目标检测评价指标
Posted wkcode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测评价指标相关的知识,希望对你有一定的参考价值。
转:https://blog.csdn.net/syoung9029/article/details/56276567
召回率(Recall),精确率(Precision),平均正确率(AP),交除并(IoU)
摘要
在训练YOLO v2的过程中,系统会显示出一些评价训练效果的值,如Recall,IoU等等。为了怕以后忘了,现在把自己对这几种度量方式的理解记录一下。
这一文章首先假设一个测试集,然后围绕这一测试集来介绍这几种度量方式的计算方法。
大雁与飞机
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示: 
假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
现在做如下的定义:
True positives : 飞机的图片被正确的识别成了飞机。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
假设你的分类系统使用了上述假设识别出了四个结果,如下图所示: 
那么在识别出的这四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
没被识别出来的六张图片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
Precision 与 Recall
Precision其实就是在识别出来的图片中,True positives所占的比率: 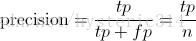
其中的n代表的是(True positives + False positives),也就是系统一共识别出来多少照片 。
在这一例子中,True positives为3,False positives为1,所以Precision值是 3/(3+1)=0.75。
意味着在识别出的结果中,飞机的图片占75%。
Recall 是被正确识别出来的飞机个数与测试集中所有飞机的个数的比值: 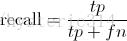
Recall的分母是(True positives + False negatives),这两个值的和,可以理解为一共有多少张飞机的照片。
在这一例子中,True positives为3,False negatives为2,那么Recall值是 3/(3+2)=0.6。
意味着在所有的飞机图片中,60%的飞机被正确的识别成飞机.。
调整阈值
你也可以通过调整阈值,来选择让系统识别出多少图片,进而改变Precision 或 Recall 的值。
在某种阈值的前提下(蓝色虚线),系统识别出了四张图片,如下图中所示: 
分类系统认为大于阈值(蓝色虚线之上)的四个图片更像飞机。
我们可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
下图为不同阈值条件下,Precision与Recall的变化情况: 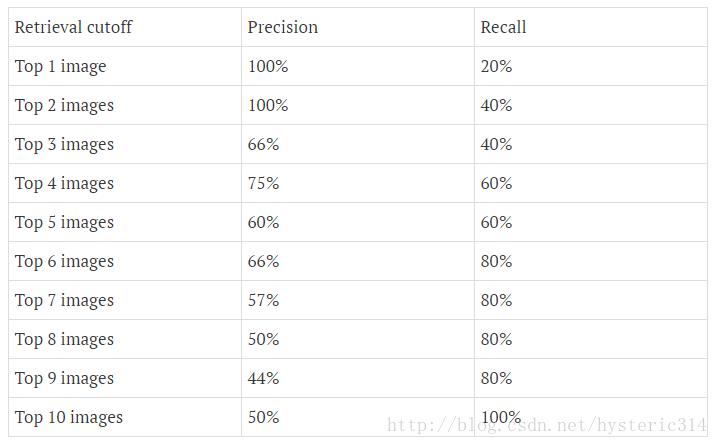
Precision-recall 曲线
如果你想评估一个分类器的性能,一个比较好的方法就是:观察当阈值变化时,Precision与Recall值的变化情况。如果一个分类器的性能比较好,那么它应该有如下的表现:被识别出的图片中飞机所占的比重比较大,并且在识别出大雁之前,尽可能多地正确识别出飞机,也就是让Recall值增长的同时保持Precision的值在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。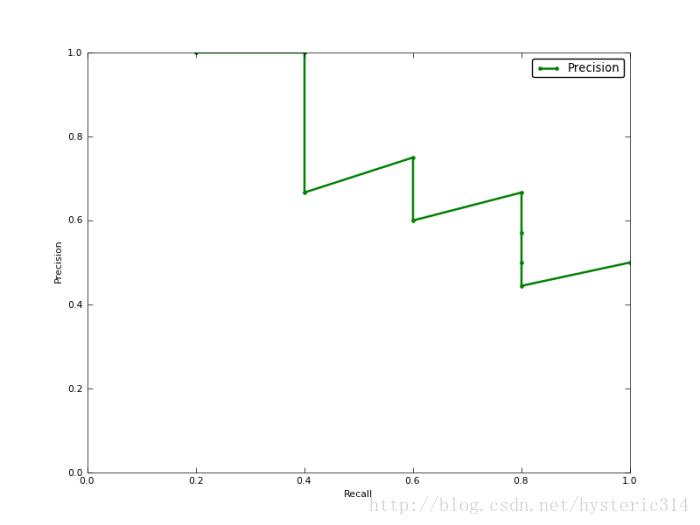
上图就是分类器的Precision-recall 曲线,在不损失精度的条件下它能达到40%Recall。而当Recall达到100%时,Precision 降低到50%。
Approximated Average precision
相比较与曲线图,在某些时候还是一个具体的数值能更直观地表现出分类器的性能。通常情况下都是用 Average Precision来作为这一度量标准,它的公式为: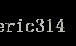
在这一积分中,其中p代表Precision ,r代表Recall,p是一个以r为参数的函数,That is equal to taking the area under the curve.
实际上这一积分极其接近于这一数值:对每一种阈值分别求(Precision值)乘以(Recall值的变化情况),再把所有阈值下求得的乘积值进行累加。公式如下: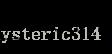
在这一公式中,N代表测试集中所有图片的个数,P(k)表示在能识别出k个图片的时候Precision的值,而 Delta r(k) 则表示识别图片个数从k-1变化到k时(通过调整阈值)Recall值的变化情况。
在这一例子中,Approximated Average Precision的值
=(1 * (0.2-0)) + (1 * (0.4-0.2)) + (0.66 * (0.4-0.4)) + (0.75 * (0.6-0.4)) + (0.6 * (0.6-0.6)) + (0.66 * (0.8-0.6)) + (0.57 * (0.8-0.8)) + (0.5 * (0.8-0.8)) + (0.44 * (0.8-0.8)) + (0.5 * (1-0.8)) = 0.782.
=(1 * 0.2) + (1 * 0.2) + (0.66 * 0) + (0.75 * 0.2) + (0.6 *0) + (0.66 * 0.2) + (0.57 *0) + (0.5 *0) + (0.44 *0) + (0.5 * 0.2) = 0.782.
通过计算可以看到,那些Recall值没有变化的地方(红色数值),对增加Average Precision值没有贡献。
Interpolated average precision
不同于Approximated Average Precision,一些作者选择另一种度量性能的标准:Interpolated Average Precision。这一新的算法不再使用P(k),也就是说,不再使用当系统识别出k个图片的时候Precision的值与Recall变化值相乘。而是使用:
也就是每次使用在所有阈值的Precision中,最大值的那个Precision值与Recall的变化值相乘。公式如下: 
下图的图片是Approximated Average Precision 与 Interpolated Average Precision相比较。
需要注意的是,为了让特征更明显,图片中使用的参数与上面所说的例子无关。 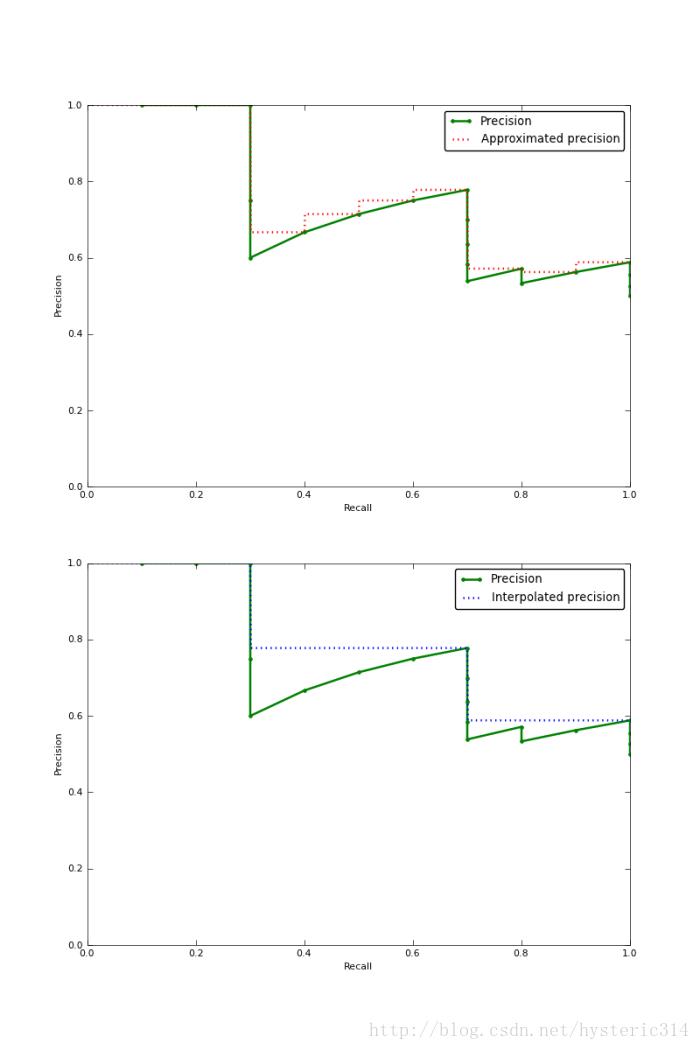
很明显 Approximated Average Precision与精度曲线挨的很近,而使用Interpolated Average Precision算出的Average Precision值明显要比Approximated Average Precision的方法算出的要高。
一些很重要的文章都是用Interpolated Average Precision 作为度量方法,并且直接称算出的值为Average Precision 。PASCAL Visual Objects Challenge从2007年开始就是用这一度量制度,他们认为这一方法能有效地减少Precision-recall 曲线中的抖动。所以在比较文章中Average Precision 值的时候,最好先弄清楚它们使用的是那种度量方式。
IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。
计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率:
如下图所示:
蓝色的框是:GroundTruth
黄色的框是:DetectionResult
绿色的框是:DetectionResult ?GroundTruth
红色的框是:DetectionResult ?GroundTruth

转:https://blog.csdn.net/linchunmian/article/details/79644300
1. PR曲线(Precision&Recall)
首先需要了解几个概念。
True positive(TP): 预测为positive ground truth为True
True negative(TN): 预测为positive 但ground truth 为negative
False positive(FP): 预测为positive 但ground truth 为negative
False negative(FN): 预测为negative ground truth也为False
precision: 查准率,指预测为positive中,ground truth是positive所占的比例 (TP/(TP+FP)),该值越大越好,1为理想状态
recall: 查全率,指所有的True样本中,预测为positive所占的比例(TP/(TP+FN)),该值越大越好,1为理想状态
F1-score: 将precision 和recall合成一个指标,越大越好
accuracy: 所有预测结果与实际结果一样的样本/所有样本
FP Rate(FPR): false positive占整个negative的比例,就是说原本是negative 预测为positive的比例,越小越好
TP Rate(TPR): true positive 占整个positive 的比例
PR曲线:(precision,recall)曲线,越凸向右上方效果越好
AP:PR曲线下的面积
AUC: Area Under the Curve 是一个抽象的概念,并不单指ROC曲线下的面积
通过计算每个样本的TP, FP, TN, FN的值,得到每个样本对应的(P, R)值对,从而可以绘制PR曲线图。PR曲线的一般趋势是向右上方凸起的一条曲线,最右上方凸起点成为平衡点,该点的p、r坐标值越大越好,表示检测器性能在该点达到平衡状态,既保证高精确度又保证高召回率。
此外,F1-score的计算公式为F1 = 2 * p * r* (p+r)
2. ROC曲线(receiver operating characteristic)
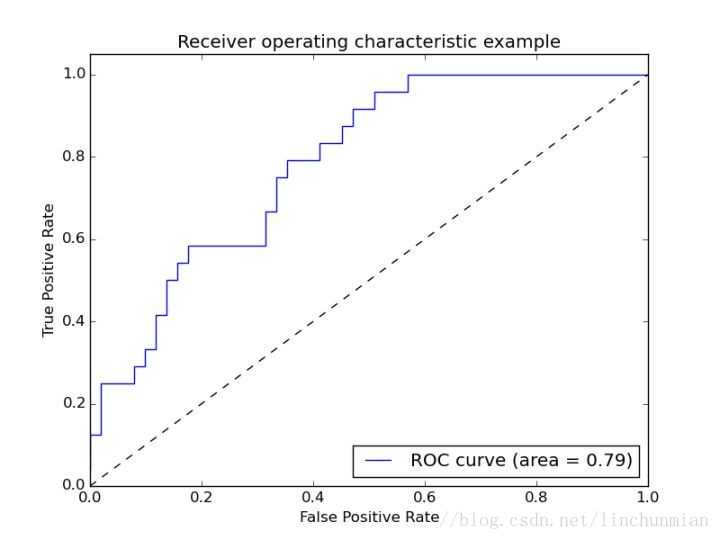
ROC曲线是一种描述灵敏度的评价指标。ROC曲线可以通过计算样本的真阳性率TPR和假阳性率FPR得到,因此ROC曲线也叫做相关操作特征曲线。与PR曲线相反,ROC 曲线的趋势是向左上角凸起的一条曲线,如下图。评价两条ROC曲线的性能优劣,通常计算曲线下方包含的面积AUC,面积越大则代表检测器性能越好。
3. MAP(Mean Average Precision), AP(Average Precision)
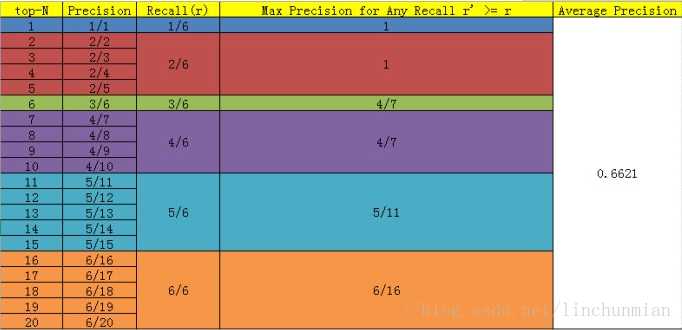
AP通常用于计算平均的检测精度,用于衡量检测器在每个类别上的性能好坏;而MAP则更多用于评价多目标的检测器性能,衡量检测器在所有类别上的性能好坏,即得到每个类别的AP值后再取所有类别的平均值。假设N个样本中有M个positive的正例,那么我们就会得到M个recall值(1/M,2/M,3/M......M/M),对于每个recall值r,我们可以计算出对应r‘>r的最大的precision值,然后对这M个precision 值取平均即得到最后的AP值。计算过程如下表所示:
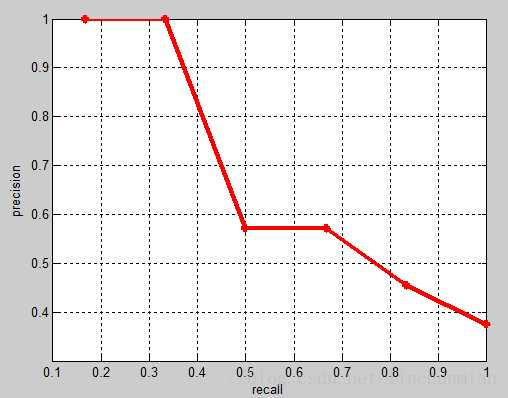
此时的PR曲线为:
以上是关于目标检测评价指标的主要内容,如果未能解决你的问题,请参考以下文章