kafka为什么吞吐量高
Posted zzq-include
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka为什么吞吐量高相关的知识,希望对你有一定的参考价值。
1:kafka可以通过多个broker形成集群,来存储大量数据;而且便于横向扩展。
2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向leader角色的partition提交数据,而消费者pull数据的时候自己通过zk存储offset信息,严格讲broker基本只关心存储数据;
3:kafka的ack策略也是提高吞吐量的手段:
1)生产者的acks如果设置0则只向leader发送数据,并不关心leader数据是否存储成功;
2)如果设置为1在向leader发送数据后需要等待leader存储成功后才会认为一次操作成功;
3)如果设置为-1在向leader发送数据后不但需要等待leader存储成功,还要等待各个follow角色的partition,从leader拉取数据后存储完成才算一次完整的ack,当然这种情况会降低kafka的吞吐量;
而且follow从leader拉去后存储完成才能将本地的(segmentLog)LEO标记移动到最后,如果follow未同步完成kafka为了保证数据一致性“HW高水位线”也只能保证到一个较低水平;
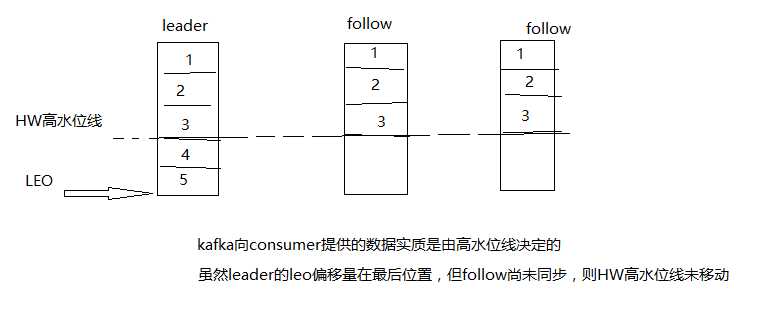
ps:而且kafka底层是通过NIO顺序写数据,效率也是非常高的
以上是关于kafka为什么吞吐量高的主要内容,如果未能解决你的问题,请参考以下文章