大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计
Posted feifeicui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计相关的知识,希望对你有一定的参考价值。
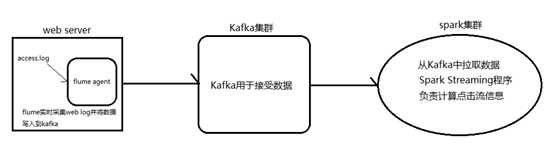
1.安装并配置zk
2.安装并配置Kafka
3.启动zk
4.启动Kafka
5.创建topic
[[email protected] kafka]# bin/kafka-console-producer.sh --broker-list mini1:9092 --topic cyf-test
程序代码
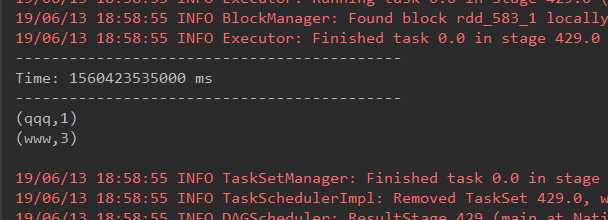
package org.apache.spark import java.net.InetSocketAddress import org.apache.spark.HashPartitioner import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.Seconds import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.flume.FlumeUtils import org.apache.spark.streaming.kafka.KafkaUtils object KafkaWordCount val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => iter.flatMap case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) def main(args: Array[String]) val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaWordCount") val ssc = new StreamingContext(conf, Seconds(5)) //回滚点设置在本地 // ssc.checkpoint("./") //将回滚点写到hdfs ssc.checkpoint("hdfs://mini1:9000/kafkatest") //val Array(zkQuorum, groupId, topics, numThreads) = args val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("mini1:2181,mini2:2181,mini3:2181", "g1", "cyf-test", "2") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2) val results = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) results.print() ssc.start() ssc.awaitTermination()
记一次遇到的问题 https://www.cnblogs.com/feifeicui/p/11018761.html
以上是关于大数据学习——SparkStreaming整合Kafka完成网站点击流实时统计的主要内容,如果未能解决你的问题,请参考以下文章