记一次文件系统故障的修复
Posted zingp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次文件系统故障的修复相关的知识,希望对你有一定的参考价值。
1 故障起因
收到白盒告警:线上机器ip:x.x.x.x 文件系统没有挂载(/search/odin)。
看来得登上机器排查了。
2 df -h看下情况
[@djt_22_168 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 5.4G 32G 15% /
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 8.6M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
tmpfs 783M 0 783M 0% /run/user/0果然/search/odin没了。
3 journalctl看日志
- journalctl 用来查询 systemd-journald 服务收集到的日志。systemd-journald服务是systemd init 系统提供的收集系统日志的服务。
- 使用journalctl -xb;看到错误上是有关I/O的错误,首先想到是不是磁盘问题,搜索/mount,按n逐步搜索,看下有没有错误。
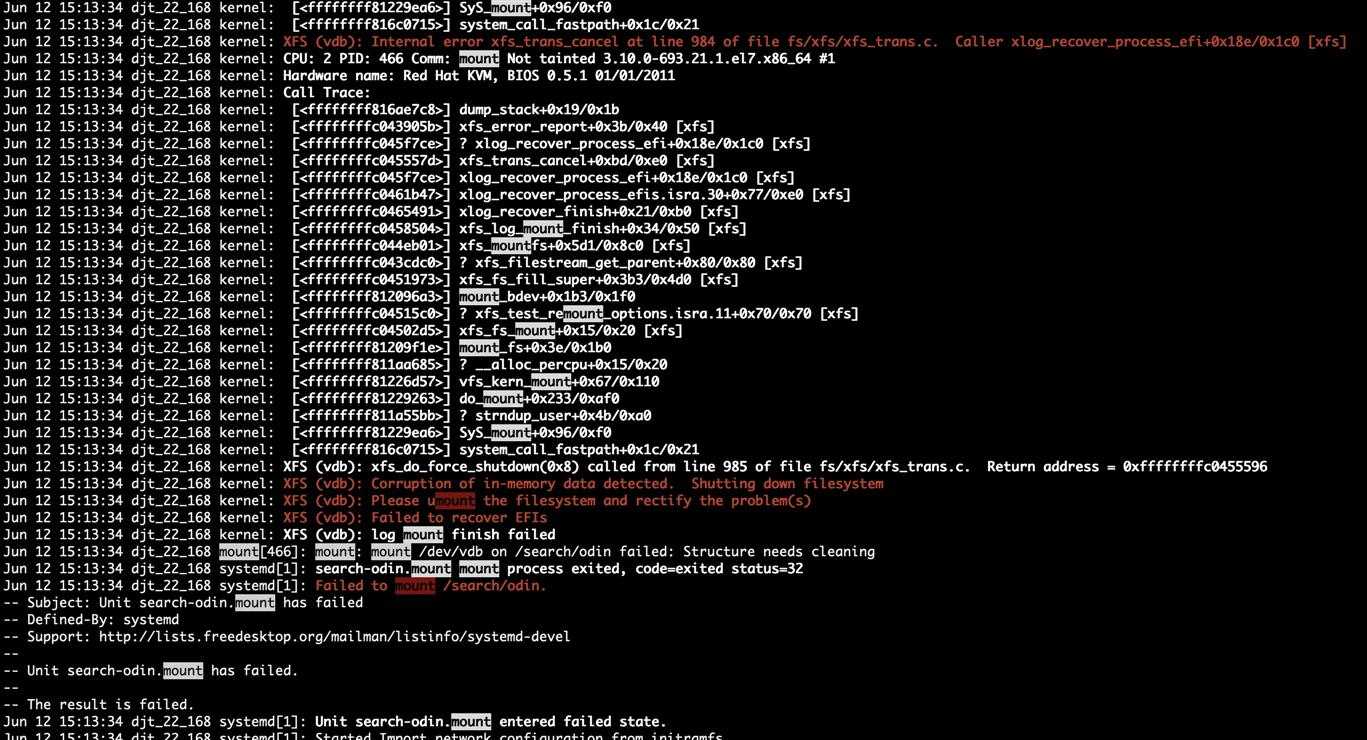
4 尝试挂载
[@djt_22_168 ~]# mount /dev/vdb /search/odin/
mount: mount /dev/vdb on /search/odin failed: Structure needs cleaning这是xfs文件系统,报错需要修复。
5 修复磁盘
- 如果是ext4文件系统,使用命令fsck.ext4 /dev/xxx修复;
- 如果是xfs文件系统,使用命令 xfs_repair -L /dev/xxx修复。
- 一般情况修复后均可挂载,如果磁盘有问题,或者阵列出问题时此种修复可能会失败,挂载时依然要求格盘,那就果断的格盘。
[@djt_22_168 ~]# xfs_repair /dev/vdb
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- zero log...
ERROR: The filesystem has valuable metadata changes in a log which needs to
be replayed. Mount the filesystem to replay the log, and unmount it before
re-running xfs_repair. If you are unable to mount the filesystem, then use
the -L option to destroy the log and attempt a repair.
Note that destroying the log may cause corruption -- please attempt a mount
of the filesystem before doing this.报错,提示使用-L参数:
[@djt_22_168 ~]# xfs_repair -L /dev/vdb
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- zero log...
ALERT: The filesystem has valuable metadata changes in a log which is being
destroyed because the -L option was used.
- scan filesystem freespace and inode maps...
agi unlinked bucket 11 is 7499 in ag 3 (inode=805313867)
sb_icount 7296, counted 13184
sb_ifree 111, counted 644
sb_fdblocks 78500862, counted 59430965
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 3
- agno = 2
Phase 5 - rebuild AG headers and trees...
- reset superblock...
Phase 6 - check inode connectivity...
- resetting contents of realtime bitmap and summary inodes
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
disconnected inode 805313867, moving to lost+found
Phase 7 - verify and correct link counts...
Maximum metadata LSN (815:101693) is ahead of log (1:2).
Format log to cycle 818.
done修复成功。
6 再次挂载
[@djt_22_168 ~]# mount /dev/vdb /search/odin
[@djt_22_168 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 5.4G 32G 15% /
devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 3.9G 8.5M 3.9G 1% /run
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
tmpfs 783M 0 783M 0% /run/user/0
/dev/vdb 300G 74G 227G 25% /search/odin挂载成功。
6 恢复服务
由于我的线上是php+nginx服务,且接入层做过负载均衡。现在修复文件系统需要重新启动php-fpm与nginx,然后就OK了。
以上是关于记一次文件系统故障的修复的主要内容,如果未能解决你的问题,请参考以下文章