爬虫第一章
Posted zty1304368100
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫第一章相关的知识,希望对你有一定的参考价值。
爬虫基础
什么是爬虫?
爬虫是通过程序模拟浏览器上网,从网上获取数据的过程.
爬虫的分类:
通用爬虫:爬取一整个页面的数据.
聚焦爬虫:爬取页面中指定的局部数据
增量式爬虫:检测网站中数据更新的情况,爬取的是网站中最新更新出来的数据.
什么是反爬机制?
网站制作时设置的一系列阻止爬虫程序进行的阻碍,就是反爬机制,反爬机制针对的是爬虫代码.
什么是反反爬机制?
解决反爬机制所使用的策略,反反爬机制针对的是网站.
第一个反爬机制:robots.txt协议
requests模块的应用
requests:
功能强大,操作简单
编码流程:(可以理解成去网页查找东西一样)
1.获取url(找到对应的网站)
2.发送请求(回车)
3.获取响应数据(页面返回给你的数据)
4.持久化存储(将页面返回给你的数据保存到指定位置)
例如:爬取搜狗首页源码数据
import requests msg=input(‘请输入你要搜索的内容:‘) url = ‘https://www.sogou.com/‘ #参数从网页中的form_data中复制过来即可 params= ‘query‘:msg headers = ‘User-Agent‘:‘Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (Khtml, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1‘ response=requests.get(url=url,headers=headers,params=params) page_text=response.text print(page_text)
User-Agent: 请求载体的身份标识
UA检测:门户网站的服务器会检测每一个请求发送过来的UA,如果检测到是爬虫程序,则请求发送失败.
UA伪装:
即在代码中加入User-Agent即可.
爬取肯德基所有上海餐厅的位置
import requests #爬取肯德基所有上海位置的信息 url=‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘ for i in range(1,5):
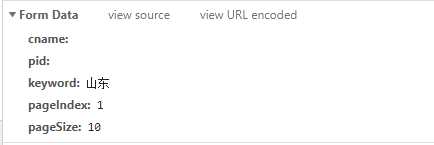
#data中的数据是从网站中的form data中复制过来的 data= ‘cname‘: ‘‘, ‘pid‘: ‘‘, ‘keyword‘: ‘上海‘, ‘pageIndex‘: i, ‘pageSize‘: ‘10‘ headers= ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘ #判断请求方式 response=requests.post(url=url,data=data,headers=headers) page_info=response.json() file=open(‘./kfc.txt‘,‘a+‘,encoding=‘utf-8‘)
#保存数据 for one_info in page_info[‘Table1‘]: file.write(one_info[‘addressDetail‘]+‘\\n‘) file.close()
爬取豆瓣电影的电影详情数据
import requests url = ‘https://movie.douban.com/j/chart/top_list‘ headers= ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘ params= "type": "5", "interval_id": "100:90", "action": "", "start": ‘1‘, "limit": ‘20‘, #判断请求方式 response=requests.get(url=url,params=params,headers=headers) page_text=response.json()
动态加载的页面数据分析:
1.我们通过请求发现,所有的企业数据都是通过动态加载出来的
2.通过抓包工具不过动态加载数据对应的数据包
3.从上一步获取的数据包中提取出企业的相关信息
4.通过分析每一家详情页的url,所有的详情页的url的域名都是相同的,只是id不同
5.在分析详情页中的数据都是通过动态加载出来的,所以这里还是需要抓包工具来对数据进行捕获.
6.可以通过固定的url地址和不同的id进行拼接成企业详情页对应的url.
7.通过对url进行发送请求就可以获取到企业相关的数据了.
爬取药监总局相关的数据http://125.35.6.84:81/xk/
import requests url=‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList‘ headers= ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36‘, for i in range(1,330): data= ‘on‘: ‘true‘, ‘page‘: i, ‘pageSize‘: ‘15‘, ‘productName‘: ‘‘, ‘conditionType‘: ‘1‘, ‘applyname‘: ‘‘, ‘applysn‘: ‘‘, response=requests.post(url=url,headers=headers,data=data) page_info=response.json() page_list=[] for one_info in page_info[‘list‘]: detail_id=one_info[‘ID‘] detail_url=‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById‘ data= ‘id‘: detail_id detail_info=requests.post(url=detail_url,headers=headers,data=data).json() page_list.append(detail_info) fp=open(‘./HZP.txt‘,‘a+‘,encoding=‘utf-8‘) for one_hzp in page_list: fp.write(one_hzp[‘epsName‘]+‘ ‘+one_hzp[‘businessPerson‘]+‘\\n‘) fp.close()
urllib(个人感觉只要返回的形式是2进制流,他都可以返回)
from urllib import request url=‘https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1560235823355&di=4f6c6ad96539247edda08e7ad09f0dee&imgtype=0&src=http%3A%2F%2Fgss0.baidu.com%2F-fo3dSag_xI4khGko9WTAnF6hhy%2Fzhidao%2Fpic%2Fitem%2Fadaf2edda3cc7cd9e3670adb3901213fb80e916d.jpg‘ response=request.urlretrieve(url=url,filename=‘./晓.jpg‘)
http协议和https协议
什么是http协议:客户端和服务端进行数据交互的形式
什么是https协议: 安全的http协议,对传输的数据进行加密
对称秘钥加密(有弊端): 把秘钥和数据一起传送过去
非对称秘钥加密(有弊端): 服务端先发送秘钥,然后客户端按照秘钥形式进行加密,发送过去之后再通过秘钥进行解密
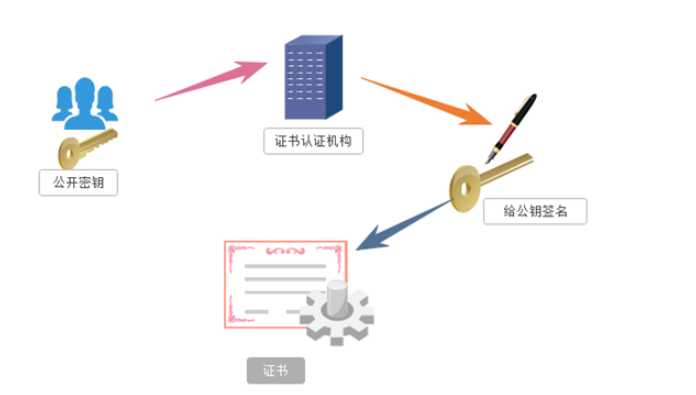
证书秘钥加密(现在普遍应用):服务端先将公开秘钥发送给一个权威的认证机构,认证通过之后给秘钥做标识,然后拿到权威的证书,校验通过之后,客户端通过证书进行加密,服务端通过证书进行解密.
以上是关于爬虫第一章的主要内容,如果未能解决你的问题,请参考以下文章