打分排序系统漫谈3 - 贝叶斯更新/平均
Posted gogosandy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打分排序系统漫谈3 - 贝叶斯更新/平均相关的知识,希望对你有一定的参考价值。
打分排序系统漫谈3 - 贝叶斯更新/平均
标签(空格分隔): 博客园 统计 打分系统 待完成
上一节我们聊了聊用Wilson区间估计来处理小样本估计,但从原理上来说这种方法更像是一种Trick,它没有从本质上解决样本量小的时候估计不置信的问题,而是给估计加上一个和样本量相关的置信下界,然后用这个下界替代估计进行打分。
想要从本质上解决小样本估计不置信的问题,一个更符合思维逻辑的方法是我们先基于经验给出一个预期估计,然后不断用收集到的样本来对我们的预期进行更新,这样在样本量小的时候,样本不会对我们的预期有较大影响,估计值会近似于我们预先设定的经验值,从而避免像小样本估计不置信的问题。
假设\\(\\theta\\)是我们要给出的估计,x是我们收集的数据, \\(\\pi(\\theta)\\)是我们基于经验给出的预期。贝叶斯表达式如下:
\\[ \\beginalign p(\\theta|x) \\propto p(x|\\theta) * \\pi(\\theta) \\endalign \\]
原理看似简单,但落实到实际应用就会出现几个问题:
- 如何把实际问题抽象成概率分布 \\(p(x|\\theta)\\)
- 如何设置预期概率分布 \\(\\pi(\\theta)\\)
- 如何用新样本对分布进行更新得到参数估计
让我们继续用之前点赞的例子,一个一个解答上面的问题
二元贝叶斯更新
样本分布抽象 \\(p(x|\\theta)\\)
我们上一章已经讨论如何对用户的点赞拍砖行为进行抽象。简单来说每一个用户是否点赞\\(\\sim Bernoulli(p)\\),用户间相互独立,所以N个用户对某一篇文章点赞量\\(\\sim Binomial(n,p) = \\left(\\! \\beginarrayc n \\\\ k \\endarray \\! \\right)p^k(1-p)^(n-k)\\)
抽象出了样本的概率分布,,我们要如何用这些样本对我们想要估计的参数p(点赞率)进行更新呢?预期分布抽象- 共轭分布\\(\\pi(\\theta)\\)
这就涉及到另一个概念- 共轭先验分布。名字非常高大上难以记住(刚刚wiki过才找到对应的中文...)。简单解释如果你的先验分布和后验分布一致,它们就分别是共轭先验和共轭后验。这个性质之所以如此吸引人就在于,可以持续用新样本更新先验分布。因为如果分布不变 \\(p(\\theta|x_i) \\propto p(x_i|\\theta) * \\pi(\\theta)\\)就可以一直连着乘下去\\(x_i , i \\in (1,2,..N)\\)
有这种性质的分布有几种,而适用于二项分布的就是Beta分布。把先验分布设为beta分布,不断用二项分布的样本数据去更新先验分布,后验分布还是beta分布。记忆卡片~Beta分布
Beta函数: \\(Beta(a,b) = \\frac(a-1)!(b-1)!(a+b-1)!\\)
Beta分布概率密度 \\(f(x;a,b) = x^(a-1)(1-x)^(b-1)/Beta(a,b)\\)
Beta分布统计值:\\(\\mu = \\fracaa+b\\)- 分布更新-贝叶斯更新
看到Beta分布的概率密度很容易联想到二项分布,因为它们十分相似。和二项分布对比x就是我们要估计的参数p,Beta分布的两个参数a,b分别对应正负样本数量k,n-k。换言之Beta分布是二项分布参数的分布。
下一步我们就需要用到Beta分布作为共轭分布的性质(先验后验分布不变)来对参数进行更新:
\\[ \\beginalign \\pi(p|\\alpha+k, \\beta+n-k) &= P(X=k|p, n) * \\pi(p|\\alpha, \\beta)\\E(\\hatp) &= \\frac\\alpha + k\\alpha + \\beta + n \\leftarrow \\frac\\alpha\\alpha + \\beta \\where & \\quad \\pi(\\alpha, \\beta) \\sim Beta(\\alpha, \\beta) \\& \\quad x \\sim Binomial(n,p) \\endalign \\]
如果我们预期点赞和拍砖的概率是50%/50%,既\\(\\alpha=\\beta\\)。当我们对预期不是非常肯定的时候(对用户行为更相信),我们的\\(\\alpha,\\beta\\)可以给的相对比较小,这样样本会很快修正先验概率,反之\\(\\alpha,\\beta\\)给更大值。这里\\(\\alpha,\\beta\\)可以理解为我们根据预期设定的虚拟样本,下面是一个直观的例子:
\\(\\alpha =2, \\beta = 2,\\hatp=0.5\\), 当收集到1个点赞样本,更新后的参数变为,$\\alpha = 3, \\beta=2, \\hatp \\to 0.67 $
\\(\\alpha =10, \\beta = 10, \\hatp=0.5\\), 当收集到1个点赞样本更新后的参数变为,$\\alpha = 11, \\beta=10, \\hatp \\to 0.52 $
一个更直观的\\(\\alpha, \\beta\\)取值变化对参数p分布的影响如下图:
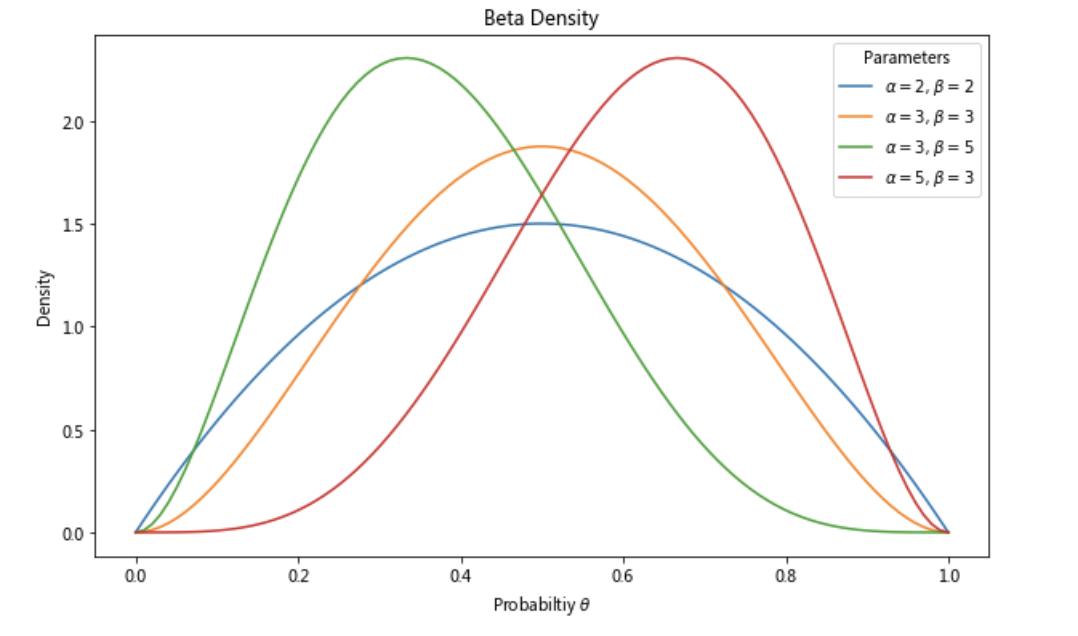
- \\(\\alpha, \\beta\\)越大方差越小,p的分布越集中
- \\(\\alpha\\)增加,p估计均值越大
- \\(\\beta\\)增加,p估计均值越小
抛开数学的部分,用贝叶斯更新的方法来估计用户评分可以非常简单的用下面的表达式来表示,其中\\(\\alpha\\)是预设的点赞量, \\(\\beta\\)是预设的拍砖量, n是收集到的全部样本量,其中k是收集到的样本中点赞的数量。
\\[ \\hatp = \\frac\\alpha + k\\alpha + \\beta + n \\]
如何设定\\(\\alpha \\beta\\)决定了最终打分从哪里开始更新,以及最终打分对新样本的敏感程度。
多元贝叶斯更新
上述我们对用户的行为做了一个最简单的抽象,只包括点赞和拍砖两种行为。现实情况往往更复杂,比如用户打分(五星评分),这种情况我们应该如何使用贝叶斯来得到更加稳健的分数估计呢?
让我们对照着上面二项分布的思路来梳理一下
样本分布抽象 \\(p(x|\\theta)\\)
假设用户的评分从1分-5分,用户最终打了3分,则可以抽象成一个有5种可能的多项分布,用户的选择用向量表示就是 \\((0,0,1,0,0)\\) 。多项分布的表达式如下
\\[ \\beginalign P(x|\\theta) &= \\beginpmatrix N \\\\ x_1,...,x_5 \\\\ \\endpmatrix \\prod_i=1^5 \\theta_i^x_i \\score &= \\sum_i=1^5 p_i * i \\endalign \\]
其中N是用户量,\\(x_i\\)是选择打i分的用户数,满足$\\sum_i=1^5 x_i = N $, \\(\\theta_i\\)是打i分的概率,满足 \\(\\sum_i=1^5 \\theta_i = 1\\)
我们通过收集到的用户打分来给出打1分-5分的概率,最终用多项分布的期望作为最终打分。共轭先验
和二项分布一样,现在我们需要找到多项分布的共轭先验分布 - Dirchlet分布,也就是beta分布推广到多项。Dirchlet的分布概率密度如下:
\\[ Dir(\\theta|\\alpha) = \\frac\\Gamma(\\alpha_0)\\Gamma(\\alpha_1)...\\Gamma(\\alpha_K) \\prod_k=1^K \\theta^\\alpha_k-1 \\]
其中\\(\\alpha_0 = \\sum_i^K \\alpha_k\\),当K=2的时候Dirchlet就是beta分布。和Beta分布相同, 其中\\(\\alpha_i\\)可以理解为对打分为i的预期先验。贝叶斯更新
确定了先验分布和后验分布,我们用和beta相同的方法用收集到的样本对参数进行更新。
\\[ \\beginalign Dir(\\theta|D) &\\propto P(D|\\theta) * Dir(\\theta|\\alpha)\\Dir(\\theta|D) &= \\frac\\Gamma(\\alpha_0 + N)\\Gamma(\\alpha_1 + m_1)...\\Gamma(\\alpha_K + m_k) \\prod_k=1^K \\theta^\\alpha_k + m_k-1\\\\endalign \\]
上述的条件概率可以被简单理解为,当我们收集到N个样本其中\\(m_i\\)个样本打了i分,则打i分的概率会从预置的先验概率\\(\\frac\\alpha_i\\sum_i^k\\alpha_i\\)被更新为 \\(\\frac\\alpha_i + m_i\\sum_i^k\\alpha_i + N \\)
有了后验概率,我们就可以得到最终打分如下
\\[ \\frac\\sum_i=1^K i * (\\alpha_i + m_i)\\sum_i^k\\alpha_i + N \\]贝叶斯平均
针对小样本打分一种很常用的方法叫做贝叶斯平均,许多电影网站的打分方法都来源它。让我们先写一下表达式:
\\[ x = \\fracC*m + \\sum_i=1^Kx_iC+N \\]
其中C是预置样本量(给小样本加一些先验样本), N是收集的样本量,m是先验的总体平均打分,\\(x_i\\)是每个用户的打分。贝叶斯平均可以简单理解为用整体的先验平均打分来对样本估计进行平滑。
但其实让我们对上述基于Dirchlet分布给出的打分式进行一下变形 $\\sum_i=1^K i * \\alpha_i = C *m $, \\(\\sum_i=1^K i * m_i = \\sum_i=1^K x_i\\), 会发现两种计算方式是完全一致的!!
针对打分我们分别讨论了时间衰减,以及两种解决小样本估计不置信的方法。 但这只是打分系统很小的一部分,还有一块很有趣的是如何基于偏好调整最终的打分。以后有机会再聊吧
To be continue
Reference
- http://www.evanmiller.org/bayesian-average-ratings.html
- http://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_bayesian_average.html
- https://www.quantstart.com/articles/Bayesian-Inference-of-a-Binomial-Proportion-The-Analytical-Approach
- https://en.wikipedia.org/wiki/Beta_function
以上是关于打分排序系统漫谈3 - 贝叶斯更新/平均的主要内容,如果未能解决你的问题,请参考以下文章