机器翻译注意力机制及其PyTorch实现
Posted jfdwd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器翻译注意力机制及其PyTorch实现相关的知识,希望对你有一定的参考价值。
前面阐述注意力理论知识,后面简单描述PyTorch利用注意力实现机器翻译
Effective Approaches to Attention-based Neural Machine Translation
简介
Attention介绍
在翻译的时候,选择性的选择一些重要信息。详情看这篇文章 。
本着简单和有效的原则,本论文提出了两种注意力机制。
Global
每次翻译时,都选择关注所有的单词。和Bahdanau的方式 有点相似,但是更简单些。简单原理介绍。
Local
每次翻译时,只选择关注一部分的单词。介于soft和hard注意力之间。(soft和hard见别的论文)。
优点有下面几个
- 比Global和Soft更好计算
- 局部注意力 随处可见、可微,更好实现和训练。
应用范围
在训练神经网络的时候,注意力机制应用十分广泛。让模型在不同的形式之间,学习对齐等等。有下面一些领域:
- 机器翻译
- 语音识别
- 图片描述
- between image objects and agent actions in the dynamic control problem (不懂,以后再说吧)
神经机器翻译
思想
输入句子x=(x1,x2,?,xn)x=(x1,x2,?,xn) ,输出目标句子y=(y1,y2,?,ym)y=(y1,y2,?,ym) 。
神经机器翻译(Neural machine translation, NMT),利用神经网络,直接对p(y∣x)p(y∣x) 进行建模。一般由Encoder和Decoder构成。Encoder-Decoder介绍文章链接 。
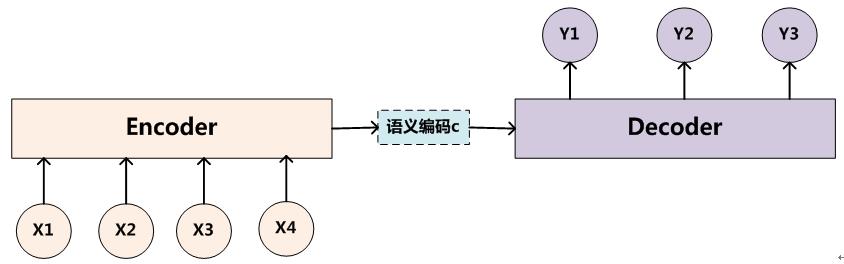
Encoder把输入句子xx 编码成一个语义向量ss (c表示也可以),然后由Decoder 一个一个产生目标单词 yiyilogp(y∣x)=m∑j=1logp(yj∣y<j,s)=m∑j=1logp(yj∣y1,?,yj−1,s)log?p(y∣x)=∑j=1mlog?p(yj∣y<j,s)=∑j=1mlog?p(yj∣y1,?,yj−1,s)但是怎么选择Encoder和Decoder(RNN, CNN, GRU, LSTM),怎么去生成语义ss却有很多选择。
概率计算
结合Decoder上一时刻的隐状态hj−1hj−1和encoder给的语义向量ss,通过函数ff ,就可以计算出当前的隐状态hjhj :hj=f(hj−1,s)hj=f(hj−1,s)通过函数gg对当前隐状态hjhj进行转换,再softmax,就可以得到翻译的目标单词yiyi了(选概率最大的那个)。
gg一般是线性变换,维数变化是[1,h]→[1,vocab_size][1,h]→[1,vocab_size]。p(yj∣y<j,s)=softmaxg(hj)p(yj∣y<j,s)=softmaxg(hj)语义向量ss? 会贯穿整个翻译的过程,每一步翻译都会使用到语义向量的内容,这就是注意力机制。
本论文的模型
本论文采用stack LSTM的构建NMT系统。如下所示:
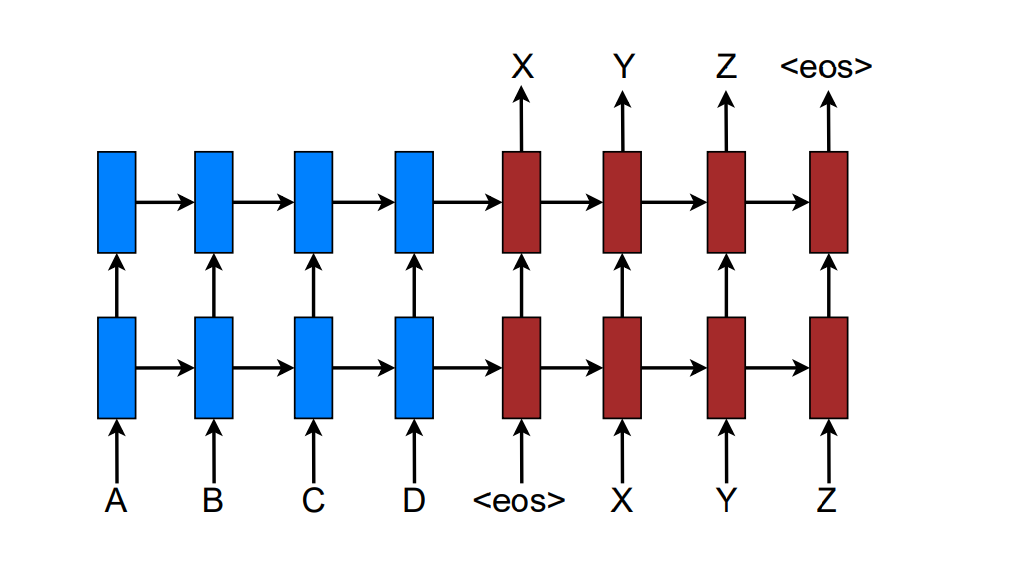
训练目标是Jt=∑(x,y)−logp(y∣x)Jt=∑(x,y)−log?p(y∣x)
注意力模型
注意力模型广义上分为global和local。Global的attention来自于整个序列,而local的只来自于序列的一部分。
解码总体流程
Decoder时,在时刻tt,要翻译出单词ytyt ,如下步骤:
- 最顶层LSTM的隐状态 htht
- 计算带有原句子信息语义向量ctct。Global和Local的区别在于ctct的计算方式不同
- 串联ht,ctht,ct,计算得到带有注意力的隐状态 ^ht=tanh(Wc[ct;ht])h^t=tanh?(Wc[ct;ht])
- 通过注意力隐状态得到预测概率 p(yt∣y<t,x)=softmax(Ws^ht)p(yt∣y<t,x)=softmax(Wsh^t)
Global Attention
总体思路
在计算ctct 的时候,会考虑整个encoder的隐状态。Decoder当前隐状态htht, Encoder时刻s的隐状态¯hsh¯s。
对齐向量αtαt代表时刻tt 输入序列中的单词对当前单词ytyt 的对齐概率,长度是TxTx, 随着输入句子的长度而改变 。xsxs与ytyt 的对齐概率如下:αt(s)=align(ht,¯hs)=score(ht,¯hs)∑Txi=1score(ht,¯hi),实