI 进行了精心的设计。URI 同时考虑了类型(如,是概念还是 关系)、语言、正则化后的概念名称、词性、歧义等因素。例如“run”是一个动词, 但 也 可 能 是 一 个 名 词 ( 如 basement 比 赛 中 一 个 “run” ), 其 URI 为 : “/c/en/run/n/basement”。其中,n 代指这是一个名词,basement 用于区分歧义。在 处理表示“x is the first argument of y ”这类多元关系的问题上,ConceptNet5 把所 有关于某条边的附加信息增加为边的属性。
3.2 语义网与知识图谱
互联网的发展为知识工程提供了新的机遇。在一定程度上,是互联网的出现 帮助突破了传统知识工程在知识获取方面的瓶颈。从 1998 年 Tim Berners Lee 提 出语义网至今,涌现出大量以互联网资源为基础的新一代知识库。这类知识库的 构建方法可以分为三类:互联网众包、专家协作和互联网挖掘。
Freebase 是一个开放共享的、协同构建的大规模链接数据库。Freebase 是由 硅谷创业公司 MetaWeb 于 2005 年启动的一个语义网项目。2010 年,谷歌收购了 Freebase 作为其知识图谱数据来源之一。Freebase 主要采用社区成员协作方式构 建。其主要数据来源包括维基百科 Wikipedia、世界名人数据库 NNDB、开放音 乐数据库 MusicBrainz,以及社区用户的贡献等。Freebase 基于 RDF 三元组模型, 底层采用图数据库进行存储。Freebase 的一个特点是不对顶层本体做非常严格的 控制,用户可以创建和编辑类和关系的定义。2016 年,谷歌宣布将 Freebase 的 数据和 API 服务都迁移至 Wikidata,并正式关闭了 Freebase。Freebase 的知识表示框架主要包含如下几个要素:对象-Object,事实-Facts, 类型-Types 和属性-Properties。“Object”代表实体。每一个“Object”有一个唯一的 ID,称为 MID(Machine ID)。一个“Object”可以有一个或多个“Types”。“Properties” 用来描述“Facts”。例如:“Barack Obama”是一个 Object,并拥有一个唯一的 MID: “/m/02mjmr” 。这个 Object 的一个 type 是“/government/us_president”,并有一个 称为“/government/us_president/presidency_number”的 Property,其数值是“44”。 Freebase 使用复合值类型(CVT:Compound Value Types )来处理多元关系。 例如下面这个例子中的 CVT 描述了关于 Obama 的任职期限的多元关系 “government_position_held”。这个多元关系包含多个子二元关系:“office_holder”, “office_position”,“from”,“to”等。一个 CVT 就是一个有唯一 MID 的 Object, 也可以有多个 Types。为了以示区别,Freebase 把所有非 CVT 的 Object 也称为 “Topic”。
DBPedia 是早期的语义网项目。DBPedia 意指数据库版本的 Wikipedia,是从 Wikipedia 抽取出来的链接数据集。DBPedia 采用了一个较为严格的本体,包含 人、地点、音乐、电影、组织机构、物种、疾病等类定义。此外,DBPedia 还与 Freebase,OpenCYC、Bio2RDF 等多个数据集建立了数据链接。DBPedia 采用了 RDF 语义数据模型,总共包含 30 亿 RDF 三元组。
Schema.org:Schema.org 是 2011 年起,由 Bing、Google、Yahoo 和 Yandex 等搜索引擎公司共同支持的语义网项目。Schema.org 支持各个网站采用语义标签 (Semantic Markup)的方式将语义化的链接数据嵌入到网页中。搜索引擎自动搜 集和归集这些,快速的从网页中抽取语义化的数据。Schema.org 提供了一个词汇 本体用于描述这些语义标签。截止目前,这个词汇本体已经包含 600 多个类和 900 多个关系,覆盖范围包括:个人、组织机构、地点、时间、医疗、商品等。 谷歌于 2015 年推出的定制化知识图谱支持个人和企业在其网页中增加包括企业 联系方法、个人社交信息等在内的语义标签,并通过这种方式快速的汇集高质量 的知识图谱数据。
WikiData: WikiData 的目标是构建一个免费开放、多语言、任何人或机器都 可以编辑修改的大规模链接知识库。WikiData 由维基百科于 2012 年启动,早期 得到微软联合创始人 Paul Allen、Gordon Betty Moore 基金会以及 Google 的联合 资助。WikiData 继承了 Wikipedia 的众包协作的机制,但与 Wikipedia 不同, WikiData 支持的是以三元组为基础的知识条目(Items)的自由编辑。一个三元 组代表一个关于该条目的陈述(Statements)。例如可以给“地球”的条目增加“<地 球,地表面积是,五亿平方公里>”的三元组陈述。截止 2016 年,WikiData 已经 包含超过 2470 多万个知识条目。 WikiData 的知识表示框架主要包含如下要素:页面-Pages,实体-Entities,条 目-Items,属性-Properties,陈述-Statements,修饰-Qualifiers,引用-Reference 等。 WikiData 起源于 Wikipedia,因此,与 Wikipedia 一样,是以页面“Page”为基本组 织单元。Entities 类似于 OWL: Things,代指最顶层的对象。每一个 Entity 都有一 个独立的维基页面。主要有两类 Entities:Items 和 Properties。Item 类似于 RDF 中的 Instance,代指实例对象。Properties 和 Statement 分别等价于 RDF 中的 Property 和 Statement。通常一个 Item 的页面还包含有多个别名-aliases 和多个指 向维基百科的外部链接-Sitelinks。每个 Entities 有多个 Statements。一个 Statement 包含:一个 Property、一个或多个 Values、一个或多个 Qualifiers,一个或多个 References、一个标示重要性程度的 Rank。修饰-Qualifiers 用于处理复杂的多元 表示。如下图中的一个陈述“spouse: Jane Belson”描述了一个二元关系。我们可以 使用 Qualifiers 给这个陈述增加多个附加信息来刻画多元关系,如:“start date: 25 November 1991” and “end date: 11 May 2011,”等。引用-References 用于标识每个陈述的来源或出处,如来源于某个维基百科页面等。引用也是一种 Qualifiers,通 常添加到 Statements 的附加信息中。WikiData 支持多种数值类型,包括:其自有 的 Item 类型、RDF Literal、URL、媒体类型 Commons Media 和三种复杂类型: Time、Globe coordinates 和 Quantity。WikiData 允许给每个 Statement 增加三种权 重:normal(缺省),preferred 和 deprecated。WikiData 定义了三种 Snacks 作为 Statement 的 具 体 描 述 结 构 : PropertyValueSnack 、 PropertyNoValueSnack 、 PropertySomeValueSnack。“PropertyNoValueSnack”类似于 OWL 中的“Negation”, 用于表示类似于 ““Elizabeth I of England had no spouse.” 的知识 。 “PropertySomeValueSnack’类似于 OWL 中的存在量词“someValuesFrom”,用于表 示类似于“Pope Linus had a date of birth, but it is unknown to us”这样的知识。 WikiData 的 URI 机制遵循了 Linked Open Data 的 URI 原则,采用统一的 URI 机 制:http://www.wikidata.org/entity/。其中可以是一个 Item,如 Q49,或 者是一个 Property,如 P234。
4. 总结
具有获取、表示和处理知识的能力是人类心智区别于其它物种心智的重要特 征。人工智能的一个核心也是研究怎样用计算机易于处理的方式表示、学习和处 理各种各样的人类知识。知识表示是现实世界的可计算模型,广义的讲,神经网 络也是一种知识表示形式。 与传统专家系统时代的知识库表示方法不同,现代知识图谱由于要满足规模 化的扩建需求,大多降低了对强逻辑表达的要求,并以三元组为基础的关系型知 识为主。并更多的关注实例层面的知识构建。另外一方面,由于知识图谱是很多 搜索、问答和大数据分析系统的重要数据基础,基于向量的知识图谱表示使得这 些数据更加易于与深度学习模型集成,使得基于向量空间的知识图谱表示得到越 来越多的重视。 此外,围绕知识图谱表示的一个重要的研究趋势和动态是:把符号逻辑与表 示学习结合起来研究更加鲁棒、易于捕获隐含知识、易于与深度学习集成、并适 应大规模知识图谱应用的新型表示框架。这需要较好的平衡符号逻辑的表示能力 和表示学习模型的复杂性。一方面要能处理结构多样性、捕获表达构件的语义和 支持较为复杂的推理,另一方面又要求学习模型的复杂性较低。这些新型的表示 框架的研究对于知识图谱构建所涉及的抽取、融合、补全、问答和分析等任务都 具有重要的基础性研究意义。
以上是关于)的主要内容,如果未能解决你的问题,请参考以下文章