python学习之爬虫一
Posted lhhhha
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习之爬虫一相关的知识,希望对你有一定的参考价值。
一、爬虫介绍
数据如何获取是重点
何谓爬虫:模拟浏览器向目标服务器发送请求,爬取自己需要的信息,并存入一个文件中。
(1)首先从模拟浏览器开始:
http协议:
请求url:
https://www.baidu.com/
请求方式:
GET
请求头:
Cookie:可能需要关注
User-Agent:需要关注,服务器就是通过此,来判断该段请求的来源是不是浏览器
Host:www.baidu.com(通过分析目标网站的通信流程是什么样的 )
使用谷歌浏览器,任意访问网址,右击,点击检查,出现控制台
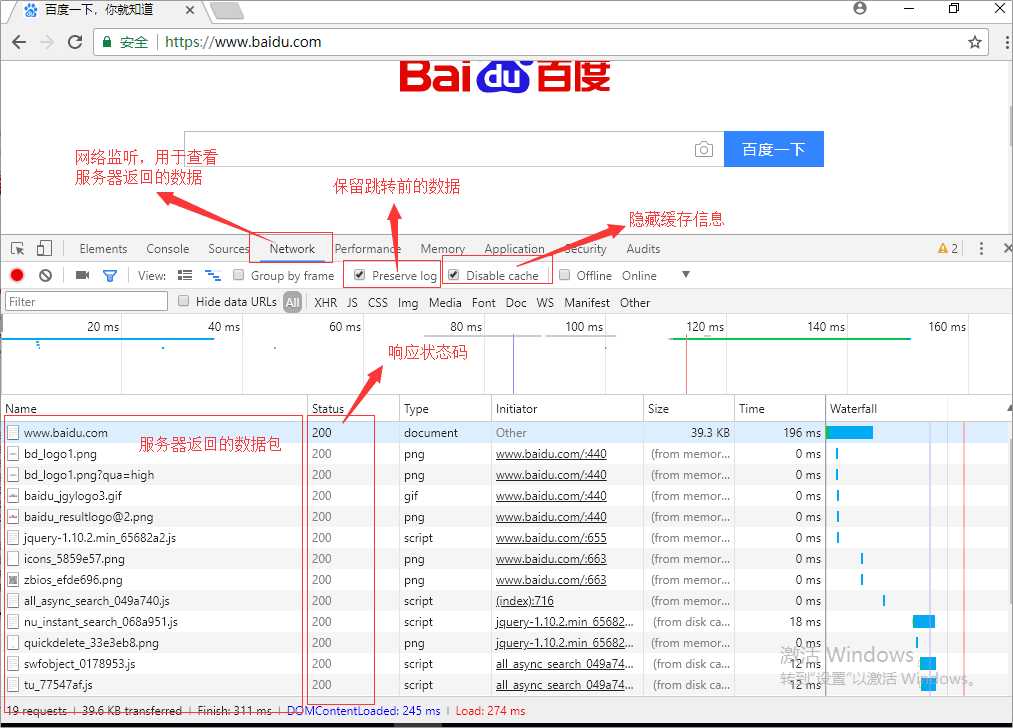
选择如下框起区域,此时再将鼠标移动至自己感兴趣位置,控制台中会出现整个网页的源码,找到地址
具体代码实现如下:
# # requests模块 # # pip3 install requests # # pip3 install -i 清华源地址 模块名 # import requests # response=requests.get(url=‘https://www.baidu.com/‘) # response.encoding=‘utf-8‘ # print(response) # <Response[200]> # # 返回值是以< >括起来的,说明返回的会是对象 # # 返回相应状态码 # print(response.status_code) # # 返回响应文本 # print(response.text) # # print(type(response.text)) # with open(‘baidu.html‘,‘w‘,encoding=‘utf-8‘)as f: # f.write(response.text) import requests # 因为视频和图片返回的都是而二进制即byte res = requests.get(‘https://video.pearvideo.com/mp4/adshort/20190613/cont-1565846-14013215_adpkg-ad_hd.mp4‘) print(res.content) with open(‘视频.mp4‘,‘wb‘)as f: f.write(res.content)
未完待续。。。
以上是关于python学习之爬虫一的主要内容,如果未能解决你的问题,请参考以下文章