爬虫基础 2.2 网页基础
Posted binyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基础 2.2 网页基础相关的知识,希望对你有一定的参考价值。
2.2 网页基础
????浏览器浏览的网页,均是浏览器根据超文本,CSS,以及,JS,的解解析规则,对服务器返回的数据进行解析加载,进而变成我们所见的页面。
?
2.21 网页的组成
????1 html 构成网页的框架 定义网页的内容
????2 CSS 构成框架中的元素的样式 规定网页的布局
????3 javascript 对网页行为进行编程 动画,酷炫的效果等
?
????1 HTML
????网页 括文字、按钮、图片 视频等各 复杂的元素,其基本就是 HTML 。
不同类型的文字通过不同类型的标签来表示 ,
标签之间的布局又常通过布局标签 div 嵌套组合而戚 ,
各种标签通过不同的排列和嵌套形成网页的框架
?
常见标签:详细内容见https://www.jianshu.com/p/04e541183329 (转载总结很棒)
分区标签
<header> 表示一组引导性的帮助
<nav> 导航
<section> 表示文档中的一个区域(或节),通过是否含一个标题作为子节点来辨识<section>
<aside> 表示与其余页面无关的内容部分
<footer> 表示最近一个章节内容或者根节点元素的页脚
<h1>~<h6> 标题
<article> 表示文档、页面、应用或网站中的独立结构
<address> 地址信息
<hgroup> 代表一个段的标题
?
文本内容标签:
<main> 文档<body>或应用的主体部分
<div> 文档分区元素, 通用型流内容容器
<p> 段落
<pre> 预定义格式文本
<ol> 有序列表
<ul> 无序列表
<li> 列表条目元素
<dl> 描述列表元素
<dt>术语定义元素
<dd> 描述元素,描述列表 (<dl>) 的子元素,<dd>与 <dt> 一起用。
<figure> 代表一段独立的内容, 经常与说明(caption) <figcaption> 配合使用
<figcaption>图片说明/标题,于描述其父节点 <figure> 元素里的其他数据
<blockquote> HTML 块级引用元素
<hr> 表示段落级元素之间的主题转换,视觉上看是水平线
?
HTML 支持各种多媒体资源,例如图像,音频和视频。
<img> 图片
<audio> 音频内容
<video> 视频内容
<track> 被当作媒体元素—<audio> 和 <video>的子元素来使用。它允许指定计时字幕(或者基于事件的数据),例如自动处理字幕。
<map> 与 <area> 属性一起使用来定义一个图像映射(一个可点击的链接区域).
<area> 在图片上定义一个热点区域,可以关联一个超链接。<area>元素仅在<map>元素内部使用。
?
2 CSS
HTML 标签原本被设计为用于定义文档内容。通过使用 <h1>、<p>、<table> 这样的标签,HTML 的初衷是表达"这是标题"、"这是段落"、"这是表格"之类的信息。同时文档布局由浏览器来完成,而不使用任何的格式化标签,这样的文档内容单调,不够美观。
????于是,就有了CSS来美化,为HTML中的元素设定显示效果。
CSS 指层叠样式表 (Cascading Style Sheets)
样式定义如何显示 HTML 元素
样式通常存储在样式表中
把样式添加到 HTML 4.0 中,是为了解决内容与表现分离的问题
外部样式表可以极大提高工作效率
外部样式表通常存储在 CSS 文件中
多个样式定义可层叠为一
?
3 JavaScript
????????简称JS,脚本语言,HTML和CSS配合只能显示静态的彩色的网页,没有动态效果。网页中的动态交互效果例如
????????进度条,弹窗,轮播,,,都是由JS提供。
????????JS以单独的文件加载,后缀为.js, 在HTML标签中通过<script>标签引入
?
因此 网页组成中:
????HTML 定义网页文档的基本结构
????CSS 描述网页的布局
????JS 描述网页的动态行为
?
????
?
2.22 网页的结构
????网页的结构由HTML标签决定, 因此要熟悉各种标签的含义以及代表的内容和功能。
?
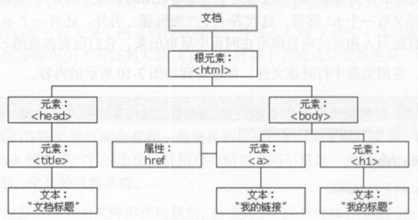
2.23 网页HTML节点以及节点书树的关系
????节点:
????HTML 文档中的所有内容都是节点,通过 HTML DOM ,所有的节点构成节点树,树中的所有节点均可通过 Java Script 访问,所有 HTML 节点元素均可被修改,也可以被创建或删除
????
整个文档是一个文档节点
每个 HTML 元素是元素节点
HTML 元素内的文本是文本节点
每个 HTML 属性是属性节点
注释是注释节点
?
节点树:
????HTML DOM HTML 文档视作树结构,这种结构被称为节点树,除了root 根节点每个节点都有父节点,也可能由子节点兄弟节点。
?
?
?
?
?
?
?
?
?
2.24 CSS 选择器
????网页由多个节点构成,CSS选择器会根据不同的节点设置为不同的样式,如何定位节点,选择要提取的内容? 通过CSS选择器来选择节点
????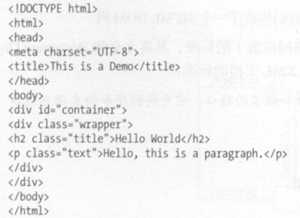
????使用 css 选择器来定位节点
?
例如div 节点的 id 为container ,那么就可以表示为#container ,其中#开头代表选择id 其后紧跟 id 的名称
?
想选择 class wrapper 的节点 ,便可以使用 .wrapper ,这里以点 . 开头代表选择 class ,其后紧跟 class 的名称
?
根据标签名筛选,例如想选择二级标题 ,直接用 h2 即可 这是最常用的 种表示,分别是根据id, class 、标签名筛选 ,
?
css 选择器还支持嵌套选择 ,各个选择器之间加上空格分隔开便可以代表嵌套关系,
#container .wrapper 则代表先选择 id为container 的节点,然后选中其内部的 class wrapper 的节点,然后再进一步选中其内部的p节点
?
如果不加空格,代表并列关系
如 div#container . wrapper p.text 代表先选择 id为container div 节点,然后选中其内部的 class wrapper 的节点,再进步选中其内部的 class text 节点 这就是CSS择器,其筛选非常强大
?
?
?
?
?
?
?
Css选择器语法规则:
选择器 | 例子 | 例子描述 | CSS | |
.intro | 选择 class="intro" 的所有元素。 | 1 | ||
#firstname | 选择 id="firstname" 的所有元素。 | 1 | ||
* | 选择所有元素。 | 2 | ||
p | 选择所有 <p> 元素。 | 1 | ||
div,p | 选择所有 <div> 元素和所有 <p> 元素。 | 1 | ||
div p | 选择 <div> 元素内部的所有 <p> 元素。 | 1 | ||
div>p | 选择父元素为 <div> 元素的所有 <p> 元素。 | 2 | ||
div+p | 选择紧接在 <div> 元素之后的所有 <p> 元素。 | 2 | ||
[target] | 选择带有 target 属性所有元素。 | 2 | ||
[target=_blank] | 选择 target="_blank" 的所有元素。 | 2 | ||
[title~=flower] | 选择 title 属性包含单词 "flower" 的所有元素。 | 2 | ||
[lang|=en] | 选择 lang 属性值以 "en" 开头的所有元素。 | 2 | ||
a:link | 选择所有未被访问的链接。 | 1 | ||
a:visited | 选择所有已被访问的链接。 | 1 | ||
a:active | 选择活动链接。 | 1 | ||
a:hover | 选择鼠标指针位于其上的链接。 | 1 | ||
input:focus | 选择获得焦点的 input 元素。 | 2 | ||
p:first-letter | 选择每个 <p> 元素的首字母。 | 1 | ||
p:first-line | 选择每个 <p> 元素的首行。 | 1 | ||
p:first-child | 选择属于父元素的第一个子元素的每个 <p> 元素。 | 2 | ||
p:before | 在每个 <p> 元素的内容之前插入内容。 | 2 | ||
p:after | 在每个 <p> 元素的内容之后插入内容。 | 2 | ||
p:lang(it) | 选择带有以 "it" 开头的 lang 属性值的每个 <p> 元素。 | 2 | ||
p~ul | 选择前面有 <p> 元素的每个 <ul> 元素。 | 3 | ||
a[src^="https"] | 选择其 src 属性值以 "https" 开头的每个 <a> 元素。 | 3 | ||
a[src$=".pdf"] | 选择其 src 属性以 ".pdf" 结尾的所有 <a> 元素。 | 3 | ||
a[src*="abc"] | 选择其 src 属性中包含 "abc" 子串的每个 <a> 元素。 | 3 | ||
p:first-of-type | 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 | 3 | ||
p:last-of-type | 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 | 3 | ||
p:only-of-type | 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 | 3 | ||
p:only-child | 选择属于其父元素的唯一子元素的每个 <p> 元素。 | 3 | ||
p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 <p> 元素。 | 3 | ||
p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 | 3 | ||
p:nth-of-type(2) | 选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 | 3 | ||
p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 | 3 | ||
p:last-child | 选择属于其父元素最后一个子元素每个 <p> 元素。 | 3 | ||
:root | 选择文档的根元素。 | 3 | ||
p:empty | 选择没有子元素的每个 <p> 元素(包括文本节点)。 | 3 | ||
#news:target | 选择当前活动的 #news 元素。 | 3 | ||
input:enabled | 选择每个启用的 <input> 元素。 | 3 | ||
input:disabled | 选择每个禁用的 <input> 元素 | 3 | ||
input:checked | 选择每个被选中的 <input> 元素。 | 3 | ||
:not(p) | 选择非 <p> 元素的每个元素。 | 3 | ||
::selection | 选择被用户选取的元素部分。 | 3 | ||
?
?
????除了css选择器,还有更高效的xpath选择器可使用。
以上是关于爬虫基础 2.2 网页基础的主要内容,如果未能解决你的问题,请参考以下文章