Solr学习记录:Getting started
Posted randolf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr学习记录:Getting started相关的知识,希望对你有一定的参考价值。
Solr学习记录:Getting started
本教程使用环境:java8或者更高版本、Solr8.1、centos7
1.Solr Tutorial
1.1简介
本篇将用三个部分具体练习以引领对Solr的快速体验。每个练习将基于前一个练习。
- 第一个练习:启动solr,创建一个Collection,索引一些基础文档,执行一些搜索。
- 第二个练习:使用不同数据集,并尝试用其访问页面。
- 第三个练习:开始使用自己的数据,并为实现制定计划。
1.2 解压Solr
方便统一操作,我们将solr安装在/opt 路径下
~$ mv solr-7.7.0.zip /opt/
~$ unzip -q solr-7.7.0.zip
#或者是:tar -zxvf solr-7.7.0.zip
~$ cd solr-7.7.0/1.3 练习一:索引Techproducts样例数据
目标:
- 以双节点集群启动Solr(同一台机器上),并且在启动期间创建一个collection。
- 为这些样例数据建立索引,并做一些基础的搜索工作。
以SolrCloud模式启动Solr(基于zookeeper的分布式搜索)
启动Solr
bin/solr start -e cloud。注:这将开启一个交互式会话,在机器上开启两个Solr服务。
solr-7.7.0:$ ./bin/solr start -e cloud Welcome to the SolrCloud example! This interactive session will help you launch a SolrCloud cluster on your local workstation. To begin,how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes)[2]:你想在本地集群创建多少个节点,默认2个。本例中只需两个节点,直接Enter默认。为建立外部zookeeper集群,因此solr将连接内置的zookeeper。
分别为两个节点选择端口号
#第一个节点 Ok, let's start up 2 Solr nodes for your example SolrCloud cluster. Please enter the port for node1 [8983]:#第二个节点 Please enter the port for node2 [7574]:除非你了解这两个节点已经被占用,我们建议直接Enter选择默认节点即可。
启动完成后将创建一个collection,并要求为其取名
Now let's create a new collection for indexing documents in your 2-node cluster. Please provide a name for your new collection: [gettingstarted]在后面我们将索引一些solr下称作
techproducts数据的样例数据,所以为了区别于其他的collection,我们将其命名为techproducts。在提示处键入techproducts并回车确认。在两个节点间拆分索引分片
How many shards would you like to split techproducts into? [2]选择默认的2,意味着在两个节点间相对平均地进行索引分片。对于我们的双节点集群来说,默认选项是个好的选择。
为分片创建副本
How many replicas per shard would you like to create? [2]回车默认即可。分片的副本一般会在多个节点中保存,当然此例中仅有两个节点。
为我们创建的collection选择一个配置文件
Please choose a configuration for the techproducts collection, available options are: _default or sample_techproducts_configs [_default]一个collection必须要有一个configSet(sets of configuration files),solr提供了两个可直接使用的configSet
- _default:这是一个最基本的选项
- sample_techproducts_configs:支持我们想要使用的样例数据。
由于本实验将使用solr提供的样例数据,所以回车默认即可。
一个configSet至少包含两个主配置文件schema file(schema.xml或者managed-schema)以及solrConfig.xml
通过solr提供的
bin/post工具采集样例数据bin/post -c techproducts example/exampledocs/*若无报错,可通过 http://ip:8983/solr/#/techproducts/query来访问solr的图形管理界面,如下:
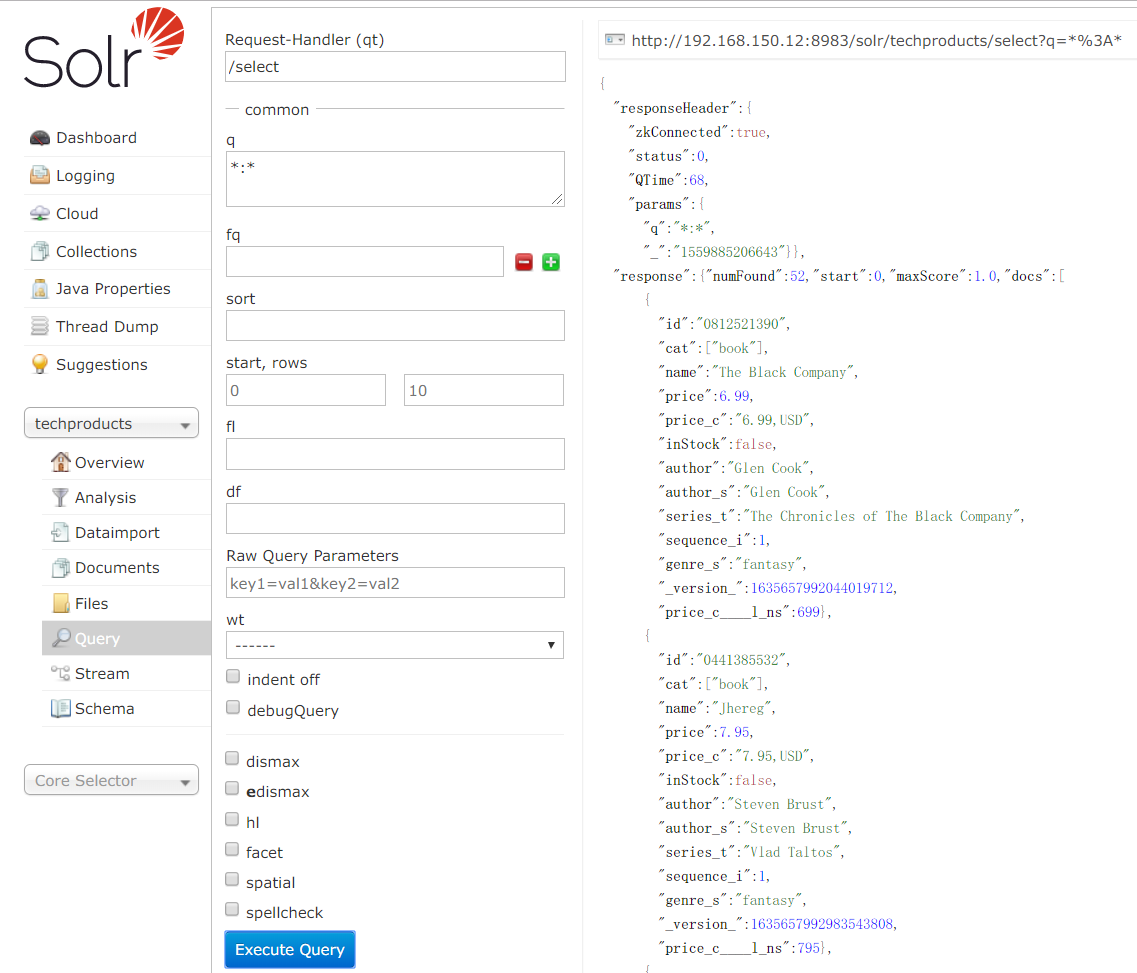
? 下面简单介绍一下这个图形管理界面的一些信息:
标号为q的文本框:qBox。它支持单术语搜索和多术语搜索(即短语搜索),多术语搜索时,只 要其中一个在索引中匹配到了solr就返回其结果。qBox还支持组合搜索,术语前加“+”号,表示必须匹配,相反,加“-”号表示,禁 止匹配该术语。rowsBox限制最大返回条数。
额外补充命令
#删除collection bin/solr delete -c techproducts #创建自己的collection bin/solr create -c <yourCollection> -s 2 -rf 2 #关闭Solr所有的节点 bin/solr stop -all
9. 在启动过程中可能遇到的问题,以及注意事项
以非root用户启动solr,为此创建普通用户solr
useradd solr && echo "1234"|passwd --stdin solrSolr用户对solr的安装目录及其子目录(文件)须得有访问权限,在此我们直接将其所属者改为solr
chown solr:solr /opt/solr-7.7.2安装好
lsof这个工具(用于展示已经打开的文件),solr需要使用这个东西。将solr可执行文件路径导入环境变量,方便操作(直接输入命令,无需加绝对路径)。修改solr家目录下的
.bash_profile或者/etc/profile都可以,修改内容如下:export SOLR_HOME=/opt/solr-7.7.2 export PATH=$PATH:$SOLR_HOME/bin若是在虚拟机或者远程服务器中运行,必须要开启防火墙中相应的端口号。
1.4 练习二:修改Schema和Films Data
重启Solr节点
./bin/solr start -c -p 8983 -s example/cloud/node1/solr
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983什么是schema
schema是一个独立的xml文件,它存储着:
- solr能够理解的字段以及字段类型的详细信息
- 一个字段在索引前所作的修改。
- 支持包含通配符的动态搜索
创建新的collection
因为本练习使用的全新的数据集,所以新建collection。使用默认的configSet,它包含一个最小化的schema,由solr自行根据数据推断出要添加哪些字段信息。
#分别指定collection的名字,shard和replicas的数量
bin/solr create -c films -s 2 -rf 2注:当我们不指定configSet时,他默认就使用_default这个configSet
Preparing Schemaless for the Films Data
使用
_defaultconfigSet,schama有两点注意:- 我们将使用
managed schema,他被配置为只能使用Solr提供的Schema API来做修改。Schema API允许我们修改字段、字段类型以及其他schema规则。 - 使用在
solrconfig.xml中配置的"field guessing"。这使得我们在索引文档前无需手动添加字段,直接启动solr,这就是他叫做schemaless的原因。
但是“field guessing”这种简单粗暴的方式也是有缺陷的。一旦它“guess wrong”,那么你除非重新索引,否则无法修改字段信息。而如果这个索引量非常庞大的话就很可怕了。解决方式:schema api与schemaless混合使用,利用schema api定义一个或几个关键字段,剩余的非关键字段交给solr去guess。
- 我们将使用
Create the "names" Field
- curl命令:定义字段“name”,类型为“text_general”
curl -X POST -H 'Content-type:application/json' --data-binary '"add-field": "name":"name", "type":"text_general", "multiValued":false, "stored":true' http://localhost:8983/solr/films/schema- Admin UI创建
Create a "catchall" Copy Field
从所有字段中采集数据,并建立索引到一个叫做
_text_的字段中。- curl命令
curl -X POST -H 'Content-type:application/json' --data-binary '"add-copy-field" : "source":"*","dest":"_text_"' http://localhost:8983/solr/films/schema- Admin UI创建
索引样例Film Data
#To Index JSON Format
bin/post -c films example/films/films.json
#To Index XML Format
bin/post -c films example/films/films.xml
#To Index CSV Format
bin/post -c films example/films/films.csv -params
"f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|"参数解释
- -c 指定collection的名字。
- /films/films.json (or films.xml or films.csv):指定要采集的数据文件
Faceting
将查询的结果分类,并且统计每个分类的数量
Field Facets
#按"genre"字段分组,并统计数量
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.field=genre_str"
#使用facet.mincount限制返回返回分类数量的最小值
curl "http://localhost:8983/solr/films/select=&q=*:*&facet.field=genre_str&facet.mincount=200&fa
cet=on&rows=0"Range Facets
对返回的结果分段,而不是一堆零碎的结果
curl 'http://localhost:8983/solr/films/select?q=*:*&rows=0''&facet=true''&facet.range=initial_release_date''&facet.range.start=NOW-20YEAR''&facet.range.end=NOW''&facet.range.gap=%2B1YEAR'- facet.range.start:设置最低下限
- facet.range.end:设置最高上限
- facet.range.gap:设置步进
Pivot Facets
允许使用两个至多个字段嵌套为各种可能的组合
#以逗号分隔多字段
#返回某一类型的film由同意导演执导的影片数量
curl "http://localhost:8983/solr/films/selectq=*:*&rows=0&facet=on&facet.pivot=genre_str,directe
d_by_str收尾:删除本实验的collection
bin/solr delete -c films1.5 练习三: Index Your Own Data
在最后一个练习中,我们将探索索引本地数据,而不再是solr提供的样例数据
在实验开始之前,先创建将要使用的collection
bin/solr create -c myfiles -s 2 -rf 2Indexing Ideas(solr索引数据的各种方法)
Local Files with
bin/post数据格式: JSON,XML,CSV,html,PDF,MS word,纯文本等。
数据准备: 假设数据放在家目录下,~/myDocument
数据采集:
bin/post -c myfiles ~/myDocumentDataImportHandler
用于连接数据库、邮件服务,或者其他结构化的数据源
SolrJ
一个用于和Solr交互的,基于java的客户端。通过编码创建文档发送到solr。
Documents Screen
通过Admin UI提供的Document Tab添加索引文档。
Updating Data
无论索引多少次都不会出现相同的结果,因为在schema中指定了唯一字段id。当向Solr添加新的文档,这个唯一值存在重复时,那么新的文档将会自动替换旧的文档。
Deleting Data
清除collection中的数据并不会改变事先对字段的定义。
#删除指定文档
bin/post -c myfiles -d "<delete><id>SP2514N</id></delete>"
#删除所有文档
bin/post -c myfiles -d "<delete><query>*:*</query></delete>"收尾
停止solr,并将环境重置到初始状态
bin/solr stop -all ; rm -Rf example/cloud/2. A Quick Overview
以上是关于Solr学习记录:Getting started的主要内容,如果未能解决你的问题,请参考以下文章
HDLBits——Getting Started & Basics
QT 线程:Getting QObject::startTimer: timers cannot be started from another thread 警告
[翻译] ORMLite document -- Getting Started
Node.js知识学习之——Node.js and MongoDB – Getting started with MongoJS