Kafka partition 副本迁移与broker上下线
Posted zhy-heaven
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka partition 副本迁移与broker上下线相关的知识,希望对你有一定的参考价值。
Kafka partition 副本迁移与broker上下线
1 前言
Controller 在初始化时,会利用 ZK 的 watch 机制注册很多不同类型的监听器,当监听的事件被触发时,Controller 就会触发相应的操作。
Controller 在初始化时,会注册多种类型的监听器,主要有以下几种:
- l 监听 /admin/reassign_partitions 节点,用于分区副本迁移的监听;
- l 监听 /isr_change_notification 节点,用于 Partition Isr 变动的监听,;
- l 监听 /admin/preferred_replica_election 节点,用于需要进行 Partition 最优 leader 选举的监听;
- l 监听 /brokers/topics 节点,用于 Topic 新建的监听;
- l 监听 /brokers/topics/TOPIC_NAME 节点,用于 Topic Partition 扩容的监听;
- l 监听 /admin/delete_topics 节点,用于 Topic 删除的监听;
- l 监听 /brokers/ids 节点,用于 Broker 上下线的监听。
2 Partition 副本迁移整体流程
Partition 的副本迁移实际上就是将分区的副本重新分配到不同的代理节点上,如果 zk 中新副本的集合与 Partition 原来的副本集合相同,那么这个副本就不需要重新分配了。
Partition 的副本迁移是通过监听 zk 的 /admin/reassign_partitions 节点触发的,Kafka 也向用户提供相应的脚本工具进行副本迁移,副本迁移的脚本使用方法如下所示:

在调用脚本向 zk 提交 Partition 的迁移计划时,迁移计划更新到 zk 前需要进行一步判断,如果该节点(写入迁移计划的节点)已经存在,即副本迁移还在进行,那么本次副本迁移计划是无法提交的,实现的逻辑如下所示:
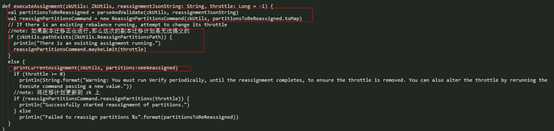
2.1 ZK PartitionsReassignedListener 副本迁移处理
在 zk 的 /admin/reassign_partitions 节点数据有变化时,就会触发 PartitionsReassignedListener 的 doHandleDataChange() 方法,实现如下:
如果 Partition 出现下面的情况,将不会进行副本迁移,直接将 Partition 的迁移计划从 ZK 移除:
- l 这个 Partition 的 reassignment 之前已经存在, 即正在迁移中;
- l 这个 Partition 新分配的 replica 与之前的 replicas 相同;
- l 这个 Partition 所有新分配 replica 都已经 dead;
- l 这个 Partition 已经被设置了删除标志。
对于可以进行副本迁移的 Partition 集合,这里将会调用 Kafka Controller 的 initiateReassignReplicasForTopicPartition() 方法对每个 Partition 进行处理。
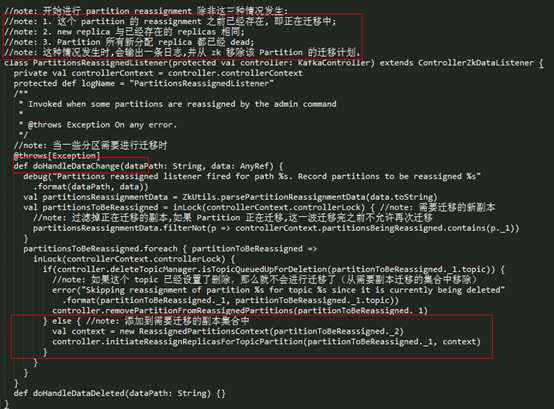
2.2 副本迁移初始化
进行了前面的判断后,这个 Partition 满足了可以迁移的条件,Controller 会首先初始化副本迁移的流程,实现如下所示
对于副本迁移流程初始化如下:
- l 通过 watchIsrChangesForReassignedPartition() 方法监控这个 Partition 的 LeaderAndIsr 变化,如果有新的副本数据同步完成,那么 leader 会将其加到 isr 中更新到 zk 中,这时候 Controller 是可以接收到相关的信息通知的;
- l 将正在迁移的 Partition 添加到 partitionsBeingReassigned 中,它会记录当前正在迁移的 Partition 列表;
- l 将要迁移的 Topic 设置为非法删除删除状态,在这个状态的 Topic 是无法进行删除的;
- l 调用 onPartitionReassignment(),进行副本迁移。
在第一步中,会向这个 Partition 注册一个额外的监听器,监听其 LeaderAndIsr 信息变化,如下所示:
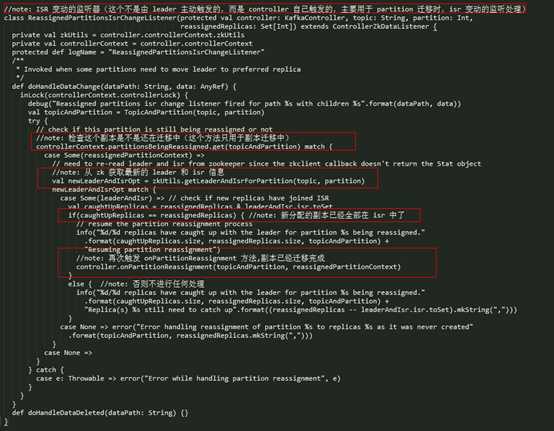
如果该 Partition 的 LeaderAndIsr 信息有变动,那么就会触发这个 listener 的 doHandleDataChange() 方法:
- l 首先检查这个 Partition 是否在还在迁移中,不在的话直接结束流程,因为这个监听器本来就是为了 Partition 副本迁移而服务的;
- l 从 zk 获取最新的 leader 和 isr 信息,如果新分配的副本全部都在 isr 中,那么就再次触发 controller 的 onPartitionReassignment() 方法,再次调用时实际上已经证明了这个 Partition 的副本迁移已经完成,否则的话就会不进行任何处理,等待新分配的所有副本迁移完成。
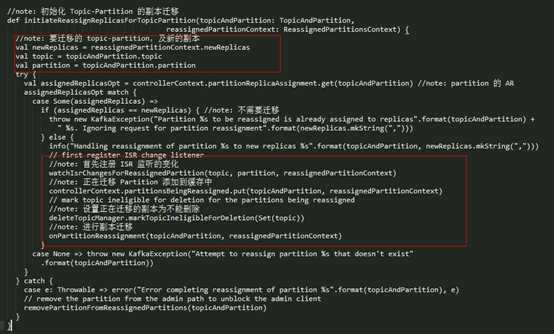
2.3 副本迁移
Partition 副本迁移真正实际处理是在 Controller 的 onPartitionReassignment() 方法完成的,在看这个方法之前,先介绍几个基本的概念(假设一个 Partition 原来的 replica 是 1、2、3,新分配的副本列表是:2、3、4):
- RAR = Reassigned replicas,即新分配的副本列表,也就是 2、3、4;
- OAR = Original list of replicas for partition,即这个 Partition 原来的副本列表,也就是 1、2、3;
- AR = current assigned replicas,该 Partition 当前的副本列表,这个会随着阶段的不同而变化;
- RAR-OAR:需要创建、数据同步的新副本,也就是 4;
- OAR-RAR:需要删除的副本,也就是1
这个方法的实现如下所示:
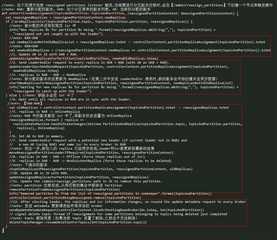
这个方法整体分为以下12个步骤:
- l 把 AR = OAR+RAR (1、2、3、4)更新到 zk 及本地 Controller 缓存中;
- l 发送 LeaderAndIsr 给 AR 中每一个副本,并且会强制更新 zk 中 leader 的 epoch;
- l 创建需要新建的副本(【RAR-OAR】,即 4),将其状态设置为 NewReplica;
- l 等待直到 RAR(2、3、4) 中的所有副本都在 ISR 中;
- l 把 RAR(2、3、4) 中的所有副本设置为 OnReplica 状态;
- l 将缓存中 AR 更新为 RAR(重新分配的副本列表,即 2、3、4);
- l 如果 leader 不在 RAR 中, 就从 RAR 选择对应的 leader, 然后发送 LeaderAndIsr 请求;如果不需要,那么只会更新 leader epoch,然后发送 LeaderAndIsr 请求; 在发送 LeaderAndIsr 请求前设置了 AR=RAR, 这将确保了 leader 在 isr 中不会添加任何 【RAR-OAR】中的副本(old replica,即 1);
- l 将【OAR-RAR】(1)中的副本设置为 OfflineReplica 状态,OfflineReplica 状态的变化,将会从 ISR 中删除【OAR-RAR】的副本,更新到 zk 中并发送 LeaderAndIsr 请求给 leader,通知 leader isr 变动。之后再发送 StopReplica 请求(delete=false)给【OAR-RAR】中的副本;
- l 将【OAR-RAR】中的副本设置为 NonExistentReplica 状态。这将发送 StopReplica 请求(delete=true)给【OAR-RAR】中的副本,这些副本将会从本地上删除数据;
- l 在 zk 中更新 AR 为 RAR;
- l 更新 zk 中路径 【/admin/reassign_partitions】信息,移除已经成功迁移的 Partition;
- l leader 选举之后,这个 replica 和 isr 信息将会变动,发送 metadata 更新给所有的 broker。
上面的流程简单来说,就是先创建新的 replica,开始同步数据,等待所有新的分配都加入到了 isr 中后,开始进行 leader 选举(需要的情况下),下线不需要的副本(OAR-RAR),下线完成后将 Partition 的最新 AR (即 RAR)信息更新到 zk 中,最后发送相应的请求给 broker,到这里一个 Partition 的副本迁移算是完成了。
3 Broker上下线
每台 Broker 在上线时,都会与 ZK 建立一个建立一个 session,并在 /brokers/ids 下注册一个节点,节点名字就是 broker id,这个节点是临时节点,该节点内部会有这个 Broker 的详细节点信息。Controller 会监听 /brokers/ids 这个路径下的所有子节点,如果有新的节点出现,那么就代表有新的 Broker 上线,如果有节点消失,就代表有 broker 下线,Controller 会进行相应的处理,Kafka 就是利用 ZK 的这种 watch 机制及临时节点的特性来完成集群 Broker 的上下线。
3.1 ZK 回调处理
BrokerChangeListener 是监听 /brokers/ids 节点的监听器,当该节点有变化时会触发 doHandleChildChange() 方法,具体实现如下:
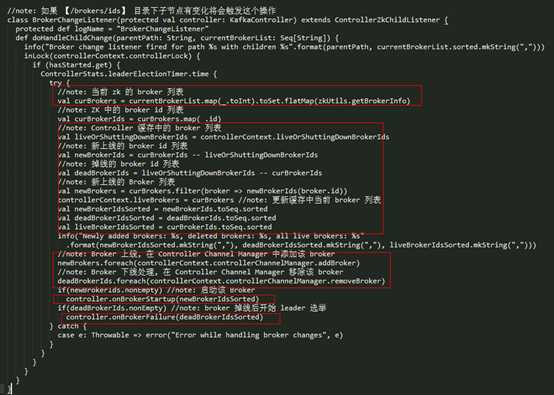
这里需要重点关注 doHandleChildChange() 方法的实现,该方法处理逻辑如下:
- l 从 ZK 获取当前的 Broker 列表(curBrokers)及 broker id 的列表(curBrokerIds);
- l 获取当前 Controller 中缓存的 broker id 列表(liveOrShuttingDownBrokerIds);
- l 获取新上线 broker id 列表:newBrokerIds = curBrokerIds – liveOrShuttingDownBrokerIds;
- l 获取掉线的 broker id 列表:deadBrokerIds = liveOrShuttingDownBrokerIds – curBrokerIds;
- l 对于新上线的 broker,先在 ControllerChannelManager 中添加该 broker(即建立与该 Broker 的连接、初始化相应的发送线程和请求队列),最后 Controller 调用 onBrokerStartup() 上线该 Broker;
- l 对于掉线的 broker,先在 ControllerChannelManager 中移除该 broker(即关闭与 Broker 的连接、关闭相应的发送线程和清空请求队列),最后 Controller 调用 onBrokerFailure() 下线该 Broker。
3.2 broker上线
一台 Broker 上线主要有以下两步:
- l 在 Controller Channel Manager 中添加该 Broker 节点,主要的内容是:Controller 建立与该 Broker 的连接、初始化相应的请求发送线程与请求队列;
- l 调用 Controller 的 onBrokerStartup() 方法上线该节点。
ontroller Channel Manager 添加 Broker 的实现如下,这里就不重复讲述了,前面讲述 Controller 服务初始化的文章已经讲述过这部分的内容。下面再看下 Controller 如何在 onBrokerStartup() 方法中实现 Broker 上线操作的,具体实现如下所示:
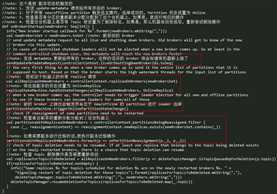
onBrokerStartup() 方法在实现的逻辑上分为以下几步:
- l 调用
sendUpdateMetadataRequest()方法向当前集群所有存活的 Broker 发送 Update Metadata 请求,这样的话其他的节点就会知道当前的 Broker 已经上线了; - l 获取当前节点分配的所有的 Replica 列表,并将其状态转移为 OnlineReplica 状态;
- l 触发 PartitionStateMachine 的
triggerOnlinePartitionStateChange()方法,为所有处于 NewPartition/OfflinePartition 状态的 Partition 进行 leader 选举,如果 leader 选举成功,那么该 Partition 的状态就会转移到 OnlinePartition 状态,否则状态转移失败; - l 如果副本迁移中有新的 Replica 落在这台新上线的节点上,那么开始执行副本迁移操作;
- l 如果之前由于这个 Topic 设置为删除标志,但是由于其中有 Replica 掉线而导致无法删除,这里在节点启动后,尝试重新执行删除操作。
到此为止,一台 Broker 算是真正加入到了 Kafka 的集群中,在上述过程中,涉及到 leader 选举的操作,都会触发 LeaderAndIsr 请求及 Metadata 请求的发送。
3.3 broker下线
一台 Broker 掉线后主要有以下两步:
l 首先在 Controller Channel Manager 中移除该 Broker 节点,主要的内容是:关闭 Controller 与 Broker 的连接和相应的请求发送线程,并清空请求队列;
l 调用 Controller 的 onBrokerFailure() 方法下线该节点。
Controller Channel Manager 下线 Broker 的处理如下所示:
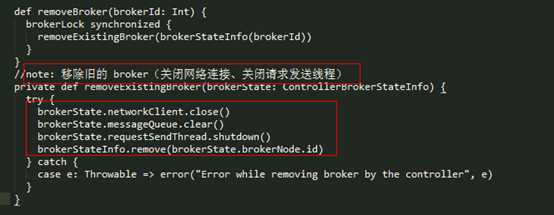
在 Controller Channel Manager 处理完掉线的 Broker 节点后,下面 KafkaController 将会调用 onBrokerFailure() 进行相应的处理,其实现如下:
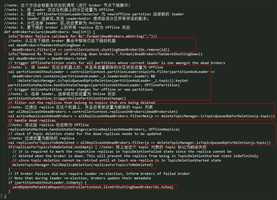
Controller 对于掉线 Broker 的处理过程主要有以下几步:
- l 首先找到 Leader 在该 Broker 上所有 Partition 列表,然后将这些 Partition 的状态全部转移为 OfflinePartition 状态;
- l 触发 PartitionStateMachine 的 triggerOnlinePartitionStateChange() 方法,为所有处于 NewPartition/OfflinePartition 状态的 Partition 进行 Leader 选举,如果 Leader 选举成功,那么该 Partition 的状态就会迁移到 OnlinePartition 状态,否则状态转移失败(Broker 上线/掉线、Controller 初始化时都会触发这个方法);
- l 获取在该 Broker 上的所有 Replica 列表,将其状态转移成 OfflineReplica 状态;
- l 过滤出设置为删除、并且有副本在该节点上的 Topic 列表,先将该 Replica 的转移成 ReplicaDeletionIneligible 状态,然后再将该 Topic 标记为非法删除,即因为有 Replica 掉线导致该 Topic 无法删除;
- l 如果 leader 在该 Broker 上所有 Partition 列表不为空,证明有 Partition 的 leader 需要选举,在最后一步会触发全局 metadata 信息的更新。
到这里,一台掉线的 Broker 算是真正下线完成了。
3.4 主动关闭broker
Controller 在接收这个关闭服务的请求,通过 shutdownBroker() 方法进行处理,实现如下所示:
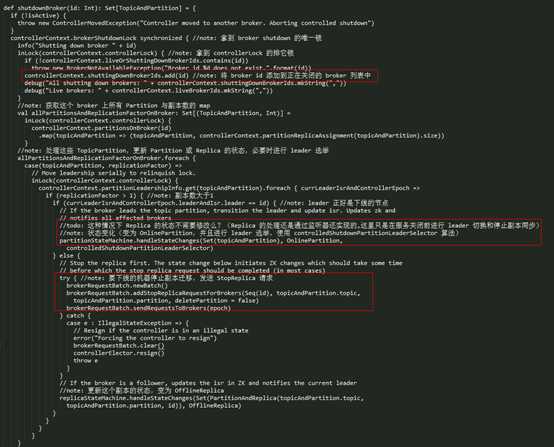

上述方法的处理逻辑如下:
- l 先将要下线的 Broker 添加到 shuttingDownBrokerIds 集合中,该集合记录了当前正在进行关闭的 broker 列表;
- l 获取副本在该节点上的所有 Partition 的列表集合;
- l 遍历上述 Partition 列表进行处理:如果该 Partition 的 leader 是要下线的节点,那么通过 PartitionStateMachine 进行状态转移(OnlinePartition –> OnlinePartition)触发 leader 选举,使用的 leader 选举方法是 ControlledShutdownLeaderSelector,它会选举 isr 中第一个没有正在关闭的 Replica 作为 leader,否则抛出 StateChangeFailedException 异常;
- l 否则的话,即要下线的节点不是 leader,那么就向要下线的节点发送 StopReplica 请求停止副本同步,并将该副本设置为 OfflineReplica 状态,这里对 Replica 进行处理的原因是为了让要下线的机器关闭副本同步流程,这样 Kafka 服务才能正常关闭。
参考资料:
http://matt33.com/2018/06/16/partition-reassignment/
http://matt33.com/2018/06/17/broker-online-offline/
以上是关于Kafka partition 副本迁移与broker上下线的主要内容,如果未能解决你的问题,请参考以下文章