Latent Semantic Analysis(LSA)
Posted 搬砖小工053
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Latent Semantic Analysis(LSA)相关的知识,希望对你有一定的参考价值。
背景:什么是LSA?
Latent Semantic Analysis(LSA)中文翻译为潜语义分析,也被叫做Latent Semantic Indexing ( LSI )。意思是指通过分析一堆(不止一个)文档去发现这些文档中潜在的意思和概念,什么叫潜在的意思?我第一次看到这个解释,直接懵逼。其实就是发现文档的中心主题吧?假设每个词仅表示一个概念,并且每个概念仅仅被一个词所描述,LSA将非常简单(从词到概念存在一个简单的映射关系)。
根据常识我们知道两个很常见的语言现象:1. 存在不同的词表示同一个意思(同义词,吃饭 & 就餐);2. 一个词表示多个意思(一词多义, 苹果【水果】 & 苹果 【公司】)。这种二义性(多义性)都会混淆概念以至于有时就算是人也很难理解。
LSA工作原理
潜语义分析(Latent Semantic Analysis)来源于信息检索(IR)中的一个问题:如何从搜索query中找到相关的文档。有的人说可以用关键词匹配文档,匹配上的就放在搜索结果前面。这明显是有问题滴,一是背景里我们讲过一词多义和同义词问题,二则10亿+的文档采用关键词匹配,实在不现实。
其实呀,在搜索中我们实际想要去比较的不是词,而是隐藏在词之后的意义和概念,用人话说:query搜索的结果文档隐含的概念要和query的概念尽可能的相近。LSA分析试图去解决这个问题,它把词和文档都映射到一个”概念”空间并在这个空间内进行比较(注:也就是一种降维技术)。
当文档的作者写作的时候,对于词语有着非常宽泛的选择。不同的作者对于词语的选择有着不同的偏好,这样会导致概念的混淆。这种对于词语的随机选择在 词-概念 的关系中引入了噪音。LSA滤除了这样的一些噪音,并且还能够从全部的文档中找到最小的概念集合(为什么是最小?)。
为了让这个难题更好解决,LSA引入一些重要的简化:
- 文档被用BOW( bags of words : 词袋 )表示,因此词在文档中出现的位置并不重要,只有一个词的出现次数。
- 概念被表示成经常出现在一起的一些词的某种模式。有点想KNN的思想,文档中概念A相关的词出现次数最多,就把这个文档映射到概念A。例如:4k屏幕、8核CPU 、4G RAM ……经常出现在手机广告文档中。
- 词被认为只有一个意思。但是这可以使得问题变得更加容易。(这个简化会有怎样的缺陷呢?)
LSA能彻底解决文档映射到概念这个问题吗?
NO! NO !NO! LSA只能很好的应对,并不能解决。一方面是因为文档长度,语法结构,用词规范,各种问题的限制 ,一句话,NLP 太复杂了;另一方面是LSA本身的问题。
LSA实现步骤
文档预处理
对文档分词,词根还原(en),去停用词,保留索引词(index word),删除特殊符号等。
索引词可以是满足下面条件的词:
- 不是那种特别常见的词,例如 “and”, ”the” 这种停用词(stop word)。这种词没有包含进来是因为他们本身不存在什么意义。
- 在2个或者2个以上文档里出现。
例子:在amazon.com上搜索”investing”(投资) 并且取top 10搜索结果的书名。下面就是那9个标题,索引词(在2个或2个以上标题出现过的非停用词)被下划线标注:
- The Neatest Little Guide to Stock Market Investing
- Investing For Dummies, 4th Edition
- The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns
- The Little Book of Value Investing
- Value Investing: From Graham to Buffett and Beyond
- Rich Dad’s Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!
- Investing in Real Estate, 5th Edition
- Stock Investing For Dummies
- Rich Dad’s Advisors: The ABC’s of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss
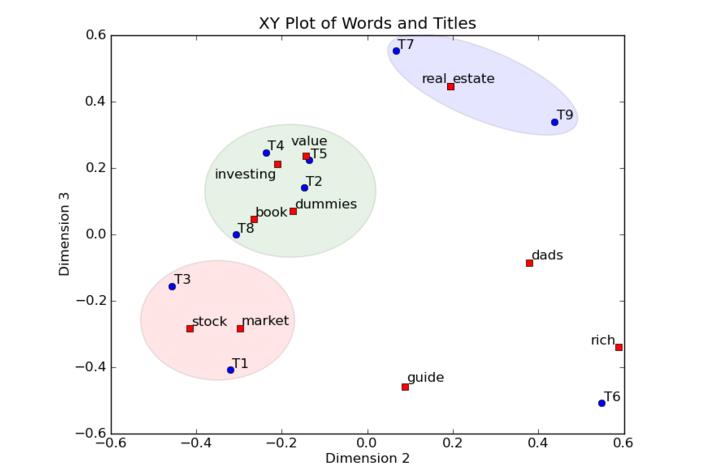
在这个例子里面应用了LSA,在XY轴的图中画出词和标题的位置(只有2维),并且识别出标题的聚类。蓝色圆圈表示9个标题,红色方块表示11个索引词。我们不但能够画出标题的聚类,并且由于索引词可以被画在标题一起,我们还可以给这些聚类打标签。例如,蓝色的聚类,包含了T7和T9,是关于real estate(房地产)的,绿色的聚类,包含了标题T2,T4,T5和T8,是讲value investing(价值投资)的,最后是红色的聚类,包含了标题T1和T3,是讲stock market(股票市场)的。标题T6是孤立点(outlier)。
创建词到文档的矩阵
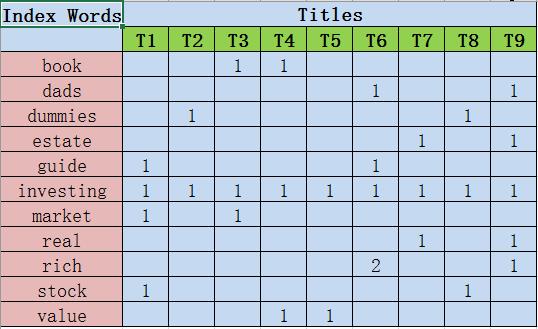
在这个矩阵里,每一个索引词占据了一行,每一个文档占据一列。每一个单元(cell)包含了这个词出现在那个文档中的次数。例如,词”book”出现在T3中一次,出现在T4中一次,而” investing”在所有标题中都出现了一次。一般来说,在LSA中的矩阵会非常大而且会非常稀疏(大部分的单元都是0)。这是因为每个标题或者文档一般只包含所有词汇的一小部分。更复杂的LSA算法会利用这种稀疏性去改善空间和时间复杂度。
代码实现
在这篇文章中,我们用python代码去实现LSA的所有步骤。我们将介绍所有的代码。Python代码可以在这里被下到(见上)。需要安装NumPy 和 SciPy这两个库。
NumPy是python的数值计算类,用到了zeros(初始化矩阵),scipy.linalg这个线性代数的库中,我们引入了svd函数也就是做奇异值分解 , LSA的核心。string是python自带的库,我们用到string.punctuation,包含文档中的特殊符号。
In [1]: import string
In [2]: print string.punctuation
!"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~导入Python 包
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 17 15:42:40 2016
@author: zang
"""
from numpy import zeros
from scipy.linalg import svd
import string定义LSA类
class LSA(object):
def __init__(self, stopwords, ignorechars):
self.stopwords = stopwords
self.ignorechars = ignorechars
self.wdict = {}
self.dcount = 0定义一个LSA类,wdict字典用来记录词的个数,dcount用来记录文档号。
解析文档
def parseDoc(self, doc):
words = doc.split()
for w in words:
w = w.lower().translate(None, self.ingorechars).strip() # 去除特殊字符
if w == "":
continue
elif w in self.stopwords:
continue
elif w in self.wdict:
self.wdict[w].append(self.dcount)
else:
self.wdict[w] = [self.dcount]
self.dcount += 1在LSA类里添加这个函数。这个函数就是把文档分词,并滤除停用词和标点,剩下的词会把其出现的文档号填入到wdict中去,例如,词book出现在标题3和4中,则我们有self.wdict[‘book’] = [3, 4]。相当于建了一下倒排。
建立索引词文档矩阵
def buildMwd(self):
self.keys = [k for k in self.wdict.keys() if len(self.wdict[k]) > 1]
self.keys.sort()
self.Mwd = zeros([len(self.keys), self.dcount])
for i, k in enumerate(self.keys):
for d in self.wdict[k]:
self.Mwd[i,d] += 1所有的文档被解析之后,所有出现的词(也就是词典的keys)被取出并且排序。建立一个矩阵,其行数是词的个数,列数是文档个数。最后,所有的词和文档对所对应的矩阵单元的值被统计出来。
打印索引词文档矩阵
def printMwd(self):
print self.Mwd打印出索引词文档矩阵。
测试LSA类
if __name__ == "__main__":
docs =\\
["The Neatest Little Guide to Stock Market Investing",
"Investing For Dummies, 4th Edition",
"The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns",
"The Little Book of Value Investing",
"Value Investing: From Graham to Buffett and Beyond",
"Rich Dad's Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!",
"Investing in Real Estate, 5th Edition",
"Stock Investing For Dummies",
"Rich Dad's Advisors: The ABC's of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss"]
stopwords = ['and','edition','for','in','little','of','the','to']
ignorechars = string.punctuation
lsaDemo = LSA(stopwords,ignorechars)
for d in docs:
lsaDemo.parseDoc(d)
lsaDemo.buildMwd()
lsaDemo.printMwd()在刚才的测试数据中验证程序逻辑,并查看最终生成的矩阵:
In [33] : runfile('G:/Python/nlp/LSA.py', wdir='G:/Python/nlp')
[[ 0. 0. 1. 1. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 1. 0. 0. 1.]
[ 0. 1. 0. 0. 0. 0. 0. 1. 0.]
[ 0. 0. 0. 0. 0. 0. 1. 0. 1.]
[ 1. 0. 0. 0. 0. 1. 0. 0. 0.]
[ 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[ 1. 0. 1. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 1. 0. 1.]
[ 0. 0. 0. 0. 0. 2. 0. 0. 1.]
[ 1. 0. 1. 0. 0. 0. 0. 1. 0.]
[ 0. 0. 0. 1. 1. 0. 0. 0. 0.]]用TF-IDF替代简单计数
在复杂的LSA系统中,为了重要的词占据更重的权重,原始矩阵中的计数往往会被修改。例如,一个词仅在5%的文档中应该比那些出现在90%文档中的词占据更重的权重。最常用的权重计算方法就是TF-IDF(词频-逆文档频率)。基于这种方法,我们把每个单元的数值进行修改:
TF-IDF定义如下:
以上是关于Latent Semantic Analysis(LSA)的主要内容,如果未能解决你的问题,请参考以下文章