Django之ORM操作
Posted qianzhengkai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django之ORM操作相关的知识,希望对你有一定的参考价值。
一些说明:
- 表myapp_person的名称是自动生成的,如果你要自定义表名,需要在model的Meta类中指定 db_table 参数,强烈建议使用小写表名,特别是使用mysql作为后端数据库时。
- id字段是自动添加的,如果你想要指定自定义主键,只需在其中一个字段中指定 primary_key=True 即可。如果Django发现你已经明确地设置了Field.primary_key,它将不会添加自动ID列。
- 本示例中的CREATE TABLE SQL使用PostgreSQL语法进行格式化,但值得注意的是,Django会根据配置文件中指定的数据库后端类型来生成相应的SQL语句。
- Django支持MySQL5.5及更高版本。
1|0Django ORM 常用字段和参数
1|1常用字段
AutoField
int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField
一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存,)
CharField
字符类型,必须提供max_length参数, max_length表示字符长度。
这里需要知道的是Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,但是Django允许我们自定义新的字段,下面我来自定义对应于数据库的char类型
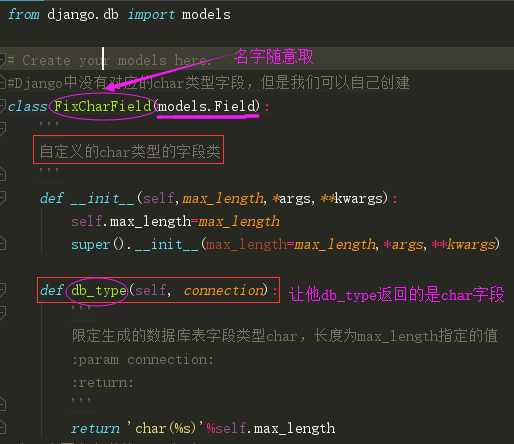
自定义字段在实际项目应用中可能会经常用到,这里需要对他留个印象!
 自定义及使用
自定义及使用
from django.db import models
# Create your models here.
#Django中没有对应的char类型字段,但是我们可以自己创建
class FixCharField(models.Field):
'''
自定义的char类型的字段类
'''
def __init__(self,max_length,*args,**kwargs):
self.max_length=max_length
super().__init__(max_length=max_length,*args,**kwargs)
def db_type(self, connection):
'''
限定生成的数据库表字段类型char,长度为max_length指定的值
:param connection:
:return:
'''
return 'char(%s)'%self.max_length
#应用上面自定义的char类型
class Class(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
class_name=FixCharField(max_length=16)
gender_choice=((1,'男'),(2,'女'),(3,'保密'))
gender=models.SmallIntegerField(choices=gender_choice,default=3)DateField
日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField
日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例。
1|2字段合集(争取记忆)
AutoField(Field)
- int自增列,必须填入参数 primary_key=True
BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True
注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models
class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32)
class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647
BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
BooleanField(Field)
- 布尔值类型
NullBooleanField(Field):
- 可以为空的布尔值
CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度
TextField(Field)
- 文本类型
EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制
IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both"
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL
SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字
UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证
FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]]
DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型
FloatField(Field)
- 浮点型
DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度
BinaryField(Field)
- 二进制类型ORM字段与MySQL字段对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',1|3字段参数
null
用于表示某个字段可以为空。
unique
如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index
如果db_index=True 则代表着为此字段设置索引。
default
为该字段设置默认值。
1|4DateField和DateTimeField
auto_now_add
配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now
配置上auto_now=True,每次更新数据记录的时候会更新该字段。
2|0关系字段
3|0ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 ‘一对多‘中‘多‘的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
3|1字段参数
to
设置要关联的表
to_field
设置要关联的表的字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
models.CASCADE
删除关联数据,与之关联也删除
db_constraint
是否在数据库中创建外键约束,默认为True。
其余字段参数
models.DO_NOTHING
# 删除关联数据,引发错误IntegrityError
models.PROTECT
# 删除关联数据,引发错误ProtectedError
models.SET_NULL
# 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空)
models.SET_DEFAULT
# 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值)
models.SET
# 删除关联数据,
# a. 与之关联的值设置为指定值,设置:models.SET(值)
# b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)def func():
return 10
class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)4|0OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
4|1字段参数
to
设置要关联的表。
to_field
设置要关联的字段。
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。(参考上面的例子)
5|0一般操作
在进行一般操作时先配置一下参数,使得我们可以直接在Django页面中运行我们的测试脚本
6|0在Python脚本中调用Django环境
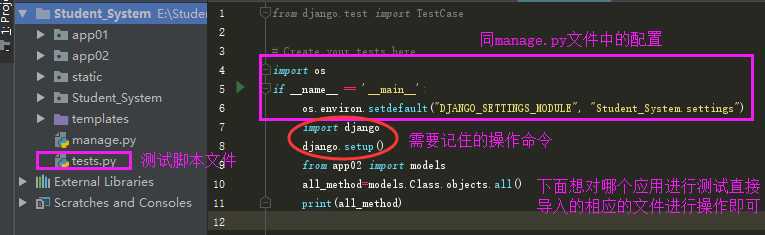
这样就可以直接运行你的test.py文件来运行测试
6|1必知必会13条
操作下面的操作之前,我们实现创建好了数据表,这里主要演示下面的操作,不再细讲创建准备过程
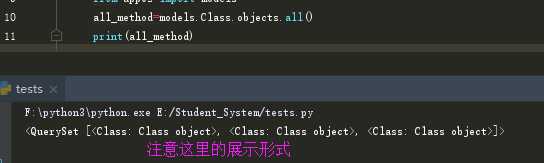
<1> all(): 查询所有结果
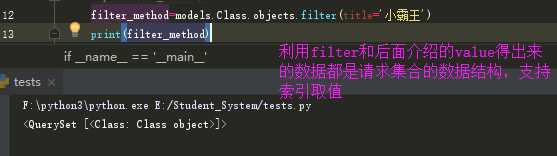
**<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象**
**<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。**
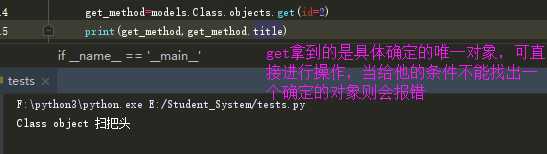

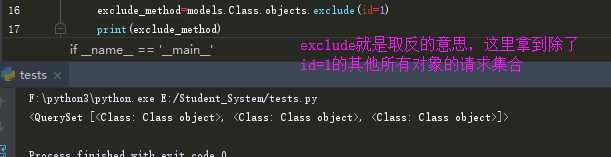
**<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象**
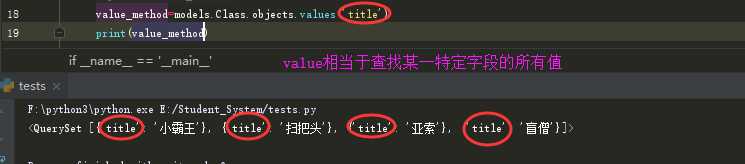
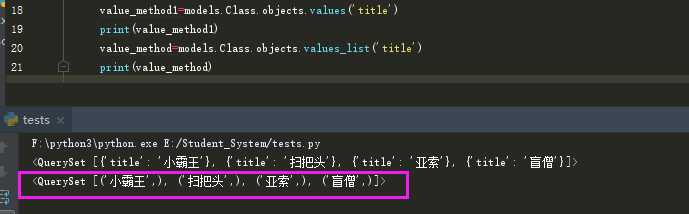
<5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
<6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<7> order_by(*field): 对查询结果排序
<8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。
<9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。)
<10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<11> first(): 返回第一条记录
<12> last(): 返回最后一条记录
<13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
7|013个必会操作总结
返回QuerySet对象的方法有
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元祖序列
返回具体对象的
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有
count()
8|0Django终端打印SQL语句
如果你想知道你对数据库进行操作时,Django内部到底是怎么执行它的sql语句时可以加下面的配置来查看
在Django项目的settings.py文件中,在最后复制粘贴如下代码:
LOGGING =
'version': 1,
'disable_existing_loggers': False,
'handlers':
'console':
'level':'DEBUG',
'class':'logging.StreamHandler',
,
,
'loggers':
'django.db.backends':
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
,
配置好之后,再执行任何对数据库进行操作的语句时,会自动将Django执行的sql语句打印到pycharm终端上
补充:
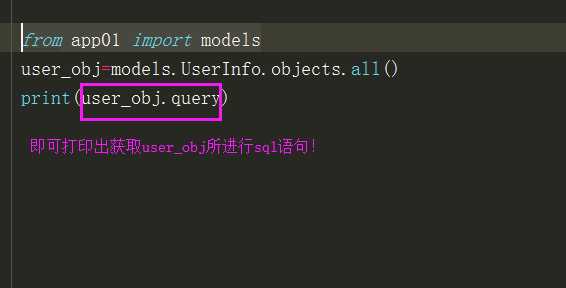
除了配置外,还可以通过一点.query即可查看查询语句,具体操作如下:
6|1单表查询之神奇的双下划线
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and
类似的还有:startswith,istartswith, endswith, iendswith
date字段还可以:
models.Class.objects.filter(first_day__year=2017)
date字段可以通过在其后加__year,__month,__day等来获取date的特点部分数据
# date
#
# Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1))
# Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1))
# year
#
# Entry.objects.filter(pub_date__year=2005)
# Entry.objects.filter(pub_date__year__gte=2005)
# month
#
# Entry.objects.filter(pub_date__month=12)
# Entry.objects.filter(pub_date__month__gte=6)
# day
#
# Entry.objects.filter(pub_date__day=3)
# Entry.objects.filter(pub_date__day__gte=3)
# week_day
#
# Entry.objects.filter(pub_date__week_day=2)
# Entry.objects.filter(pub_date__week_day__gte=2)
需要注意的是在表示一年的时间的时候,我们通常用52周来表示,因为天数是不确定的,老外就是按周来计算薪资的哦~9|0ForeignKey操作
9|1正向查找(两种方式)
1.对象查找(跨表)
语法:
对象.关联字段.字段
要点:先拿到对象,再通过对象去查对应的外键字段,分两步
示例:
book_obj = models.Book.objects.first() # 第一本书对象(第一步)
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称2.字段查找(跨表)
语法:
关联字段**__****字段**
要点:利用Django给我们提供的神奇的双下划线查找方式
示例:
models.Book.objects.all().values("publisher__name")
#拿到所有数据对应的出版社的名字,神奇的下划线帮我们夸表查询9|2反向操作(两种方式)
1.对象查找
语法:
obj.表名_set
要点:先拿到外键关联多对一,一中的某个对象,由于外键字段设置在多的一方,所以这里还是借用Django提供的双下划线来查找
示例:
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名结论:如果想通过一的那一方去查找多的一方,由于外键字段不在一这一方,所以用__set来查找即可
2.字段查找
语法:
**表名__字段**
要点:直接利用双下滑线完成夸表操作
titles = models.Publisher.objects.values("book__title")10|0ManyToManyField
10|1class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是在多对多表关系并且这一张多对多的关系表是有Django自动帮你建的情况下,下面的方法才可使用。
方法
create()
创建一个关联对象,并自动写入数据库,且在第三张双方的关联表中自动新建上双方对应关系。
models.Author.objects.first().book_set.create(title="偷塔秘籍")
上面这一句干了哪些事儿:
1.由作者表中的一个对象跨到书籍比表
2.新增名为偷塔秘籍的书籍并保存
3.到作者与书籍的第三张表中新增两者之间的多对多关系并保存add()
把指定的model对象添加到第三张关联表中。
添加对象
>>> author_objs = models.Author.objects.filter(id__lt=3)
>>> models.Book.objects.first().authors.add(*author_objs)添加id
>>> models.Book.objects.first().authors.add(*[1, 2])set()
更新某个对象在第三张表中的关联对象。不同于上面的add是添加,set相当于重置
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.set([2, 3])remove()
从关联对象集中移除执行的model对象(移除对象在第三张表中与某个关联对象的关系)
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.remove(3)clear()
从关联对象集中移除一切对象。(移除所有与对象相关的关系信息)
>>> book_obj = models.Book.objects.first()
>>> book_obj.authors.clear()注意:
对于ForeignKey对象,clear()和remove()方法仅在null=True时存在。
举个例子:
ForeignKey字段没设置null=True时,
class Book(models.Model):
title = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Publisher)没有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()
Traceback (most recent call last):
File "<input>", line 1, in <module>
AttributeError: 'RelatedManager' object has no attribute 'clear'当ForeignKey字段设置null=True时,
class Book(models.Model):
name = models.CharField(max_length=32)
publisher = models.ForeignKey(to=Class, null=True)此时就有clear()和remove()方法:
>>> models.Publisher.objects.first().book_set.clear()再次强调:
- 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
11|0聚合查询和分组查询
11|1聚合(利用聚合函数)
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
用到的内置函数:
from django.db.models import Avg, Sum, Max, Min, Count示例:
>>> from django.db.models import Avg, Sum, Max, Min, Count
>>> models.Book.objects.all().aggregate(Avg("price"))
'price__avg': 13.233333如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> models.Book.objects.aggregate(average_price=Avg('price'))
'average_price': 13.233333如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> models.Book.objects.all().aggregate(Avg("price"), Max("price"), Min("price"))
'price__avg': 13.233333, 'price__max': Decimal('19.90'), 'price__min': Decimal('9.90')11|2分组
我们在这里先复习一下SQL语句的分组。
假设现在有一张公司职员表:
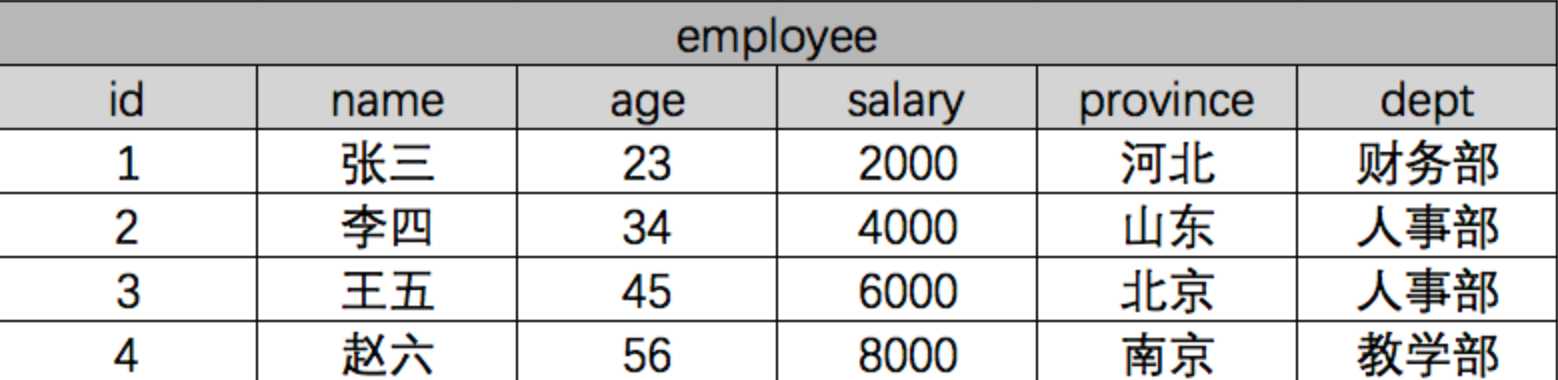
我们使用原生SQL语句,按照部分分组求平均工资:
select dept,AVG(salary) from employee group by dept;ORM查询:
from django.db.models import Avg
Employee.objects.values("dept").annotate(avg=Avg("salary").values(dept, "avg")
这里需要注意的是annotate分组依据就是他前面的值,
如果前面没有特点的字段,则默认按照ID分组,
这里有dept字段,所以按照dept字段分组连表查询的分组:

SQL查询:
select dept.name,AVG(salary) from employee inner join dept on (employee.dept_id=dept.id) group by dept_id;ORM查询:
from django.db.models import Avg
models.Dept.objects.annotate(avg=Avg("employee__salary")).values("name", "avg")更多示例:
示例1:统计每一本书的作者个数
>>> book_list = models.Book.objects.all().annotate(author_num=Count("author"))
>>> for obj in book_list:
... print(obj.author_num)
...
1示例2:统计出每个出版社买的最便宜的书的价格
>>> publisher_list = models.Publisher.objects.annotate(min_price=Min("book__price"))
>>> for obj in publisher_list:
... print(obj.min_price)
...
9.90
19.90方法二:
>>> models.Book.objects.values("publisher__name").annotate(min_price=Min("price"))
<QuerySet ['publisher__name': '沙河出版社', 'min_price': Decimal('9.90'), 'publisher__name': '人民出版社', 'min_price': Decimal('19.90')]>示例3:统计不止一个作者的图书
>>> models.Book.objects.annotate(author_num=Count("author")).filter(author_num__gt=1)
<QuerySet [<Book: 番茄物语>]>示例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
>>> models.Book.objects.annotate(author_num=Count("author")).order_by("author_num")
<QuerySet [<Book: 香蕉物语>, <Book: 橘子物语>, <Book: 番茄物语>]>示例5:查询各个作者出的书的总价格
>>> models.Author.objects.annotate(sum_price=Sum("book__price")).values("name", "sum_price")
<QuerySet ['name': '小精灵', 'sum_price': Decimal('9.90'), 'name': '小仙女', 'sum_price': Decimal('29.80'), 'name': '小魔女', 'sum_price': Decimal('9.90')]>总结
value里面的参数对应的是sql语句中的select要查找显示的字段,
filter里面的参数相当于where或者having里面的筛选条件
annotate本身表示group by的作用,前面找寻分组依据,内部放置显示可能用到的聚合运算式,后面跟filter来增加限制条件,最后的value来表示分组后想要查找的字段值
[ ](
](
以上是关于Django之ORM操作的主要内容,如果未能解决你的问题,请参考以下文章