Elasticsearch深入7
Posted jiahaojava
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch深入7相关的知识,希望对你有一定的参考价值。
从best-fields换成most-fields策略
best-fields策略,主要是说将某一个field匹配尽可能多的关键词的doc优先返回回来
most-fields策略,主要是说尽可能返回更多field匹配到某个关键词的doc,优先返回回来
与best_fields的区别
(1)best_fields,是对多个field进行搜索,挑选某个field匹配度最高的那个分数,同时在多个query最高分相同的情况下,在一定程度上考虑其他query的分数。简单来说,你对多个field进行搜索,就想搜索到某一个field尽可能包含更多关键字的数据
优点:通过best_fields策略,以及综合考虑其他field,还有minimum_should_match支持,可以尽可能精准地将匹配的结果推送到最前面
缺点:除了那些精准匹配的结果,其他差不多大的结果,排序结果不是太均匀,没有什么区分度了
实际的例子:百度之类的搜索引擎,最匹配的到最前面,但是其他的就没什么区分度了
(2)most_fields,综合多个field一起进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,此时就会是个大杂烩,出现类似best_fields案例最开始的那个结果,结果不一定精准,某一个document的一个field包含更多的关键字,但是因为其他document有更多field匹配到了,所以排在了前面;所以需要建立类似sub_title.std这样的field,尽可能让某一个field精准匹配query string,贡献更高的分数,将更精准匹配的数据排到前面
优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的
缺点:可能那些精准匹配的结果,无法推送到最前面
实际的例子:wiki,明显的most_fields策略,搜索结果比较均匀,但是的确要翻好几页才能找到最匹配的结果
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面
---------------------------------------------------------
使用原生cross-fiels技术解决搜索弊端解决方案
GET /forum/article/_search
"query":
"multi_match":
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": ["author_first_name", "author_last_name"]
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc --> 解决,要求每个term都必须在任何一个field中出现
Peter,Smith
要求Peter必须在author_first_name或author_last_name中出现
要求Smith必须在author_first_name或author_last_name中出现
Peter Smith可能是横跨在多个field中的,所以必须要求每个term都在某个field中出现,组合起来才能组成我们想要的标识,完整的人名
原来most_fiels,可能像Smith Williams也可能会出现,因为most_fields要求只是任何一个field匹配了就可以,匹配的field越多,分数越高
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 --> 解决,既然每个term都要求出现,长尾肯定被去除掉了
java hadoop spark --> 这3个term都必须在任何一个field出现了
比如有的document,只有一个field中包含一个java,那就被干掉了,作为长尾就没了
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 --> 计算IDF的时候,将每个query在每个field中的IDF都取出来,取最小值,就不会出现极端情况下的极大值了
Peter Smith
Peter
Smith
Smith,在author_first_name这个field中,在所有doc的这个Field中,出现的频率很低,导致IDF分数很高;Smith在所有doc的author_last_name field中的频率算出一个IDF分数,因为一般来说last_name中的Smith频率都较高,所以IDF分数是正常的,不会太高;然后对于Smith来说,会取两个IDF分数中,较小的那个分数。就不会出现IDF分过高的情况。
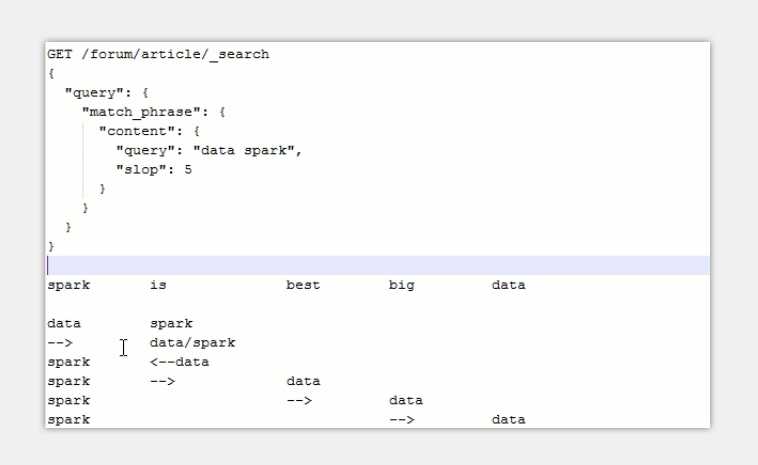
实战中掌握phrase matching搜索技术

GET /forum/article/_search
"query":
"match_phrase":
"title":
"query":"java spark",
"slop":3
假如Filed是 java is very good and spark我们要匹配java spack
java is very good and spark
java spack
Slop最多移动几位进行匹配这是就要设置成4否则无法匹配 Slop移动次数越低分数越高反之就越低
------------------------------------------------------------
混合使用match和近似匹配实现召回率与精准度的平衡
召回率
比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果,就是召回率,recall
精准度
比如你搜索一个java spark,能不能尽可能让包含java spark,或者是java和spark离的很近的doc,排在最前面,precision
直接用match_phrase短语搜索,会导致必须所有term都在doc field中出现,而且距离在slop限定范围内,才能匹配上
match phrase,proximity match,要求doc必须包含所有的term,才能作为结果返回;如果某一个doc可能就是有某个term没有包含,那么就无法作为结果返回
java spark --> hello world java --> 就不能返回了
java spark --> hello world, java spark --> 才可以返回
近似匹配的时候,召回率比较低,精准度太高了
但是有时可能我们希望的是匹配到几个term中的部分,就可以作为结果出来,这样可以提高召回率。同时我们也希望用上match_phrase根据距离提升分数的功能,让几个term距离越近分数就越高,优先返回
就是优先满足召回率,意思,java spark,包含java的也返回,包含spark的也返回,包含java和spark的也返回;同时兼顾精准度,就是包含java和spark,同时java和spark离的越近的doc排在最前面
此时可以用bool组合match query和match_phrase query一起,来实现上述效果
GET /forum/article/_search
"query":
"bool":
"must":
"match":
"title":
"query": "java spark" --> java或spark或java spark,java和spark靠前,但是没法区分java和spark的距离,也许java和spark靠的很近,但是没法排在最前面
,
"should":
"match_phrase": --> 在slop以内,如果java spark能匹配上一个doc,那么就会对doc贡献自己的relevance score,如果java和spark靠的越近,那么就分数越高
"title":
"query": "java spark",
"slop": 50
match和phrase match(proximity match)区别
match --> 只要简单的匹配到了一个term,就可以理解将term对应的doc作为结果返回,扫描倒排索引,扫描到了就ok
phrase match --> 首先扫描到所有term的doc list; 找到包含所有term的doc list; 然后对每个doc都计算每个term的position,是否符合指定的范围; slop,需要进行复杂的运算,来判断能否通过slop移动,匹配一个doc
match query的性能比phrase match和proximity match(有slop)要高很多。因为后两者都要计算position的距离。
match query比phrase match的性能要高10倍,比proximity match的性能要高20倍。
但是别太担心,因为es的性能一般都在毫秒级别,match query一般就在几毫秒,或者几十毫秒,而phrase match和proximity match的性能在几十毫秒到几百毫秒之间,所以也是可以接受的。
优化proximity match的性能,一般就是减少要进行proximity match搜索的document数量。主要思路就是,用match query先过滤出需要的数据,然后再用proximity match来根据term距离提高doc的分数,同时proximity match只针对每个shard的分数排名前n个doc起作用,来重新调整它们的分数,这个过程称之为rescoring,重计分。因为一般用户会分页查询,只会看到前几页的数据,所以不需要对所有结果进行proximity match操作。
用我们刚才的说法,match + proximity match同时实现召回率和精准度
默认情况下,match也许匹配了1000个doc,proximity match全都需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数
但是很多情况下,match出来也许1000个doc,其实用户大部分情况下是分页查询的,所以可能最多只会看前几页,比如一页是10条,最多也许就看5页,就是50条
proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数
rescore:重打分
match:1000个doc,其实这时候每个doc都有一个分数了; proximity match,前50个doc,进行rescore,重打分,即可; 让前50个doc,term举例越近的,排在越前面
GET /forum/article/_search
"query":
"match":
"content": "java spark"
,
"rescore":
"window_size": 50,
"query":
"rescore_query":
"match_phrase":
"content":
"query": "java spark",
"slop": 50
以上是关于Elasticsearch深入7的主要内容,如果未能解决你的问题,请参考以下文章