[Nutch]编译hadoop出现object[]无法转换为K[]问题解决
Posted kandy_ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Nutch]编译hadoop出现object[]无法转换为K[]问题解决相关的知识,希望对你有一定的参考价值。
1. 问题描述
在使用JDK8编译hadoop 1.2.1的时候会出现object[]无法转换为K[]的问题,如下:
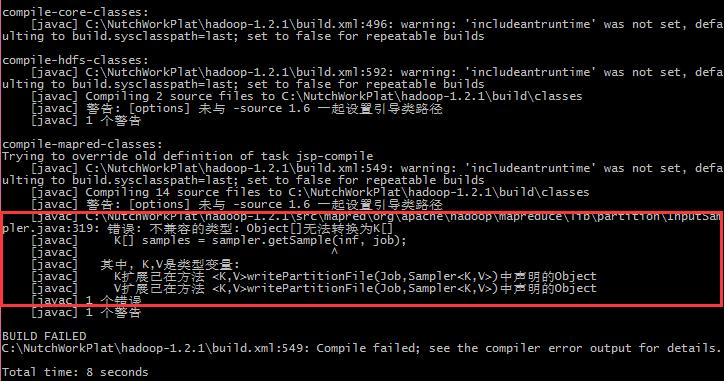
2. 问题解决
(1)打开hadoop目录下的InputSampler.java文件,路径如下:
hadoop-1.2.1\\src\\mapred\\org\\apache\\hadoop\\mapreduce\\lib\\partition\\InputSampler.java
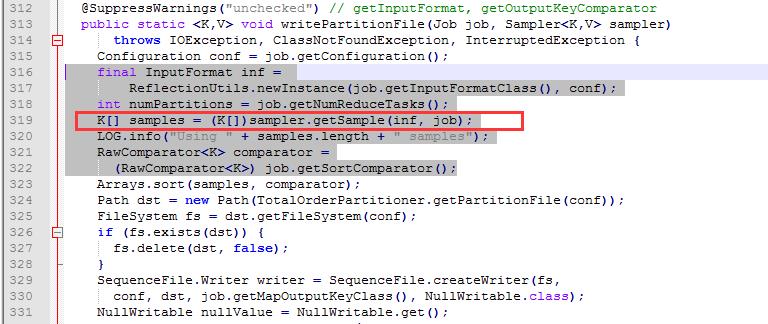
(2)大概319行找到如下内容:
final InputFormat inf =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
int numPartitions = job.getNumReduceTasks();
K[] samples = sampler.getSample(inf, job);
LOG.info("Using " + samples.length + " samples");
RawComparator<K> comparator =
(RawComparator<K>) job.getSortComparator();将其修改为:
final InputFormat inf =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
int numPartitions = job.getNumReduceTasks();
K[] samples = (K[])sampler.getSample(inf, job);
LOG.info("Using " + samples.length + " samples");
RawComparator<K> comparator =
(RawComparator<K>) job.getSortComparator();如下图:
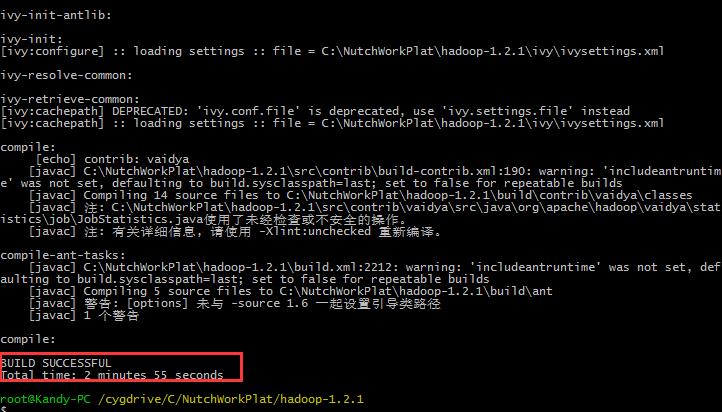
3. 重新编译
以上是关于[Nutch]编译hadoop出现object[]无法转换为K[]问题解决的主要内容,如果未能解决你的问题,请参考以下文章