《推荐系统》基于图的推荐算法
Posted Thinkgamer_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《推荐系统》基于图的推荐算法相关的知识,希望对你有一定的参考价值。
1:概述
2:原理简介
3:代码实现
4:问题说明
一:概述
基于图的模型(graph-based model)是推荐系统中的重要内容。其实,很多研究人员把基于邻域的模型也称为基于图的模型,因为可以把基于邻域的模型看做基于图的模型的简单形式
在研究基于图的模型之前,首先需要将用户的行为数据,表示成图的形式,下面我们讨论的用户行为数据是用二元数组组成的,其中每个二元组(u,i)表示用户u对物品i的产生过行为,这种数据很容易用一个二分图表示
令G(V,E)表示用户物品二分图,其中 由用户顶点集合
由用户顶点集合 和物品顶点集合
和物品顶点集合 组成。对于数据集中每一个二元组(u, i),图中都有一套对应的边
组成。对于数据集中每一个二元组(u, i),图中都有一套对应的边 ,其中
,其中 是用户u对应的顶点,
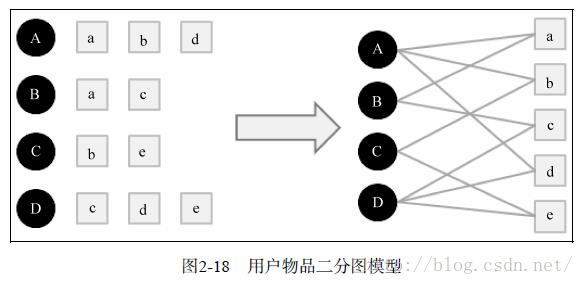
是用户u对应的顶点,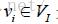 是物品i对应的顶点。图2-18是一个简单的用户物品二分图模型,其中圆形节点代表用户,方形节点代表物品,圆形节点和方形节点之间的边代表用户对物品的行为。比如图中用户节点A和物品节点a、b、d相连,说明用户A对物品a、b、d产生过行为。
是物品i对应的顶点。图2-18是一个简单的用户物品二分图模型,其中圆形节点代表用户,方形节点代表物品,圆形节点和方形节点之间的边代表用户对物品的行为。比如图中用户节点A和物品节点a、b、d相连,说明用户A对物品a、b、d产生过行为。
二:原理简介
将用户的行为数据表示为二分图后,接下来的就是基于二分图为用户进行推荐,那么给用户u推荐物品就可以转化为度量用户顶点Vu和Vu没有直接边相连的顶点在图上的相关性,相关性越高的物品在推荐列表上的权重九越高,推荐位置就越靠前。
那么如何评价两个顶点的相关性?一般取决于三个因素
1:两个顶点之间的路径数
2:两个顶点之间路径的长度
3:两个顶点之间的路径经过的顶点
而相关性较高的一对顶点一般具有如下特征:
1:两个顶点之间有很多路径相连
2:连接两个顶点之间的路径长度都比较短
3:连接两个顶点之间的路径不会经过出度比较大的顶点
举一个简单的例子,如图2-19所示,用户A和物品c、e没有边相连,但是用户A和物品c有1条长度为3的路径相连,用户A和物品e有2条长度为3的路径相连。那么,顶点A与e之间的相关性要高于顶点A与c,因而物品e在用户A的推荐列表中应该排在物品c之前,因为顶点A与e之间有两条路径——(A, b, C, e)和(A, d, D, e)。其中,(A, b, C, e)路径经过的顶点的出度为(3, 2, 2,2),而(A, d, D, e)路径经过的顶点的出度为(3, 2, 3, 2)。因此,(A, d, D, e)经过了一个出度比较大的顶点D,所以(A, d, D, e)对顶点A与e之间相关性的贡献要小于(A, b, C, e)。

下面介绍一种基于随机游走的PersonalRank算法(和PangRank算法相似,pageRank算法参考)
假设要给用户u进行个性化推荐,可以从用户u对应的节点Vu开始在用户物品二分图上进行随机游走。游走到任何一个节点时,首先按照概率α决定是继续游走,还是停止这次游走并从Vu节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中物品的权重就是物品节点的访问概率。
如果将上面的描述表示成公式,可以得到如下公式:

alpha表示随机游走的概率 PR(v')表示访问v'的概率 out(v')表示v'指向的顶点集合
三:代码实现
#-*-coding:utf-8-*-
'''
Created on 2016年6月16日
@author: Gamer Think
'''
'''
G:二分图 alpha:随机游走的概率 root:游走的初始节点 max_step;最大走动步数
'''
def PersonalRank(G, alpha, root, max_step):
rank = dict()
rank = {x:0 for x in G.keys()}
rank[root] = 1
#开始迭代
for k in range(max_step):
tmp = {x:0 for x in G.keys()}
#取节点i和它的出边尾节点集合ri
for i, ri in G.items(): #i是顶点。ri是与其相连的顶点极其边的权重
#取节点i的出边的尾节点j以及边E(i,j)的权重wij, 边的权重都为1,在这不起实际作用
for j, wij in ri.items(): #j是i的连接顶点,wij是权重
#i是j的其中一条入边的首节点,因此需要遍历图找到j的入边的首节点,
#这个遍历过程就是此处的2层for循环,一次遍历就是一次游走
tmp[j] += alpha * rank[i] / (1.0 * len(ri))
#我们每次游走都是从root节点出发,因此root节点的权重需要加上(1 - alpha)
#在《推荐系统实践》上,作者把这一句放在for j, wij in ri.items()这个循环下,我认为是有问题。
tmp[root] += (1 - alpha)
rank = tmp
#输出每次迭代后各个节点的权重
print 'iter: ' + str(k) + "\\t",
for key, value in rank.items():
print "%s:%.3f, \\t"%(key, value),
print
return rank
'''
主函数,G表示二分图,‘A’表示节点,后边对应的字典的key是连接的顶点,value表示边的权重
'''
if __name__ == '__main__':
G = {'A' : {'a' : 1, 'c' : 1},
'B' : {'a' : 1, 'b' : 1, 'c':1, 'd':1},
'C' : {'c' : 1, 'd' : 1},
'a' : {'A' : 1, 'B' : 1},
'b' : {'B' : 1},
'c' : {'A' : 1, 'B' : 1, 'C':1},
'd' : {'B' : 1, 'C' : 1}}
PersonalRank(G, 0.85, 'A', 100) 
结果说明:

与A相关度最高的依次是 A(0.269),c(0.190),B(0.185),a(0.154),C(0.086),d(0.076),b(0.039),去除A已经连接的a,c,剩下的推荐依次为B,a,C,d,b
四:问题说明
虽然PersonalRank算法可以通过随机游走进行比较好的理论解释,但该算法在时间复杂度上有明显的缺点。因为在为每个用户进行推荐时,都需要在整个用户物品二分图上进行迭代,直到整个图上的每个顶点的PR值收敛。这一过程的时间复杂度非常高,不仅无法在线提供实时推荐,甚至离线生成推荐结果也很耗时。
为了解决PersonalRank每次都需要在全图迭代并因此造成时间复杂度很高的问题,这里给出两种解决方案。第一种很容易想到,就是减少迭代次数,在收敛之前就停止。这样会影响最终的精度,但一般来说影响不会特别大。另一种方法就是从矩阵论出发,重新设计算法。
对矩阵运算比较熟悉的读者可以轻松将PersonalRank转化为矩阵的形式。令M为用户物品二分图的转移概率矩阵,即:

那么,迭代公式可以转化为:
对矩阵论稍微熟悉的读者都可以解出上面的方程,得到:
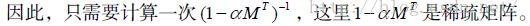
以上是关于《推荐系统》基于图的推荐算法的主要内容,如果未能解决你的问题,请参考以下文章