KNN
Posted uniquecolor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNN相关的知识,希望对你有一定的参考价值。
一、KNN分类算法
K最近邻(K-Nearest Neighbor,KNN)算法,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。
通常,在分类任务中可使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
二、算法图示
◊ 从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
◊算法涉及3个主要因素:
1) 训练数据集
2) 距离或相似度的计算衡量
3) k的大小
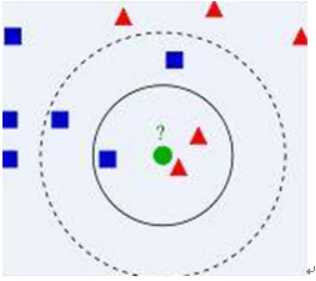
◊算法描述
1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中
2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类
3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别
三、KNN分类算法python实现(python2.7)
需求:
有以下先验数据,使用knn算法对未知类别数据分类
|
属性1 |
属性2 |
类别 |
|
1.0 |
0.9 |
A |
|
1.0 |
1.0 |
A |
|
0.1 |
0.2 |
B |
|
0.0 |
0.1 |
B |
未知类别数据
|
属性1 |
属性2 |
类别 |
|
1.2 |
1.0 |
? |
|
0.1 |
0.3 |
? |
KNN.py
# coding=utf-8 ######################################### # kNN: k Nearest Neighbors # 输入: newInput: (1xN)的待分类向量 # dataSet: (NxM)的训练数据集 # labels: 训练数据集的类别标签向量 # k: 近邻数 # 输出: 可能性最大的分类标签 ######################################### from numpy import * import operator # 创建一个数据集,包含2个类别共4个样本 def createDataSet(): # 生成一个矩阵,每行表示一个样本 group = array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]]) # 4个样本分别所属的类别 labels = [‘A‘, ‘A‘, ‘B‘, ‘B‘] return group, labels # KNN分类算法函数定义 def kNNClassify(newInput, dataSet, labels, k): numSamples = dataSet.shape[0] # shape[0]表示行数 # # step 1: 计算距离[ # 假如: # Newinput:[1,0,2] # Dataset: # [1,0,1] # [2,1,3] # [1,0,2] # 计算过程即为: # 1、求差 # [1,0,1] [1,0,2] # [2,1,3] -- [1,0,2] # [1,0,2] [1,0,2] # = # [0,0,-1] # [1,1,1] # [0,0,-1] # 2、对差值平方 # [0,0,1] # [1,1,1] # [0,0,1] # 3、将平方后的差值累加 # [1] # [3] # [1] # 4、将上一步骤的值求开方,即得距离 # [1] # [1.73] # [1] # # ] # tile(A, reps): 构造一个矩阵,通过A重复reps次得到 # the following copy numSamples rows for dataSet diff = tile(newInput, (numSamples, 1)) - dataSet # 按元素求差值 squaredDiff = diff ** 2 # 将差值平方 squaredDist = sum(squaredDiff, axis = 1) # 按行累加 distance = squaredDist ** 0.5 # 将差值平方和求开方,即得距离 # # step 2: 对距离排序 # argsort() 返回排序后的索引值 sortedDistIndices = argsort(distance) classCount = # define a dictionary (can be append element) for i in xrange(k): # # step 3: 选择k个最近邻 voteLabel = labels[sortedDistIndices[i]] # # step 4: 计算k个最近邻中各类别出现的次数 # when the key voteLabel is not in dictionary classCount, get() # will return 0 classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # # step 5: 返回出现次数最多的类别标签 maxCount = 0 for key, value in classCount.items(): if value > maxCount: maxCount = value maxIndex = key return maxIndex
KNNTest.py
#!/usr/bin/python # coding=utf-8 from KNN import KNN from numpy import * # 生成数据集和类别标签 dataSet, labels = KNN.createDataSet() # 定义一个未知类别的数据 testX = array([1.2, 1.0]) k = 3 # 调用分类函数对未知数据分类 outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3) print "Your input is:", testX, "and classified to class: ", outputLabel testX = array([0.1, 0.3]) outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3) print "Your input is:", testX, "and classified to class: ", outputLabel
结果:
Your input is: [1.2 1. ] and classified to class: A Your input is: [0.1 0.3] and classified to class: B
以上是关于KNN的主要内容,如果未能解决你的问题,请参考以下文章