机器学习周志华——学习器性能度量
Posted sweepingmonk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习周志华——学习器性能度量相关的知识,希望对你有一定的参考价值。
衡量模型泛化能力的评价标准,就是性能度量(performance measure)。
(1)错误率与精度
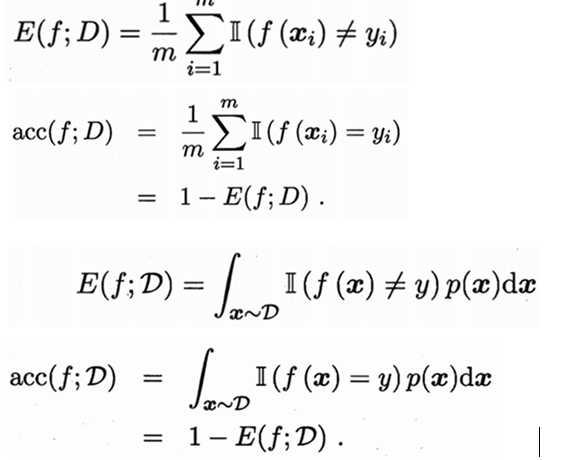
(2)查准率、查全率与F1
基于样例真实类别,可将学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative),TP、FP、TN、FN分别表示其对应的样例数,则有TP+FP+TN+FN=样例总数。
查准率P与查全率R分别定义为:
P= TP/(TP+FP)=>正例结果中真正例数/正例结果总数
R= TP/(TP+FN)=>正例结果中真正例数/结果中所有真正例数
查准率高时,查全率往往偏低,查全率高时,查准率往往偏低(例如选西瓜例子,希望查全率高则应尽可能将所有瓜都选上,但这样查准率必然更低,若希望查准率高则应尽可能挑最有把握的瓜,但这样必然会漏掉一些好瓜,使查全率低)。通常只有在一些简单任务中,才可能使查全率和查准率都很高。
通常按学习器预测结果为正例可能的大小对样例排序,即排在前面的是学习器认变“最可能”是正例的样本,排在最后的则是学习器认为“最不可能”的正例样本。从上到下逐个把样本作为正例进行预测,每次均计算出当前的查全率、查准率,以查准率为纵轴、查全率为横轴作图,得到查准率-查全率曲线P-R曲线,简称P-R图。
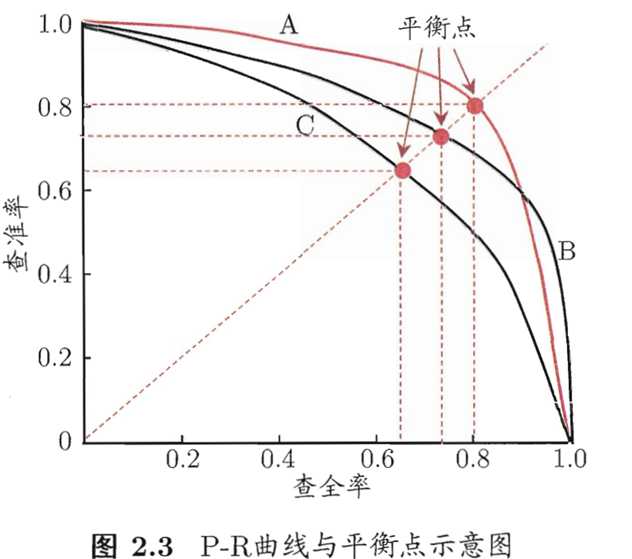
若一个学习器的P-R曲线被另一个学习器曲线完全包住,可断言后者性能优于前者。对于两曲线交叉的情况,人们设计了一些综合考虑查准率、查全率的性能度量。“平衡点”(Break-Event Point,简称BEP)就是这样一个度量,它是查准率=查全率的取值,考虑BEP过于简化了,更常用的是F1度量:
F1=2×P×R/(P+R)=2×TP/(样例总数+TP-TN)
真实应用中,对查准率和查全率的重视程度有所不同,例如商品推荐系统更强调查准率,而逃犯检索中,更希望少漏掉逃犯,查全率更重要。F1度量的一般形式——Fβ,能表达出对查准率/查全率的不同偏好:
Fβ=(1+β2)×P×R/((β2×P)+R)
β>0度量了查全率对查准率的相对重要性,β=1时退化为标准的F1,β>1时查全率有更大影响,β<1时查准率有更大影响。
当希望在n个二分类混淆矩阵上综合才考察查准率和查全率时,一种做法:先计算出各混淆矩阵的查准率和查全率,记为(P1,R1),(P2,R2),…,(Pn,Rn),再计算平均值,得到“宏查准率”(macro-P)、“宏查全率”(macro-R),以及相应的“宏F1”(macro-F1):
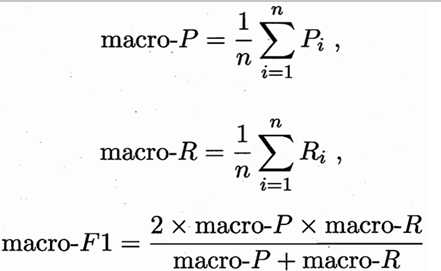
还可将各混淆矩阵的对应元素平均,再得到TP、FP、TN、FN的平均值,再基于这些值计算出“微查准率”(micro-P)、“微查全率”(micro-R)和“微F1”(micro-F1):

(3) ROC和AUC
将针对测试样本的实值或概率预测,将预测值与阈值比较,大于阈值分为正类,否则为反类,根据这个实值或概率预测结果,可将测试样本排序,最可能的正例排在最前面,最不可能的正例排在最后面,分类过程相当于在排序中以某个“截断点(cut point)将样本分为两部分,前一部分作为正例,后一部分则判作反例。根据不同任务来选择截断点,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的”期望泛化性能“的好坏。ROC曲线则是从这个角度出发来研究学习器泛化性能的有力工具。
ROC(受试者工作特征,Receiver Operating Characteristic),与P-R曲线创建方式相似,根据预测结果的排序,逐个把样本作为正例进行预测,每次计算出“真正例率”(True Positive Rate,TPR),和“假正例率”(False Positive Rate,简称FPR),分别作为横轴和纵轴。
TPR=TP/(TP+FN) =>正例结果中真正例/所有结果中真正例
FPR=FP/(TN+FP) =>正例结果中假正例/所有结果中真负例
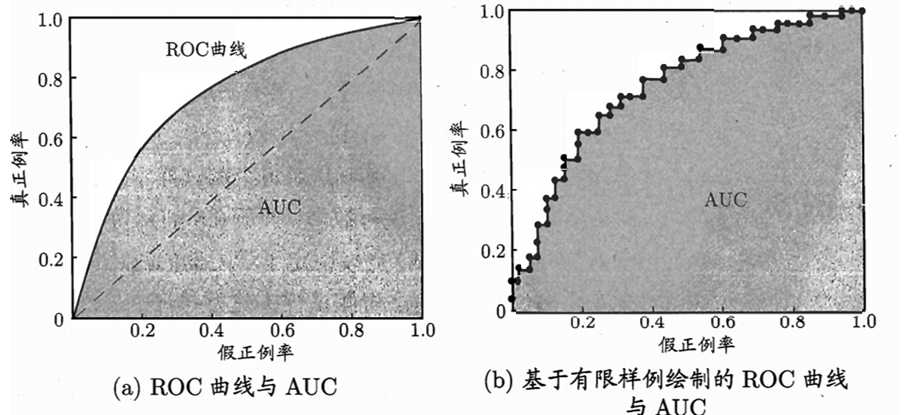
从ROC图中,可见点(0,1)对应于将所有正例排在所有反例之前的“理想模型”,对角线对应于“随机猜测”模型。绘图过程:给定m+个正例和m-个反例(二者数目不一定一样),根据预测结果对样例排序,先把分类阈值设为最大,即所有样例预测为反例,此时真正例率和假正例率均为0,在坐标(0,0)处标记一个点,然后,将分类阈值依次设为每个样例的预测值,即从上至下依次逐个将样例划入正例范围。设前一个标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为(x,y+1/m+);当前若为假正例,则对应标记点的坐标为(x+1/m-,y),然后连接所有相邻点即可。
比较学习器时:若一个学习器的ROC曲线被另一个学习器曲线完全“包住”,则后者性能优于前者;若两学习曲线交叉,判据是ROC曲线下的面积即AUC。AUC可通过ROC曲线下各部分面积求和而得,假定ROC曲线由坐标点(x1,y1),(x2,yx),…,(xm,ym)按序连接形成,且(x1=0,xm=1),则AUC估算为:
![]()
形式上,AUC考虑的是样本预测的排序质量,它与排序误差有紧密联系。给定m+个正例和m-个反例,令D+和D-分别表示正反例集合,排序“损失”定义为:
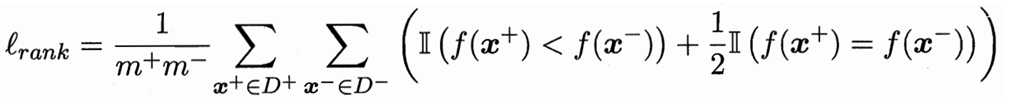
即考虑任一一对正反例,若正例预测值小于反例,则记1个“罚分”,若相等,则记0.5个“罚分”。AUC=1-该值。
(4)代价敏感错误率与代价曲线
为权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)。例如:
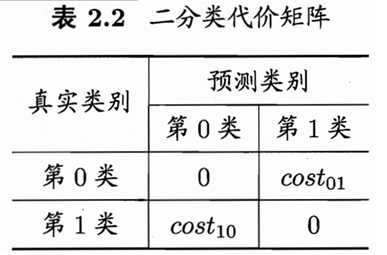
在非均等代价下,希望的不再是简单地最小化错误次数,而是希望最小化“总体代价”(total cost)。表2的二分类问题,其“代价敏感”错误率为:
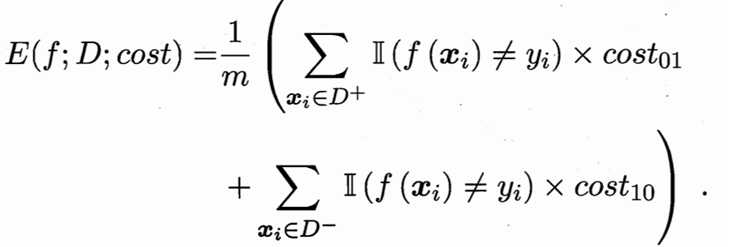
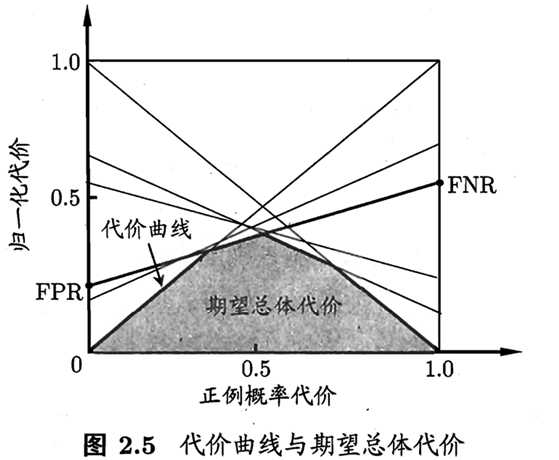
还可给出基于分布定义的代价敏感错误率,及其他一些性能度量如精度的代价敏感版本,若令costij中的i、j取值不限于0、1,则可定义出多分类任务的代价敏感性能度量。“代价曲线”(cost curve),横轴是取值为[0,1]的正例概率代价:
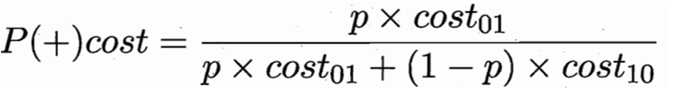
其中p是样例为正例的概率,纵轴是取值为[0,1]的归一化代价:
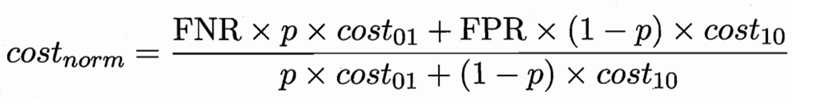
其中FPR是假正例率,FNR=1-TPR是假反例率。
代价曲线的绘制:具体参见P36.
(4)比较检验
学习性能比较时存在的问题:首先,比较的是泛化性能而非测试集性能,其次,与测试集的选择相关,第三,学习算法本身的随机性。
统计假设检验(hypothesis test)为学习器性能比较提供了依据。若在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及此结论把握有多大。
①假设检验
假设是对学习器泛化错误率分布的某种判断或猜想,例如?=?0。现实任务中只能获知测试错误率?(^),泛化错误率与测试错误率未必相同,但二者接近的可能性较大,相关很大的可能性较小,因此,可根据测试错误率估推出泛化错误率的分布。
对于泛化错误率为?的学习器,将其中m’个样本误分类、其样本正确分类的概率是? m’(1- ?)m-m’,由此可算出恰好将?(^)×m个样本误分类的概率如下所示(也即表示泛化错误率为?的学习器被测得错误率为?(^)的概率):
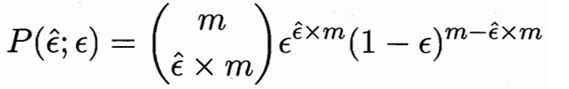
上式对?对偏导,可知其概率在?=?(^)时最大,|?-?(^)|增大时P减小。这个概率符合二项分布。
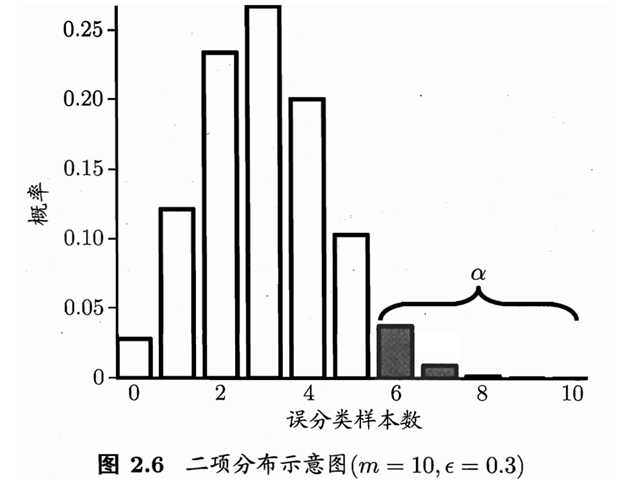
可使用“二项检验”(binomial test)对?≤0.3(即泛化错误率是否不大于0.3)这样的假设进行检验,更一般地,考虑假设?≤?0, 则在1-α的概率(反映了结论的置信度)内所能观察到的最大错误率如下式计算:
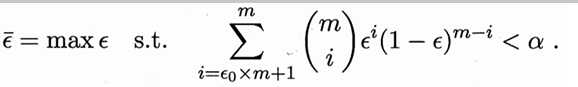
(个人理解:预测错误概率<α的情况下,泛化错误率?的最大值?)
若测试错误率?(^)小于临界值,根据二项检验可得结论:在α显著度下,假设?≤?0不能被拒绝,也即是能以1-α的置信度认为,学习器的泛化错误率不大于?0。
以上是关于机器学习周志华——学习器性能度量的主要内容,如果未能解决你的问题,请参考以下文章