寻觅Azure上的Athena和BigQuery:落寞的ADLA
Posted yunjianshiyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了寻觅Azure上的Athena和BigQuery:落寞的ADLA相关的知识,希望对你有一定的参考价值。
AWS Athena和Google BigQuery都是亚马逊和谷歌各自云上的优秀产品,有着相当高的用户口碑。它们都属于无服务器交互式查询类型的服务,能够直接对位于云存储中的数据进行访问和查询,免去了数据搬运的麻烦。对于在公有云的原生存储上保存有大量数据的许多客户而言,此类服务无疑非常适合进行灵活的查询分析,帮助业务进行数据洞察。
AWS Athena和Google BigQuery当然互相之间也存在一些侧重和差异,例如Athena主要只支持外部表(使用S3作为数据源),而BigQuery同时还支持自有的存储,更接近一个完整的数据仓库。因本文主要关注分析云存储中数据的场景,所以两者差异这里不作展开。
对于习惯了Athena/BigQuery相关功能的Azure新用户,自然也希望在微软云找到即席查询云存储数据这个常见需求的实现方式。这个问题比较少有直接而正面的回答,故本系列文章就此专题进行探讨和实验。
我们先以AWS Athena为例来看看所谓面向云存储的交互式查询是如何工作的。我们准备了一个约含一千行数据的小型csv文件,放置在s3存储中,然后使用Athena建立一个外部表指向此csv文件:

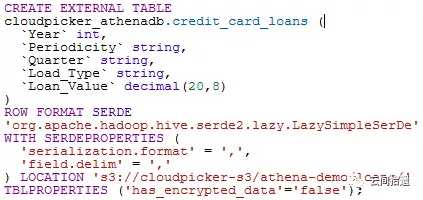
这里使用的测试数据来自一个国外的公开数据集,是中东某地区的信用卡借贷数据,是公开且脱敏的。数据来源相关链接为 https://data.opendatasoft.com/explore/dataset/consumer-and-credit-card-loans%40kapsarc/information/?disjunctive.periodicity&disjunctive.quarter&disjunctive.load_type
然后我们建立一个简单的SQL查询,用以统计多年来每个季度的总借贷额并以降序排列:
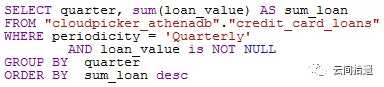
得到的查询结果为:
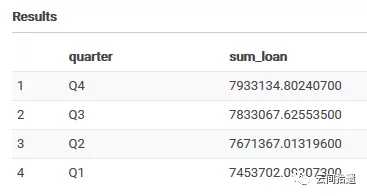
嗯,看上去AWS Athena轻松地完成了我们的分析任务。接下来则轮到Azure出场了。总的来说,Azure可以有多种服务和方式可达到类似AWS Athena的分析效果,不同的方法各自有优势和取舍。
第一种方法,是使用Azure Data Lake Analytics(下简称ADLA)。因为从产品布局上讲,ADLA是与AWS Athena最为对应的Azure服务。该服务最初于2015年公布,于2016年GA,笔者两年前系统梳理微软生态的文章中曾提到了它。该服务可通过与第一代的Azure Data Lake Storage(下简称ADLS)配套使用,实现大规模的数据并行处理与查询。其主要支持的查询语言是U-SQL,一个结合了SQL与C#特点的独有语言。
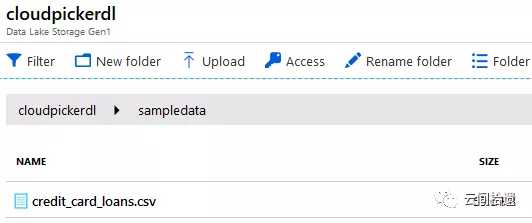
百闻不如一见,我们还是直接动手尝试一下,使用ADLA来实现上面Athena的同样任务。首先,需要把待分析文件存入配合使用的存储服务ADLS(ADLA/ADLS相关服务并未在Azure中国区上线,此处使用的是Global Azure):
其次,需要新建一个ADLA的服务“账户”并指向刚才的ADLS存储:
然后就可以开始进行数据查询了。任务(Job)是ADLA中的核心概念,我们可以新建一个任务,配以一段U-SQL脚本来表达和前面Athena例子中SQL相同的语义:(ADLA没有交互式查询窗口,所以我们把结果落地存储到一个csv文件中)
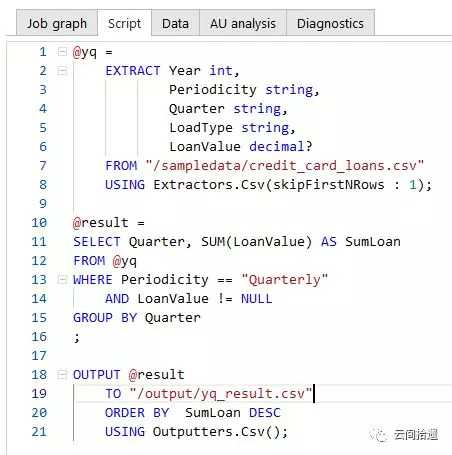
可以看到U-SQL写起来很有意思,的确是结合了C#和SQL的语法与特点。与SQL类似,其核心处理对象为RowSet,即行的集合。我们的脚本中没有使用外部表(U-SQL中外部表仅支持SQLServer系数据库)但通过Extractors.Csv方法达到了同样的目的。事实上更复杂的U-SQL脚本还可以添加上C#类库引用和函数调用等功能,这样结合两种语言的优势来撰写脚本可发挥各自优势,使得ADLA具有十分强大的分析能力。
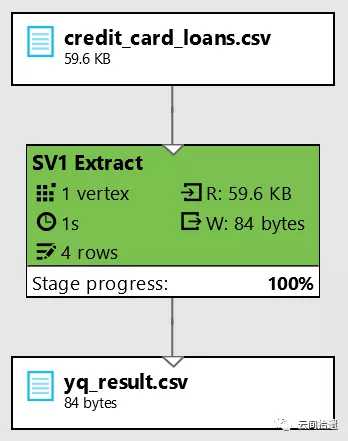
然后我们执行这个任务,ADLS的引擎就会开始执行相应脚本,同时绘制出具体的执行计划和步骤:
最后我们看一下输出文件的内容,同前面的结果是一致的:
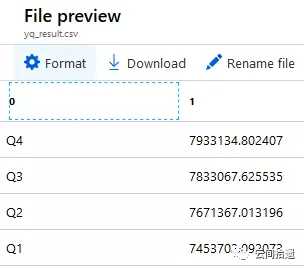
整个流程走下来,可以看到ADLA作为一个完全托管的服务,与Athena的设计理念的确是比较相近的,也能够轻松使用脚本直接针对对象存储中的数据文件进行数据分析。从Azure Portal上来看,整套产品也有着颇高的完成度:
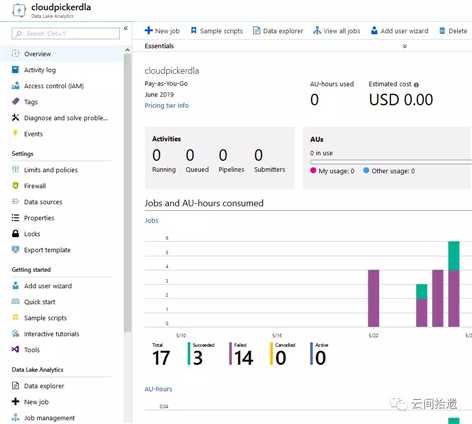
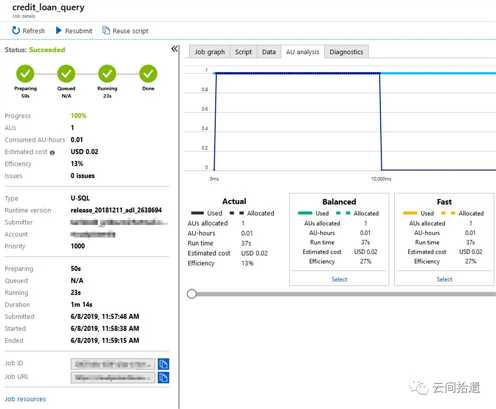
然而,通过实际的操作和体验,我们也发现了ADLA在产品层面也还是存在一些短板,使得其使用范围较为受限:
-
ADLA必须配合ADLS Gen1存储使用,不能适用于最为常见的Azure Blob Storage,这在很多时候需要额外的数据搬运,也不便于应用程序集成;
-
U-SQL语言虽然有独到之处,但毕竟有些“四不像”,配套的开发环境也尚不够成熟,导致了学习和迁移成本很高,调试起来更是非常麻烦(如果不熟悉语法,即便是上面这小段U-SQL也需要折腾好一会儿);
-
该服务主要为超大规模数据处理查询所设计和优化,对于日常小规模的简单数据处理显得过于笨重和缓慢,例如我们上面的脚本居然需要1分钟左右来执行。
也许正由于如上所述产品上的种种不足,它正式发布后叫好不叫座,市场反应比较冷清。逐渐地,ADLA产品似乎进入了维护状态,新特性的更新较为缓慢;而坊间更是传闻相应团队已经重组,与Azure Storage及其他大数据产品团队进行了整合——这一结果委实令人唏嘘。要知道在ADLA/ADLS诞生之初,它们可是背负着将微软内部大数据平台Cosmos(非现在的CosmosDB)进行云产品化的重任。
其实我们愿意相信ADLA背后的技术是十分过硬的,如果它在产品层面有更多的思考,例如更注重与现有Hadoop大数据生态和SQL体系的融合,或是进一步加入和充实.NET生态(如提供C# LINQ Provider),也许会有不同的结果。如今ADLA渐行渐远的背影显得有几分落寞,但将来如果有可能,我们由衷期待它以另一种形式王者归来。
让我们回到本文的主题:面向云存储的交互式数据查询。综上所述,ADLA不失为一个可行的办法,但它也存在一些局限和问题,而且在中国区并未发布。那么在Azure上是否还有其他的选择呢?答案是肯定的。作为第二种方法,我们可以借助源自SQL Server体系的一项神奇技术。欲知详情如何,且听下回分解。
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑和应用场景的深度解读。欢迎扫描下方二维码关注“云间拾遗”公众号,或订阅本博客。

以上是关于寻觅Azure上的Athena和BigQuery:落寞的ADLA的主要内容,如果未能解决你的问题,请参考以下文章
如何将我的 Bigquery 查询转换为 AWS Athena 查询?
将数据从 Google Analytics 迁移到 AWS Athena