奇点云数据中台技术汇| DataSimba系列之流式计算
Posted startdt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了奇点云数据中台技术汇| DataSimba系列之流式计算相关的知识,希望对你有一定的参考价值。
你是否有过这样的念头:如果能立刻马上看到我想要的数据,我就能更好地决策?
市场变化越来越快,企业对于数据及时性的需求,也越来越大,另一方面,当下数据容量呈几何倍暴增,数据的价值在其产生之后,也将随着时间的流逝,逐渐降低。因此,我们最好在事件发生之后,迅速对其进行有效处理,实时,快速地处理新产生的数据,帮助企业快速地进行异常管理和有效决策,而不是待数据存储在一起之后,再进行批量处理。
一:sparkStreaming+hbase整合应用,助力企业实时运营监控
对于不作更新的数据,可以通过datax将数据从业务系统数据库同步到hive中,进行离线计算;但对于有大量更新的数据,就不能采用以上的做法了,因为hive不能很好的支持实时更新操作。我们的做法是使用sparkStreaming+HBase做数据存储与去重,然后以封装的HBase工具类为支撑,进行数据的实时监控。
实现原理:
Apache Spark是专为大规模数据处理而设计的分布式内存计算引擎,特点是灵活快速。HBase是一个分布式的、面向列的开源数据库,适用于海量数据的存储与实时写入。HBase工具类是奇点云大数据团队针对Spark与HBase自研的高性能HBase读写工具,它是在HBase官方API基础上依据奇点云特有的需求场景进行了二次开发,内部提供了诸多与Spark紧密结合的API,它的诞生极大地提高了Spark对Hbase的读写速度。经测试,比Spark原生的HBase API性能提高3倍以上,平均开发效率提升10倍以上。正因为HBase工具类的诞生,才促进了Spark与HBase在奇点云的大规模应用。
整体架构:
通过mysql的Canal(canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费)将数据实时投递到kafka中,交由Spark Streaming分批实时消费处理,经过数据清洗、处理与转换,使用HBase工具类将数据逐批写入到HBase中,完成数据的实时同步与更新。

应用场景:
Spark与HBase广泛应用于实时数据写入、统计抽取、历史数据归档、海量数据的实时判断等方面。
·实时数据写入
Spark作为分布式实时计算的佼佼者,擅长海量数据的实时计算。我们通过Spark Streaming将消费到的含有大量更新操作的数据进行清洗、分析与计算,最终以事先设计好的规则实时写入到HBase中,HBase会自动维护重复的数据(rowKey设计原则)。
·海量数据实时判断
在某些场景下,我们需要对历史(一个月以前)的数据进行实时的判断、对比与更新。由于数据量大,且实时性较高,redis或传统的关系型数据库并不能很好的满足要求。对于这种需求,我们对Spark Streaming程序架构进行了梳理,并对HBase相关的API进行了二次开发,最终满足了以上的需求。
某大型商业综合体客户案例
客户背景:
客户为国内某核心商业综合体公司,主营城市核心商业购物中心,对于大型商业购物中心而言,如何实时采集当前进出客流人数、行走动线及热力轨迹、实现数据拉通能力是大型商业购物中心进行业务数字化运营,用户洞察与体验优化的基础。
奇点云的解决方案帮助客户实现了:
1: 实时数据从无到有(原来并不具备实时数据采集能力)
2: t+0实时数据采集(原来仅具有少量离线数据的T+1以上的事后追溯分析能力)
3: 实时客流监控 (今日客流人数,当前在场人数,今日到场次数,平均逗留时长,店铺客流热度,顾客性别与年龄占比,商场黑名单实时预警,客流热力分析,客流动线分析……)
4: 经过实时处理,获得有价值的信息帮助商场快速的做出决策能力(从滞后的经验型追溯分析,到基于现场监控数据的实时运营决策)
二:sparkStreaming+kudu+impala整合应用,助力企业实时多维分析
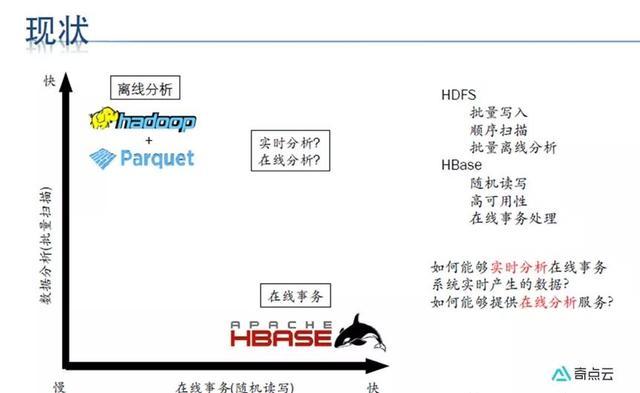
在Kudu出现之前,Hadoop生态环境中的储存主要依赖HDFS和HBase,追求高吞吐批处理的用例中使用HDFS,追求低延时随机读取用例下用HBase,而Kudu正好能兼顾这两者:
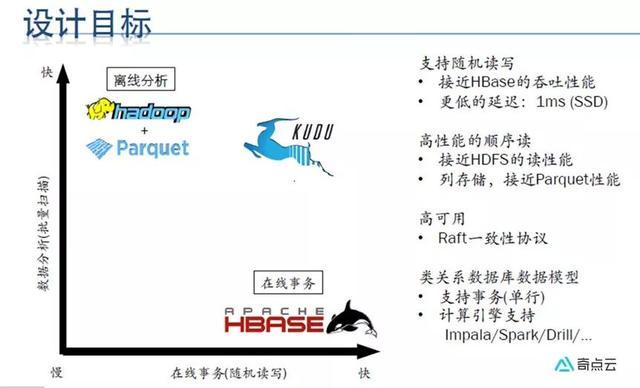
•Kudu的设计使它与众不同:
•快速处理OLAP(Online Analytical Processing)任务;
•集成MapReduce、Spark和其他Hadoop环境组件;
•与Impala高度集成,使得这成为一种高效访问交互HDFS的方法;
•在执行同时连续随机访问时表现优异;
•高可用性,tablet server和master利用Raft Consensus算法保证节点的可用。
•常见的应用场景:
•刚刚到达的数据就马上要被终端用户使用访问到;
•同时支持在大量历史数据中做访问查询和某些特定实体中需要非常快响应的颗粒查询;
•基于历史数据使用预测模型来做实时的决定和刷新;
•要求几乎实时的流输入处理。
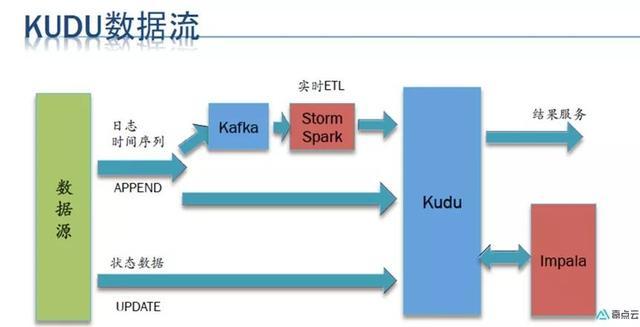
整体架构:
将数据实时投递到kafka中,交由Spark Streaming分批实时消费处理,经过数据清洗、处理与转换,使用kudu工具类将数据逐批写入到kudu中,完成数据的实时同步与更新。
某服饰客户案例
客户背景:
客户为国内某大型服饰品牌,以直营为主,数据情况较好,每天的业务订单量及多张维表数据量不断攀升, 原来的oracle数据库已支持不起庞大业务数据的多条件实时查询,在奇点云介入服务后,企业迫不及待提出了多维度即席查询的需求。
奇点云的解决方案帮助客户实现了:
1: 实时数据从oracle切换到kudu;
2: t+0实时数据采集(从原来的T+1的离线计算到现在的实时计算);
3: 实时订单多维分析 (从原来的多张表关联及30个条件多维度查询,查询不出来到现在的1分钟内出结果);
4: 经过实时分析 (多维度即席查询),获得有价值的信息帮助领导层快速的做出决策力。
流计算秉承一个基本理念,当事件出现时就应该立即进行处理,而不是缓存起来进行批量处理。不同于现有的离线计算,流计算全链路整体上更加强调数据的实时性,包括数据实时采集、数据实时计算、数据实时集成。
以上是关于奇点云数据中台技术汇| DataSimba系列之流式计算的主要内容,如果未能解决你的问题,请参考以下文章