《密码安全新技术》课程总结报告
Posted ychancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《密码安全新技术》课程总结报告相关的知识,希望对你有一定的参考价值。
《密码安全新技术》课程总结报告
课程学习内容总结
第一次课 网络(Web)安全与内容安全
本次讲座的学习内容主要为两方面:
1.Web应用安全
- SQL注入
- Havij
- Pangolin 1. 反射型XSS 2. 存储型XSS
- Apache解析漏洞
- nginx解析漏洞
2.隐私安全
- 用户轨迹 :移动方向、运动轨迹、运动频率、
- 用户画像(性别、年龄、直液、搜索记录、住址)、手机号码、MAC地址
- AI 机器学习 启发式
- 内网漫游 隐蔽信道检测 注入攻击 网页木马 凭证盗窃
本次讲座是开学第一次课,现在再看老师上课的PPT,许多上课举得例子还历历在目。网络安全涉及网络通信的方方面面。
第二次课 量子密码
本次讲座为我们从整体上科普了量子密码的相关内容,主要有7个部分:
辟谣
- 超光速通信不存在
- 激光通信比墨子号快得多
- 墨子号用来发送密钥-发送纠缠光子
1.密码体制对比
- 对称密码体制:密钥分配问题、密钥管理问题、无签名
- 公钥密码体制:速度低
2.量子密钥特点:
- 检测窃听
- 理论上无条件安全
3.传统密码的安全性挑战:量子计算
- Shor算法 大数分解算法
- Grover算法:快速搜索法
4.量子:具有特殊性质的微观粒子或光子。
量子态:
- 向量描述
- 可叠加性:并行性、不可复制、测不准
5.量子比特的测量:力学量、测量基。(仪器不同观测的结果不同)
BB84量子密钥分配协议(单光子)
“截获-重发”攻击
6.量子mm基本模型:
信息传输:两种信道
-量子信道:光纤、自由空间
-经典信道:(测量基)- 窃听检测
- 纠错
- 保密增强:解决噪声问题、错误率阀值、
提高实际系统抗攻击能力:诱骗态、设备无关态
其实本次讲座使我们在宏观上对量子密码有了初步的认识,很多理论也有了感性的理解,为日后对量子密码领域的研究打了基础。
第三次课 基于深度学习的密码分析与设计
本次讲座的内容主要有四个方面:
- 密码分析与机器学习(machine learning)
专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
机器学习的步骤:
数据源-分析-特征选择-向量化-拆分数据集-训练-评估-文件整理-接口封装-上线
密码分析与机器学习相似,机器学习在密码分析的应用:
破解DES遗传算法、用于侧信道分析的支撑向量机算法等
- 深度学习
- 深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
- 深度学习模型:
- 有监督学习:卷积神经网络(Convolutional neural networks,简称CNNs)
- 无监督学习:深度置信网(Deep Belief Nets,简称DBNs,其中卷积神经网络(CNN:ConvolutionalNeural Networks)、循环神经网络(RNN:RecurrentNeuralNetworks)、 生成对抗网络(GAN:GenerativeAdversarialNetworks)等在大数 据分析、图像识别、机器翻译、视频监控中取得了较大进步。
- 视觉大数据时代模型学习的突破:端到端深度学习,不再区分特征提取和模式分类
- 特征学习:仿人脑的层级表达。应用包括自动上妆、imageQA、图像风格图像验证码、美感评价
深度学习与密码分析
一方面生成人可能设置的密码、一方面去识别设定密码的是人还是机器。
(1)基于卷积神经网络的侧信道攻击
(2)基于循环神经网络的明文破译
(3)基于生成对抗网络的口令破解
(4)基于深度神经网络的密码基元识别
利用深度学习破解数学难题为基础的密码。深度学习与密码设计
利用深度学习设计新的高强度密码-生成对抗网络GAN:Generative Adversarial??Network
其他应用:
GAN–二次元人物頭像鍊成
GAN–真实图像生成
第四次课 信息隐藏
第四次的讲座主要有四个部分:
- 密码 VS 信息隐藏
- 水印 VS 隐写
- 隐写的应用
- 隐写分析?
密码 VS 信息隐藏
首先要对密码加密技术和信息隐藏技术做一个区分。密码技术不能隐藏通信行为本身,但可以保护通信的消息。而消息隐藏可以隐藏通信行为。使用密码技术加密消息再通过信息隐藏技术进行传递。
其次信息隐藏可以同时解决内容保护与内容隐藏的问题。
信息隐藏定义:比加密更进一步,将特定的消息隐藏在载体中。
信息隐藏研究方向:
- 水印:数字产权管理与安全标识技术。
- 可视密码:是产生 n 张不具有任何意义的胶片, 任取其中 t 张胶片叠合在一起即可还原出隐藏在其中 的秘密信息
- 隐写:隐蔽通信或者隐蔽存储方法, 将秘密消息难以感知地隐藏在内容可公开的载体中, 保护保密通信或者保密存储这些行为事实。
常用的载体:
- 文本
轻微改变字符间距
不可见字符
格式信息 - 音频
MP3
AMR - 图像
空域图像
JPEG - 视频
运动向量
变换系数
帧内\\间预测模式、量化参数、熵编码
水印 VS 隐写
| ?? ? ? ? ? ?水印? ?? ? ? ? ? ? ? ? ? | ? ? ? ? ? ? ?隐写? ? ? ? ? |
|---|---|
| 公开 | 无声 |
| 鲁棒水印 | 藏头诗 |
隐写的应用
- LSB嵌入
- 矩阵嵌入(改的少)
- 自适应隐写(改的好)
特工安娜查普曼、凯蒂猫图片传信息
隐写分析?
- 高位特征High-Dimensional
- 隐写选择信道Selection-Channel-Aware
第五次课 区块链
本次讲座主要分成三个部分来讲述:
一、区块链
比特币(Bitcoin)的特点:
- 数字货币。
- 不依托于任何国家或组织而利用计算机技术独立发行。
- 通过P2P分布式技术实现,无中心点。
- 所有人均可自由的参与。ISIS,在线毒品交易市场等,反政府、无政府组织、勒索软件
- 总量有限,不可再生。货币天然是金银
- 本身机制开源,可以被山寨。传销
如何交易:
每一位所有者(A)利用他的私钥对前一次交易T1和下一位所有者(B)的公钥(俗称:地址)签署一个随机散列的数字签名,A将此数据签名制作为交易单T2并将其(交易单T2)广播全网,电子货币就发送给了下一位所有者。
交易要点:
- 交易发起者的私钥:私钥为个人所知,他人无从知晓。
- 前一次交易:前一次交易数据说明了该次交易的货币的来源(这部分货币是怎么到当前发起人这里来的)。
- 下一位所有者的公钥:即交易接收方的地址,此数据说明了当前交易的目标是谁。
- 数字签名:发起方将前一次交易数据和接收方公钥连接起来并对其求Hash值x,再利用自己的私钥对x加密,便得到了这份数字签名。
交易单:
记录一笔交易的具体信息,比如付款人(交易发起方的公钥)、收款人(交易接收方的公钥)、付款金额(上一笔交易信息)、付款人签名(加密后的Hash值)等。
比特币网络中,数据以文件的形式被永久记录,称之为区块(Block)
比特币体系的设计要求:
Block应由那些最诚实最勤劳的节点产生,因而引入工作量证明(Proof Of Work,POW)机制。比特币体系倾向于认为:一个节点在提供信息之前付出了巨大的工作量,那么他可能是诚实的概率比较高(他提供的Block中数据最有可能没有问题,当然无论如何其他节点也是会对其进行检查的)。
挖矿过程:
反复去尝试寻找一个随机数(又称“幸运数”),使得将最后一个Block的hash值、当前世界中尚未被加入到任何Block的交易单、随机数三部分组织起来送入SHA256算法计算出散列值X(256位),如果X满足一定条件(比如前20位均为0),那么该节点初步获得创建Block的权利。
Block链分支:
?????? 某一节点若收到多个针对同一前续Block的后续临时Block,则该节点会在本地Block链上建立分支,网络会根据下列原则选举出Best Chain:
- 不同高度的分支,总是接受最高(即最长)的那条分支
- 相同高度的,接受难度最大的
- 高度相同且难度一致的,接受时间最早的
- 若所有均相同,则按照从网络接受的顺序
- 等待Block Chain高度增一,则重新选择Best Chain
二、区块链技术
区块链技术的4个基本性质:
- 点对点对等网络
- 数据可验证
- 共识机制
- 奖励合作的制度设计
三、区块链与未来
区块链技术发展的三个阶段(领域):
货币→合约→治理
货币:
货币的发行机制
货币的分配机制
货币的币值调节机制合约:
股权
债权
博彩
证券与金融合约
防伪······治理:
身份认证
健康管理
公证、见证
人工智能
司法仲裁
去中心化自治组织
投票
第六次课 漏洞挖掘及攻防技术
本次学习的总结如下:
- 引言
安全漏洞:缺陷、不足、未授权的情况;
安全漏洞是网络攻击和防御的关键点;
安全事件的根本原因在于安全漏洞;
漏洞挖掘:找漏洞
漏洞利用:出发漏洞,攻、证
漏洞防御:修复、提前防御 - 常见漏洞挖掘技术
- 手工测试
- 凭经验检验脆弱点
- 无规律可循 不可大规模
- 补丁对比
- 文本(男定位,输出难理解)
- 汇编指令(易理解,输出范围大,难定位)
- 优点:发现速度快
- 缺点:已知漏洞
- 常见工具:PatchDiff2、bindiff
- 程序分析
- 包括静态和动态
- 不运行程序,扫描代码
- 优点:覆盖率100%,自动化程度高
- 缺点:漏报和误报(RICE,程序分析问题不可判定)
- 二进制审核
- 定义:源代码不可得,逆向获取二进制代码
- 缺点:逆向导致信息丢失,理解困难,甚至逻辑错误
- 工具:IDA Pro、Ollydbg、UltraEdit、Hex Workshop、WinHex
- 模糊测试
- 定义:通过向被测目标输入大量的机型数据并检测其异常来发现漏洞
- 关键:测试用例构造、自动化
- 优点:无需源码、误报低、自动化程度高
- 缺点:覆盖率低
- 工具:Peach、Sulley、Autodafe、SPIKE
- 漏洞挖掘示例
- bash漏洞:远程在系统上执行任意代码 危害大、范围广。
- 路由器协议漏洞挖掘
- 系统架构
- 实验结果
(1)向161端口发送大量畸形SNMP get/set 请求报文,畸形的数据包中包含长格式化字符串“%s...”的SNMPv1 GetRequest报文Cisco路由器和华为路由器的进程Agent出现CPU使用率异常。
(2)当远程发送SNMP空数据包时,Cisco路由器和华为路由器的CPU使用率出现异常,但远小于100%,发生“轻度拒绝服务”
(3)当远程发送一个畸形ASN.1/BER编码(超长字符串)的SNMP数据包时,wireshark捕获并解析数据包导致栈溢出、空指针引用并崩溃。
(4)当向SNMP协议端口远程发送一个使用“/x”等字符构造的畸形UDP数据包,科来网络分析系统7.2.1及以前版本均会因边界检查不严而导致崩溃
- NFC漏洞挖掘
- 定义:近距离的双向高频无线通信技术;
- 特点:距离短一次只能和一台设备连接、硬件安全模块加密、保密性安全性好
- 目标选择:NFC手机系统和应用
- 结果:
(1)NFC拒绝服务,影响android4.4以下支持NFC的所有版本。
(2)打开手电筒,华为、小米等定制系统设计缺陷,在启动com.android.systemui的包时导致MIUI系统在触碰该标签时自动打开系统手电筒。
(3)打开蓝牙:使用系统版本为Android4.1.3以下等多个版本的NFC手机触碰蓝牙配对标签,导致蓝牙被自动打开。
(4)打开WiFi:逻辑漏洞,MIUI系统5.3.0等多个版本,受i触碰包含WiFi连接报文的标签后,系统WiFi会被自动打开。
(5)应用程序拒绝服务:报文解析错误。
(6)屏幕亮度漏洞:设计缺陷,NFC手机触碰标签可以将屏幕亮度设置在0-255的任意值,突破亮度限制0-100
第一小组 Finding Unknown Malice in 10 Seconds: Mass Vetting for New Threats at the Google-Play Scale
1.概要:
今天应用市场的审查机制是缓慢的,不太可能发现新的威胁。新的technique,称为MassVet,用于大规模审查应用程序,而不知道恶意软件的外观和行为。与现有的检测机制不同,这些机制经常使用重量级程序。分析技术,我们的方法只是将提交的应用程序与市场上的所有应用程序进行比较,在一个有效的相似比较算法的基础上建立了这个“DiffCom”分析,该算法映射了应用程序的ui结构或方法的控制流图t的显著特征。该算法将应用程序的UI结构或方法的控制流图的显着特征映射到一个快速比较的值,在一个流处理引擎上实现了MassVet,并评估了来自全球33个应用市场的近120万个应用程序,即Google Play的规模。我们的斯图DY显示,该技术可以在10秒内以较低的误检率审查应用程序。
2.检测的思路:

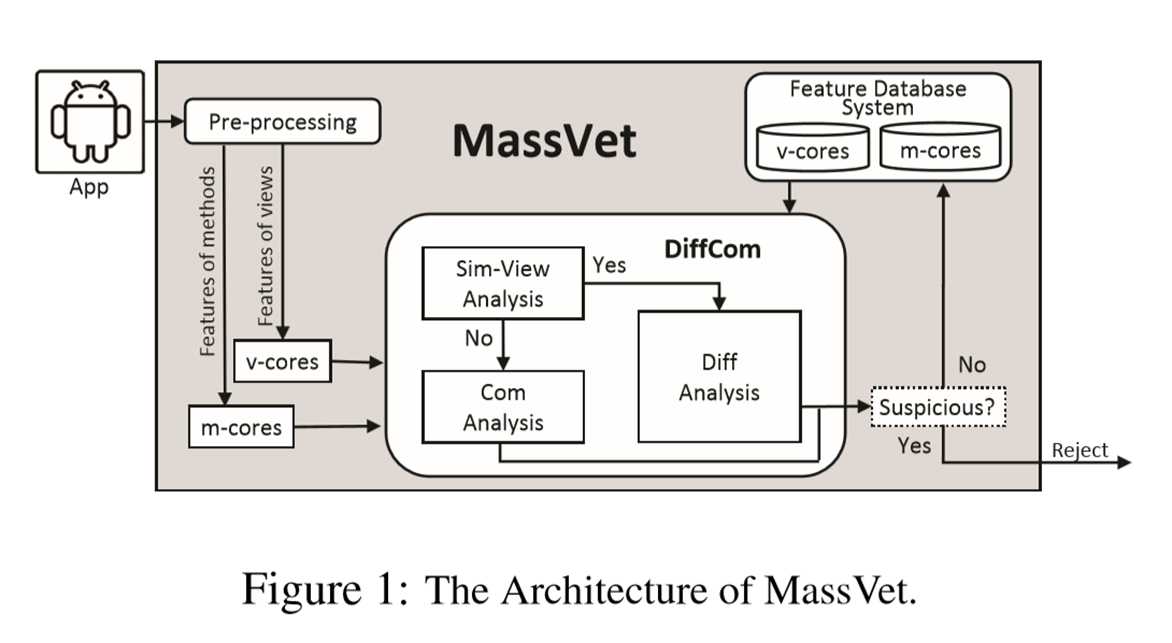
3.架构图:
4.示例:
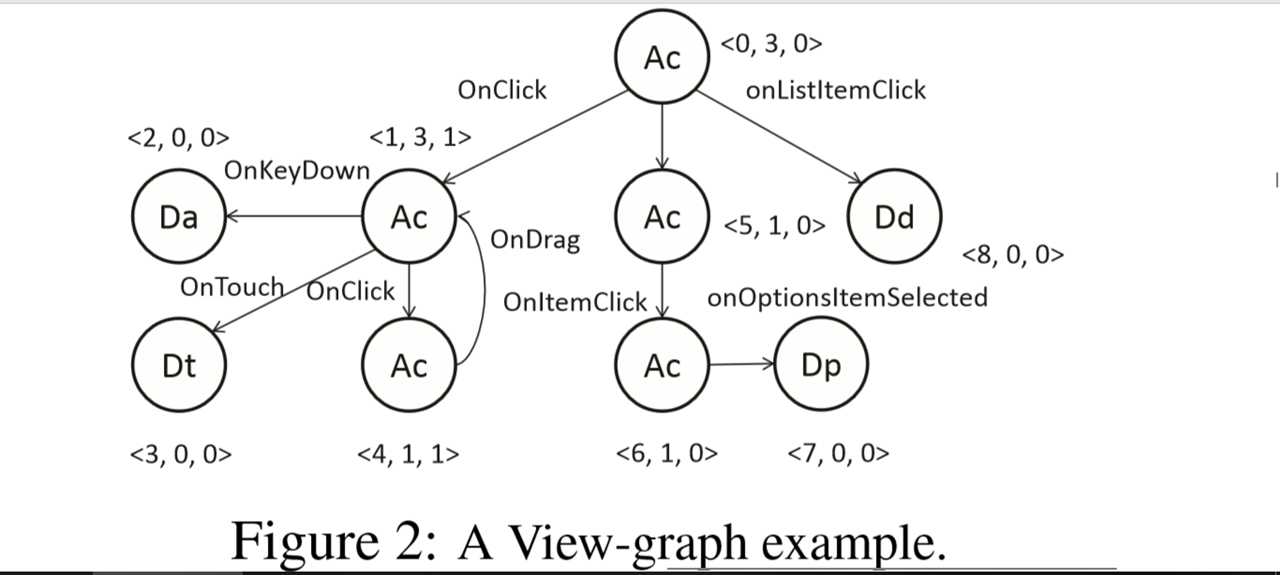
Ac: Activity; Da: AlertDialog; Dt: TimePickerDialog
Dp: ProgressDialog; Dd: DatePickerDialog
5.性能测试结果
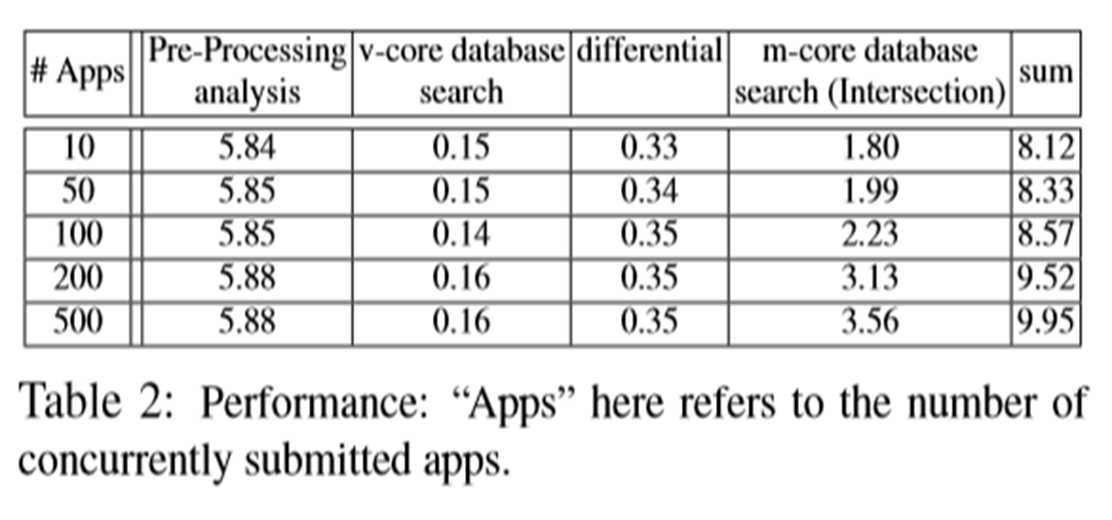
“Apps”是指并发提交的应用程序的数量。
6.结论:
- 发现的恶意软件分布在世界各地。
- 应用程序出现得越近,问题就越大。发现的大多数恶意软件都是在过去14个月上传的。
- 一些恶意软件作者已经生产了大量的恶意应用程序,并成功地在不同的市场上传播,有一些签名与许多身份相关联(例如,元数据中的创建者字段),对手可能有创建了许多帐户来分发他的应用程序。
第二小组 Spectre Attacks: Exploiting Speculative Execution
1.概要
幽灵攻击包括诱使受害者投机取巧地进行手术。第二小组描述了结合在一起的实际攻击。方法来自侧通道攻击、故障攻击和面向返回的编程,可以从受害者的进程中读取任意内存。
2.投机执行
具有预测执行能力的新型处理器,可以估计即将执行的指令,采用预先计算的方法来加快整个处理过程。
预测执行的设计理念是:加速大概率事件。
预测执行是高速处理器使用的一种技术,通过考虑可能的未来执行路径并提前地执行其中的指令来提高性能。
2.条件分支错误预测

该段代码的通常执行过程如下:
进入if判断语句后,首先从高速缓存查询有无array1_size的值,如果没有则从低速存储器查询,按照我们的设计,高速缓存一直被擦除所以没有array1_size的值,总要去低速缓存查询。
查询到后,该判断为真,于是先后从高速缓存查询
array1[x]和array2[array1[x]*256]的值,一般情况下是不会有的,于是从低速缓存加载到高速缓存。
在执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(加速大概率事件),于是直接执行下面的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中
array1[x]和array2[array1[x]*256]的值,当CPU发现预测错误时我们已经得到了需要的信息。
3.攻击流程
- 首先需要知道受害方信息的内存地址,获得方法可以考虑监视寄存器/内存的变化情况。这也引出了本攻击的环境要求,即要求攻击方和受害方共享物理内存。
- 其次确定幽灵攻击的一些参数,比如尝试攻击次数,猜解置信阈值等。(均为经验值,视实际CPU和运行环境有所变化)
编写代码进行攻击
第三小组 All Your GPS Are Belong To Us:Towards Stealthy Manipulation of Road Navigation Systems
1.概要
本小组探讨了对道路导航系统进行隐身操纵攻击的可行性。
目标是触发假转向导航,引导受害者到达错误的目的地而不被察觉。
2.攻击思路
略微改变GPS位置,以便假冒的导航路线与实际道路的形状相匹配并触发实际可能的指示。
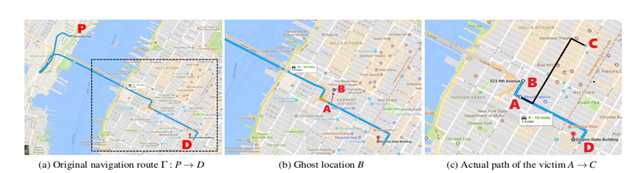
3.实验
①.首先进入已经搭建好软件环境系统Ubuntu-14.04
②.创建一个文件夹,打开命令窗口ctrl+alt+t
③.进入创建的文件夹,下载编译GPS仿真器代码(gps-sdr-sim)代码:git clone
https://github.com/osqzss/gps-sdr-sim.gi
④.进入代码文件夹中:cd gps-sdr-sim
⑤.进入文件夹后,用gcc编译代码:gcc gpssim.c -lm -O3 -o gps-sdr-sim
⑥.在网站http://www.gpsspg.com/maps.htm上查询一个你感兴趣的地方的GPS经纬度信息,然后按照这个经纬度信息通过GPS仿真器生成GPS仿真数据:./gps-sdr-sim -e brdc3540.14n -l
31.603202,120.466576,100 -b 8
等待执行上述命令,执行结束后,文件夹中多出的gpssim.bin文件,就是我们模拟生成的GPS数据。
⑦.用HackRF来发射在上一步中模拟生成的伪造数据:
hackrf_transfer -t gpssim.bin -f 1575420000 -s 2600000 -a 1 -x
0
?? 打开手机中的高德地图或者百度地图等定位APP,你会看到你现在所在的真实位置,等待一段时间后,地图会定位到给定的经纬度附近。
(命令参数解析:”gpssim.bin”为GPS数据文件,用-f来指定频率为1575420000 ,即民用GPS
L1波段频率,用-s来指定采样速率2.6Msps,开启天线增益,指定TX VGA(IF)为0,发送指令末尾0表示天线增益(发射功率,最大可到40,增大发射功率可以增强伪造信号的强度,扩大其影响范围,在发送指令的后面加入 -R可使hackrf one一直工作。)
第四小组 With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning
1.概要
高质量模型的训练需要非常大的标记数据集,小型公司没有条件训练这么大的数据集或者无法得到这么大的数据集,往往采用迁移学习。第三小组介绍了迁移学习攻击:一个小型公司借用大公司预训练好的模型来完成自己的任务。我们称大公司的模型为“教师模型“,小公司迁移教师模型并加入自己的小数据集进行训练,得到属于自己的高质量模型”学生模型”。
2.对抗性攻击
给一个输入图像加入不易察觉的扰动,使模型将输入图像误分类成其他类别。
3.白盒攻击:攻击者能够获知分类器的内部体系结构及所有权重。它允许攻击者对模型进行无限制的查询,直至找到一个成功地对抗性样本。这种攻击常常在最小的扰动下获得接近100%的成功,因为攻击者可以访问深度神经网络的内部结构,所以他们可以找到误分类所需的最小扰动量。然而白盒攻击一般被认为是不切实际的,因为很少会有系统公开其模型的内部结构。
4.黑盒攻击:攻击者不知道受害者的内部结构,攻击者要么尝试反向工程DNN的决策边界,建一个复制品用于生成对抗样本,要么反复查询生成中间对抗样本并不断迭代改进。黑盒攻击容易被防御。
5.攻击思路
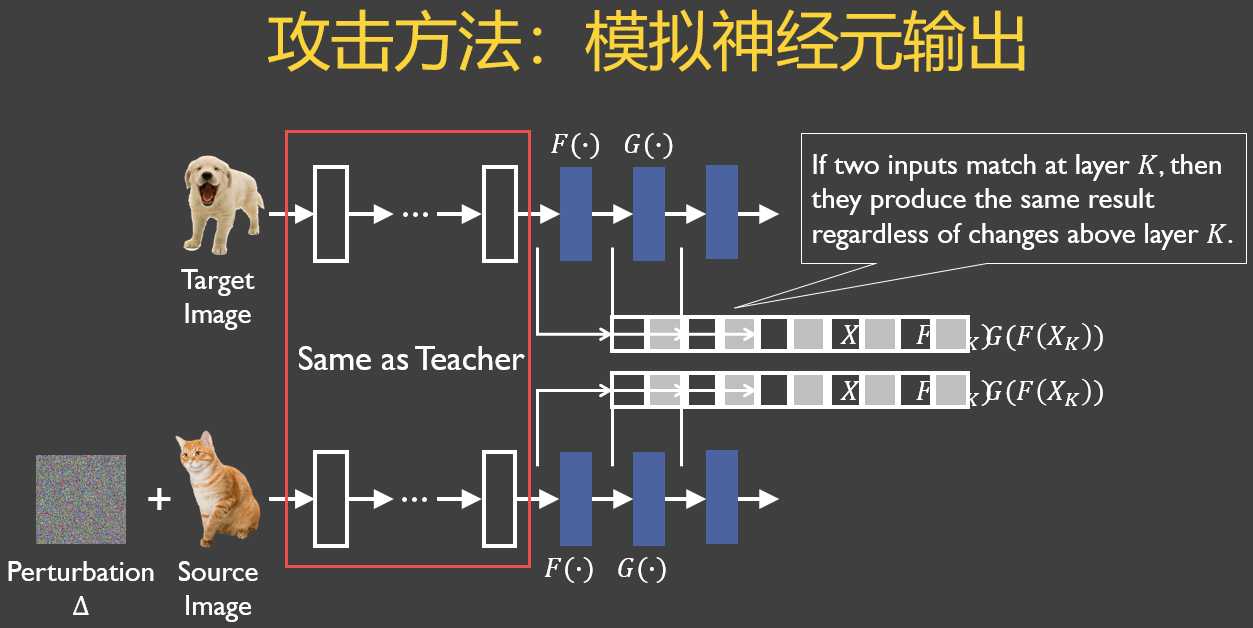
- 将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量
- 对source图加入扰动,使得加过扰动的source图(即对抗样本)
- 在输入教师模型后,在第K层产生非常相似的输出向量。
- 由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
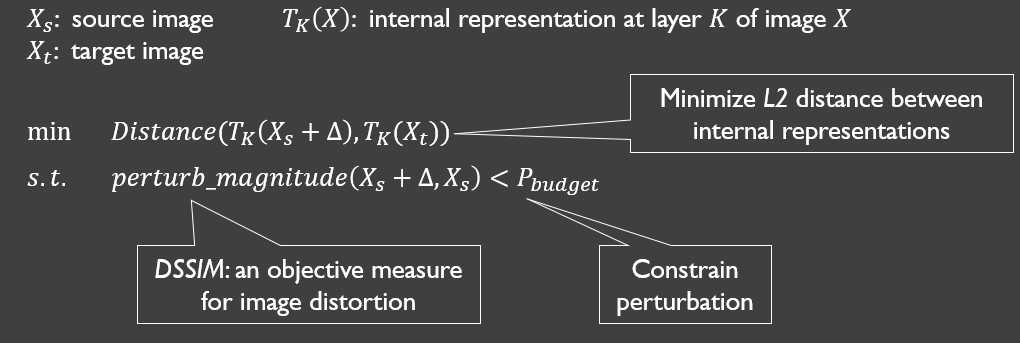
6.计算扰动
通过求解一个有约束的最优化问题来计算扰动(?) - 目标:模拟隐藏层(第K层)的输出向量
- 约束:扰动不易被人眼察觉
7.攻击方式:目标攻击/非目标攻击

第五小组 Safeinit: Comprehensive and Practical Mitigation of Uninitialized Read Vulnerabilities
1.概要
本文通过在clang/LLVM编译器架构上,通过修改代码,实现了safeinit原型,在编译C/C++源代码时,传递一个标记即可使用safeinit实现优化编译,缓解未定义变量。使用了强化分配器的safeinit可以进一步优化代码的同时,保证所有需要初始化的变量进行初始化,删除多余初始化代码进行优化,这样既保证缓解了未定义变量漏洞的威胁,同时与其他现有方法相比,提升了性能。
2.现存威胁
在几乎所有应用程序中,内存不断被重新分配,因此被重用。
在栈中,函数激活帧(activation frames)包含来自先前函数调用的数据; 在堆上,分配包含来自先前释放的分配的数据。 当在使用之前不覆盖这些数据时,会出现未初始化数据的问题,从而将旧数据的生命周期延长到新分配点之外。内存也可能只是部分初始化; C中的结构和联合类型通常是故意不完全初始化的,并且出于简单性或性能原因,通常为数组分配比存储其内容所需的(最初)更大的大小。当不清楚变量是否在使用之前被初始化时,唯一实用且安全的方法是在所有情况下初始化它。
1)许多程序调用memset来清除敏感数据;如果数据不再有效并且因此在该点之后不再使用,编译器可以通过调用memset来优化这些调用。但是如果之后的数据还有效,禁止编译器优化的替代函数(例如memset_s和explicit_bzero)并不是普遍可用的。
2)例子:地址空间布局随机化(ASLR)之类的防御一般取决于指针的保密性,并且由于这通常仅通过随机化一个基地址来完成,因此攻击者仅需要获取单个指针以完全抵消保护。指针可以是代码,栈或堆指针,并且这些指针通常存储在栈和堆上。
Microsoft描述了由于2008年Microsoft Excel中未初始化的堆栈变量导致的任意写入漏洞
Microsoft的XML解析器中的一个错误使用存储在局部变量中的指针进行虚函数调用,该局部变量未在所有执行路径上初始化
4)函数堆栈帧包含局部变量的副本、其他局部变量和编译器生成的临时变量的溢出副本,以及函数参数,帧指针和返回地址。
现代编译器使用复杂的算法进行寄存器和堆栈帧分配[42],临时和具有非重叠生命周期的变量都可以分配给堆栈帧(或寄存器)的相同部分。 这减少了内存使用并改善了缓存局部性,但意味着即使在函数调用之前/之后清除寄存器和堆栈帧也不足以避免所有潜在的未初始化变量。
5)在我们讨论的环境中,未定义行为是指在代码读取未初始化的堆栈变量或者是未初始化的堆分配。
为了实现最大数量的优化,现代编译器转换(例如LLVM [34]使用的那些)利用了大型的这种未定义的行为 规模。 即在转换过程先将未定义的值(以及因此也未初始化的值)解释为使得优化更方便的任何值,在生成最终机器码的时候在改为未定义值,但这样有可能导致程序逻辑不一致。而且 这些情况通常只有在已经应用了其他编译器转换后才会变得明显,因为动态分析工具无法检测到这些情况,因为它们依赖于在此过程之后生成的机器代码。
3.safeinit LLVM架构
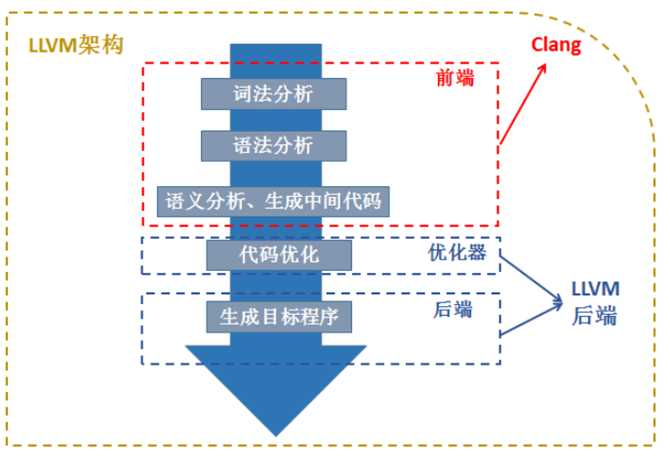
理解LLVM时,我们可以认为它包括了一个狭义的LLVM和一个广义的LLVM。广义的LLVM其实就是指整个LLVM编译器架构,包括了前端、后端、优化器、众多的库函数以及很多的模块;而狭义的LLVM其实就是聚焦于编译器后端功能(代码生成、代码优化等)的一系列模块和库。
?Clang是一个C++编写、基于LLVM的C/C++/Objective-C/Objective-C++编译器。Clang是一个高度模块化开发的轻量级编译器,它的编译速度快、占用内存小、非常方便进行二次开发。
上图是LLVM和Clang的关系:Clang其实大致上可以对应到编译器的前端,主要处理一些和具体机器无关的针对语言的分析操作;编译器的优化器部分和后端部分其实就是我们之前谈到的LLVM后端(狭义的LLVM);而整体的Compiler架构就是LLVM架构。
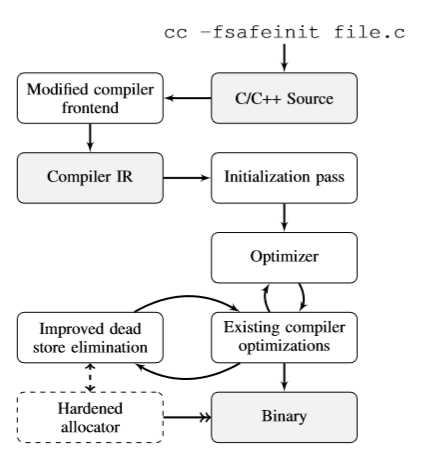
编译器在获得C/C++文件后,编译器前端将源文件转换为中间语言(IR),通过初始化、代码优化(这里的优化包括了编译器自身的优化以及无效存储消除这种附加组件),之后通过强化分配器最后获得二进制文件。Safeinit在整个过程中所添加的就是 初始化全部变量、优化以及强化分配器,来避免或缓解未初始化值。
最后,SafeInit优化器提供了非侵入式转换和优化,它们与现有的编译器优化(必要时自行修改)以及最终组件(现有“死存储消除”优化的扩展)一起运行。 这些构建在我们的初始化传递和分配器之上,执行更广泛的删除不必要的初始化代码,证明我们的解决方案的运行时开销可以最小化。
SafeInit通过强制初始化堆分配(在分配之后)和所有栈变量(无论何时进入作用域)来减轻未初始化的值问题。
LLVM中的局部变量是使用alloca指令定义的; 我们的pass通过在每条指令之后添加对LLVM
memset内部的调用来执行初始化。
我们在安全分配器中执行覆盖所有堆分配函数以确保始终使用强化的分配器函数(对初始化堆分配是在分配之后进行强制初始化)。编译器知道我们的强化分配器正在使用中; 任何已分配内存的代码都不再使用未定义行为,并且编译器无法修改或删除。

目的:可在提高效率和非侵入性的同时提高SafeInit的性能。优化器的主要目标是更改现有编译器中可用的其他标准优化,以消除任何不必要的初始化。
存储下沉:存储到本地的变量应尽可能接近它的用途。
检测初始化:检测初始化数组(或部分数组)的典型代码
“无效存储消除”(DSE)优化,它可以删除总是被另一个存储覆盖而不被读取的存储。
堆清除:所有堆分配都保证初始化为零,如果有存储到新分配堆内存中的零值都会被删除
非恒定长度存储清除:为了删除动态堆栈分配和堆分配的不必要初始化
交叉块DSE:可以跨多个基本块执行无效存储消除
只写缓冲区:通过指定该缓冲区只用来存储而不是删除,就可以将该缓冲区删除。
4.性能分析
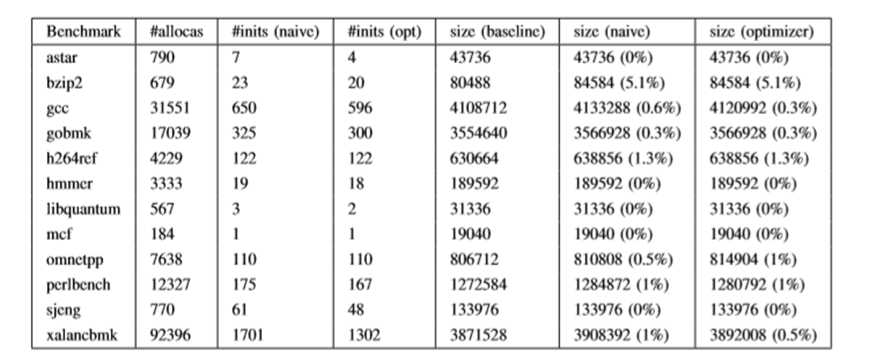
优化器在没有强化分配器的情况下启用时,只能看到0.3%的最小性能提升,可以看到通过safeinit以及强化分配器的情况下,获得了性能优势。
第六小组 Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning
1.概要
第六小组郭同学讲解了对线性回归模型第一次中毒攻击的系统的研究及对策。在中毒攻击中,攻击者故意影响训练数据以操纵预测模型的结果。作者提出了一个专门为线性回归设计的理论基础优化框架,并展示了它在一系列数据集和模型上的有效性
2.系统和对抗模型系统架构
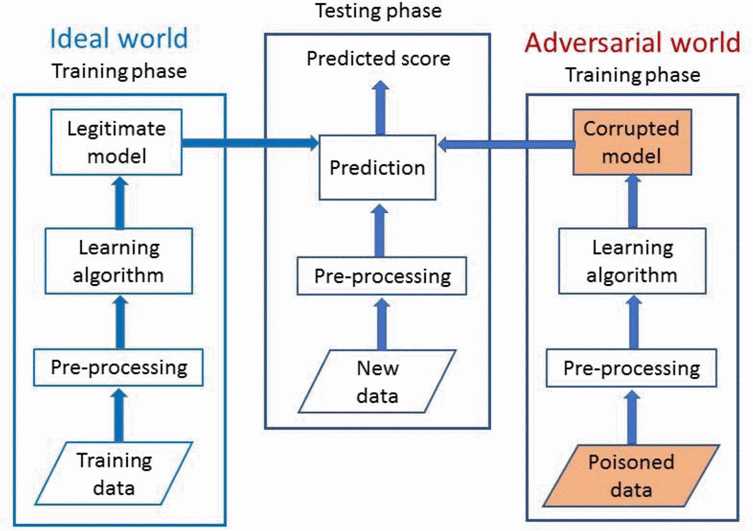
学习过程包括执行数据清理和标准化的数据预处理阶段,之后可以表示训练数据。
模型在预处理后应用于新数据,并使用在训练中学习的回归模型生成数值预测值。
在中毒攻击中,攻击者在训练回归模型之前将中毒点注入训练集
3.攻击方法论

- 梯度计算-具有线搜索的标准梯度算法
- 目标函数-总是使用MSE作为损失函数
- 初始化策略-选择初始集Dp中毒点作为输入
- 基线攻击-定义基线攻击为来自Xiao等人的攻击
- 响应变量优化-响应变量采用连续值而不是分类值
- 理论见解-关于Eqs的双层优化的一些理论见解
4.防御算法
- 噪音回归
- 对抗性回归
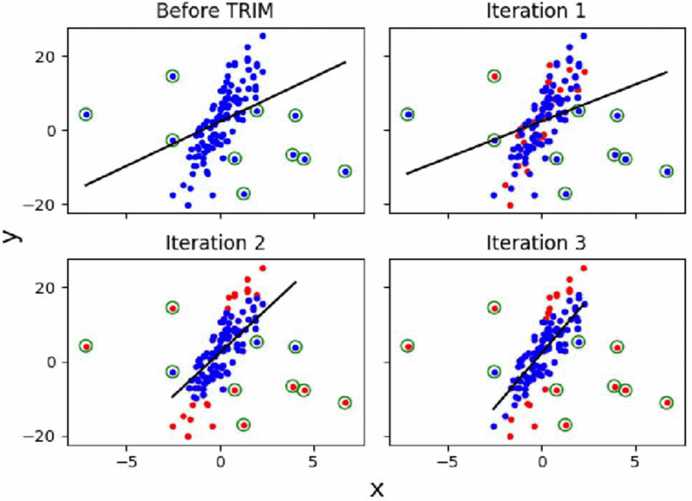
- TRIM算法
第七小组 ConvolutionalNeuralNetworksforSentenceClassi?cation
1.概要
第七小组杨同学报告了在预先训练的单词向量之上训练的一系列用于句子级分类任务的卷积神经网络(Cnn)的实验。参数整定和静态向量在多个基准上都取得了很好的效果。通过微调学习任务-特定的向量提供了性能上的进一步提高。
2.模型
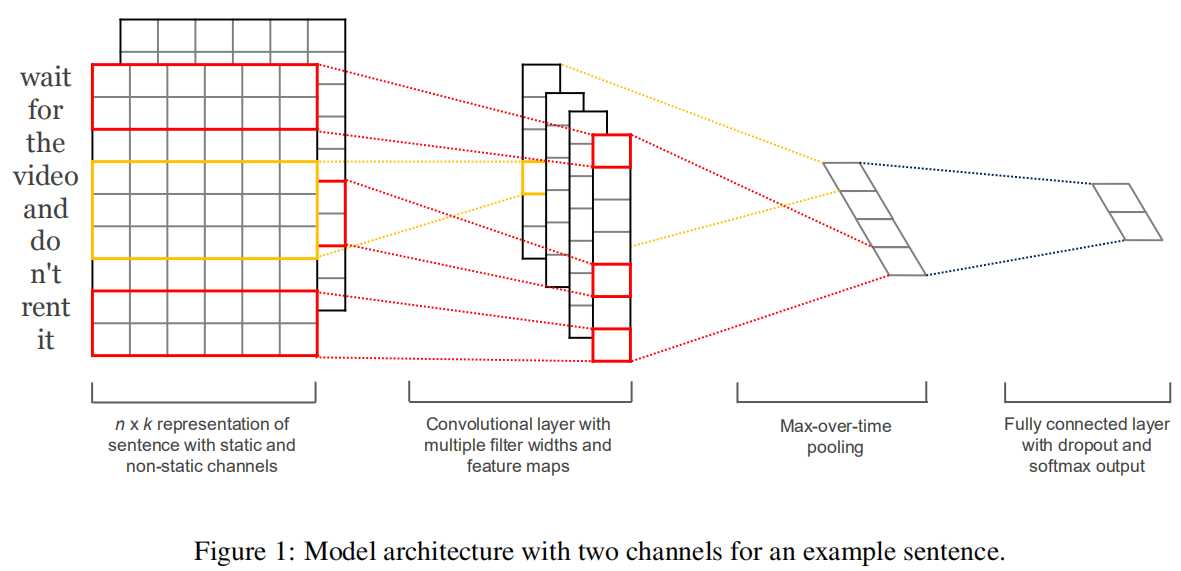
模型结构是Colobert等人的CNN体系结构的轻型变体。(2011年)。
3数据集和实验设置
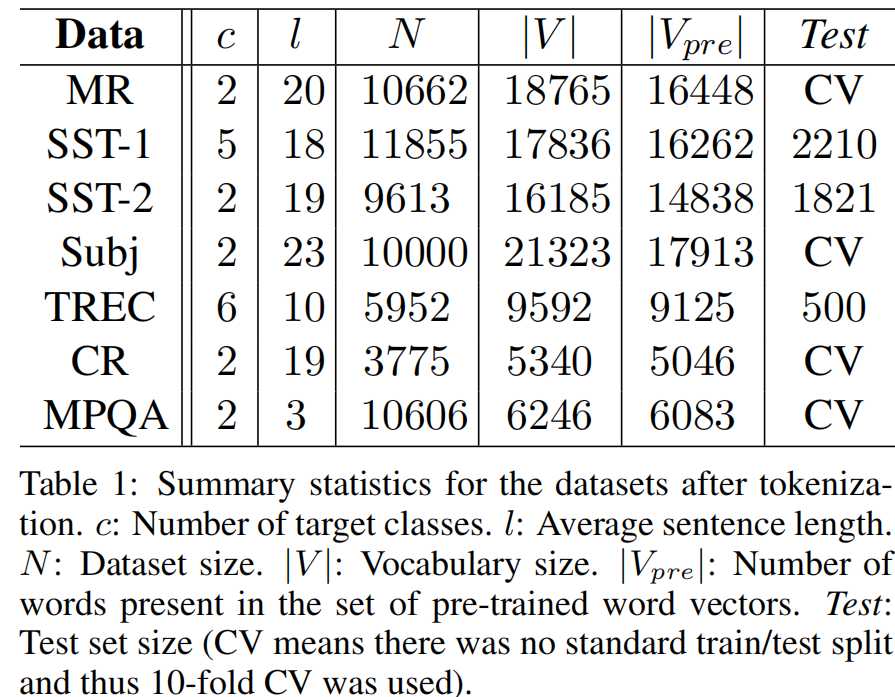
在各种基准上测试模型。这些数据集的统计摘要见表1。
4.结论
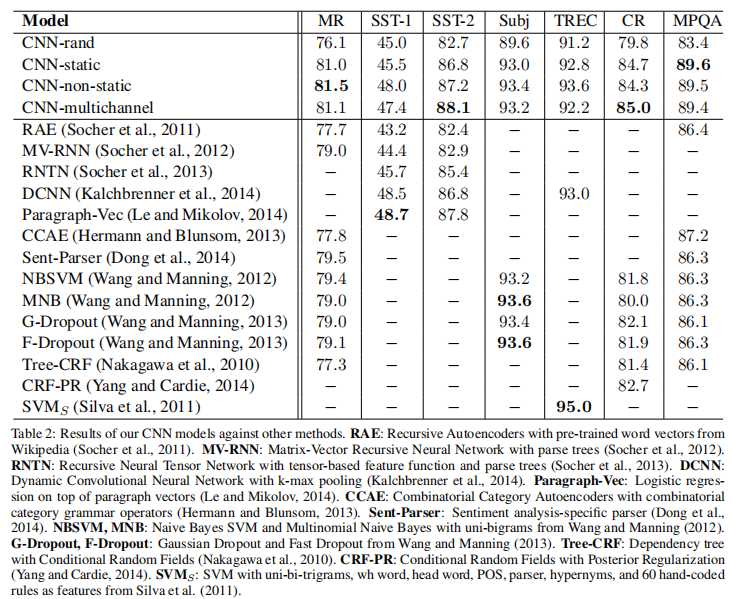
与其他方法比较的结果和讨论结果列于表2。
我们的基线模型包含所有随机初始化的单词(CNN-RAND),期望通过使用经过预先训练的向量来提高性能效果很好。
感想体会
密码安全新技术课程的内容十分丰富,有非常多可以可下自己拓展的内容,老师也做出了这方面的要求。在一学期的学习后,除去知识点,最大的收获就是发现了众多有趣的领域,练习了学习论文的方法,这些都使我受益匪浅。
对课程的建议和意见
暂无
以上是关于《密码安全新技术》课程总结报告的主要内容,如果未能解决你的问题,请参考以下文章