分布式系统中的定时任务全解
Posted 不去天涯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统中的定时任务全解相关的知识,希望对你有一定的参考价值。
概述
分布式系统中的定时任务全解(一)–java基础实现
分布式系统中的定时任务全解(二)–常见工程实现
分布式系统中的定时任务全解(四)–补充
前两篇从java语言中定时任务的基础实现,到第三方框架依赖下的常用实现方式都已经讲到了。
接下来的这一节会比较长,会从elastic-job使用、使用中会遇到的问题以及elastic-job的几个切面上的原理3个大部分。
集成elastic-job
1.首先引入maven仓库
<!-- 引入elastic-job核心模块 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-core</artifactId>
<version>1.1.0</version>
</dependency>
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-spring</artifactId>
<version>1.1.0</version>
</dependency>2.实现自己定义的作业
@Component
public class MyElasticJob extends AbstractSimpleElasticJob {
@Override
public void process(JobExecutionMultipleShardingContext context) {
// do something by sharding items
}
}3.配置作业
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<context:component-scan base-package="com.dangdang.example.elasticjob" />
<context:property-placeholder location="classpath:conf/*.properties" />
<reg:zookeeper id="regCenter" server-lists="${serverLists}" namespace="${namespace}" base-sleep-time-milliseconds="${baseSleepTimeMilliseconds}" max-sleep-time-milliseconds="${maxSleepTimeMilliseconds}" max-retries="${maxRetries}" nested-port="${nestedPort}" nested-data-dir="${nestedDataDir}" />
<job:simple id="simpleElasticJob" class="com.dangdang.example.elasticjob.spring.job.SimpleJobDemo" registry-center-ref="regCenter" sharding-total-count="${simpleJob.shardingTotalCount}" cron="${simpleJob.cron}" sharding-item-parameters="${simpleJob.shardingItemParameters}" monitor-execution="${simpleJob.monitorExecution}" monitor-port="${simpleJob.monitorPort}" failover="${simpleJob.failover}" description="${simpleJob.description}" disabled="${simpleJob.disabled}" overwrite="${simpleJob.overwrite}" />
<job:dataflow id="throughputDataFlowJob" class="com.dangdang.example.elasticjob.spring.job.ThroughputDataFlowJobDemo" registry-center-ref="regCenter" sharding-total-count="${throughputDataFlowJob.shardingTotalCount}" cron="${throughputDataFlowJob.cron}" sharding-item-parameters="${throughputDataFlowJob.shardingItemParameters}" monitor-execution="${throughputDataFlowJob.monitorExecution}" failover="${throughputDataFlowJob.failover}" process-count-interval-seconds="${throughputDataFlowJob.processCountIntervalSeconds}" concurrent-data-process-thread-count="${throughputDataFlowJob.concurrentDataProcessThreadCount}" description="${throughputDataFlowJob.description}" disabled="${throughputDataFlowJob.disabled}" overwrite="${throughputDataFlowJob.overwrite}" streaming-process="${throughputDataFlowJob.streamingProcess}" />
<job:dataflow id="sequenceDataFlowJob" class="com.dangdang.example.elasticjob.spring.job.SequenceDataFlowJobDemo" registry-center-ref="regCenter" sharding-total-count="${sequenceDataFlowJob.shardingTotalCount}" cron="${sequenceDataFlowJob.cron}" sharding-item-parameters="${sequenceDataFlowJob.shardingItemParameters}" monitor-execution="${sequenceDataFlowJob.monitorExecution}" failover="${sequenceDataFlowJob.failover}" process-count-interval-seconds="${sequenceDataFlowJob.processCountIntervalSeconds}" max-time-diff-seconds="${sequenceDataFlowJob.maxTimeDiffSeconds}" description="${sequenceDataFlowJob.description}" disabled="${sequenceDataFlowJob.disabled}" overwrite="${sequenceDataFlowJob.overwrite}" />
</beans>属性文件定义:
#job.properties
simpleJob.cron=0/5 * * * * ?
simpleJob.shardingTotalCount=10
simpleJob.shardingItemParameters=0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=J
simpleJob.monitorExecution=false
simpleJob.failover=true
simpleJob.description=\\u53EA\\u8FD0\\u884C\\u4E00\\u6B21\\u7684\\u4F5C\\u4E1A\\u793A\\u4F8B
simpleJob.disabled=false
simpleJob.overwrite=true
simpleJob.monitorPort=9888
throughputDataFlowJob.cron=0/5 * * * * ?
throughputDataFlowJob.shardingTotalCount=10
throughputDataFlowJob.shardingItemParameters=0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=J
throughputDataFlowJob.monitorExecution=true
throughputDataFlowJob.failover=true
throughputDataFlowJob.processCountIntervalSeconds=10
throughputDataFlowJob.concurrentDataProcessThreadCount=3
throughputDataFlowJob.description=\\u4E0D\\u505C\\u6B62\\u8FD0\\u884C\\u7684\\u4F5C\\u4E1A\\u793A\\u4F8B
throughputDataFlowJob.disabled=false
throughputDataFlowJob.overwrite=true
throughputDataFlowJob.streamingProcess=true
sequenceDataFlowJob.cron=0/5 * * * * ?
sequenceDataFlowJob.shardingTotalCount=10
sequenceDataFlowJob.shardingItemParameters=0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=J
sequenceDataFlowJob.maxTimeDiffSeconds=-1
sequenceDataFlowJob.monitorExecution=true
sequenceDataFlowJob.failover=true
sequenceDataFlowJob.processCountIntervalSeconds=10
sequenceDataFlowJob.description=\\u6309\\u987A\\u5E8F\\u4E0D\\u505C\\u6B62\\u8FD0\\u884C\\u7684\\u4F5C\\u4E1A\\u793A\\u4F8B
sequenceDataFlowJob.disabled=false
sequenceDataFlowJob.overwrite=true#reg.properties
serverLists=localhost:4181
namespace=elasticjob-example
baseSleepTimeMilliseconds=1000
maxSleepTimeMilliseconds=3000
maxRetries=3
nestedPort=4181
nestedDataDir=target/test_zk_data/集成中遇到的问题
1.cron表达式总是和第一次运行时配置的一样,不变
因为,不论是elastic-job的github给出的示例,还是网上给的示例,配置项都是没有添加overwrite选项的,这个选项默认是false,也就是任务的配置信息,如果已经设置过,那么就会一直不变,就算后续你修改了自己的配置文件中的cron。
解决方法就是在你的job配置中加上overwrite选项:
<job:simple id="yourTaskId" class="yourTaskClass" registry-center-ref="regCenter" cron="0 0/30 * * * ?" sharding-total-count="1" sharding-item-parameters="0=A" overwrite="true"/>2.我在网上找到的例子,给的serverLists=” yourhost:2181”,为什么编译器告诉我serverLists配置项不被支持
网上很多示例都是针对1.1.0版本之前的示例,1.1.0版本elastic-job进行了很大的改动,包括一些属性。
解决方法就是,使用1.1.0版本以后的elastic-job,按照github官网给出的示例去做(https://github.com/dangdangdotcom/elastic-job)
3.我的job里面的autowired或者resource变量没有注入
解决方法,首先看你的变量是不是静态的,如果是静态的请换成非静态的,这时spring的问题。接下来看下你的job有没有添加@component注解。
4.我是springmvc的web工程,并且已经在其他xml文件有placeholder了,但是reg:zookeeper初始化时显示的连接仍然是“${xxx}”的样式
原理作者也有弄清楚(后续可以研究一下配置文件的加载过程)。如果elastic-job是在单独的xml中配置,那么需要在这个xml中添加placeholder,但是,你一定知道spring默认仅加载一个placeholder,那么只需要在placeholder属性中添加ignore-unresolvable=”true”即可。
5.如果我需要在job中重新设定下次触发的时间怎么办
在你的job中结束位置,添加如下代码:
JobRegistry.getInstance().getJobScheduleController(jobname).rescheduleJob(cron);如果,你打印了日志,那么应该会发现,上面的语句调用后,job会被立即触发,看起来像是同时执行了两次。这是触发时间点计算的缘故,cron表达式是以s为单位的,计算机的执行是以毫秒为单位的,很可能当前的时间点仍然是你给定新cron表达式相符合的时间点。
给了具体的例子:
原有cron=”0/10 * * * * * ? ”
触发时间点是:9点18分10s
函数执行时间是:100ms
执行的最后调用:reschedule
新的cron=”0/5 * * * * * ?”
那么此时仍然符合新cron的触发时间点,所以reschedule会立即触发
这是无法避免的,请保证你的job的幂等性。
elastic-job不同侧面解析
这里首先给出elastic-job主要设计师之一张亮的一篇博文地址,这里给出了很多elastic-job的机理层面的解析。(http://my.oschina.net/u/719192/blog/506062)
实现思想对比
1.先说下map/reduce的思想,这个看起来和定时任务没有关系,列在这里也正是因为两者之间算是完全不同的两种思想。
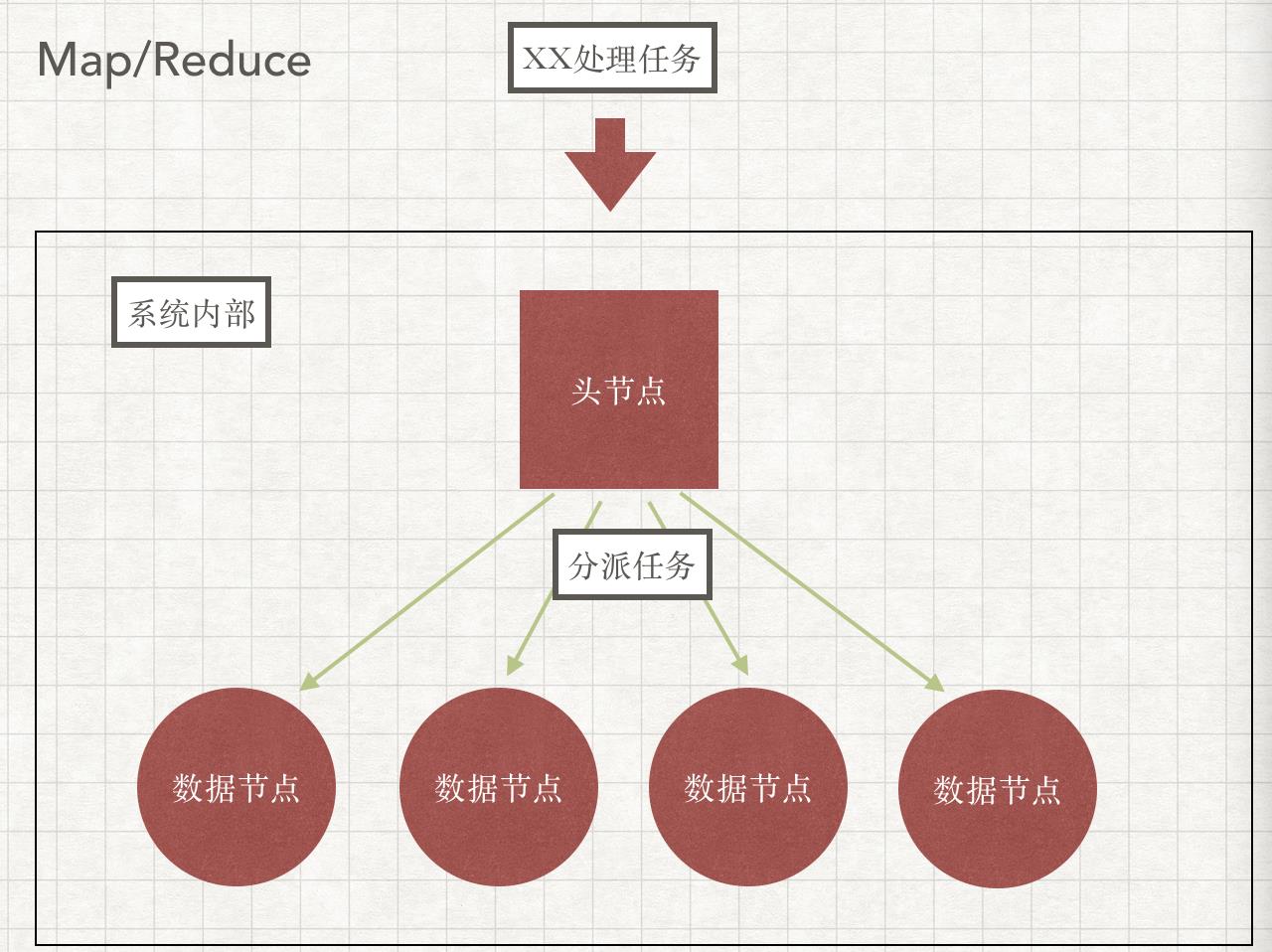
这里要特别指出的是,所有的计算节点,都是被动的接受任务,头结点给你什么任务,你就执行什么任务。
2.分布式定时任务(quartz/elastic-job)
接下来看一下定时任务的集群方案,是完全的一个翻转:
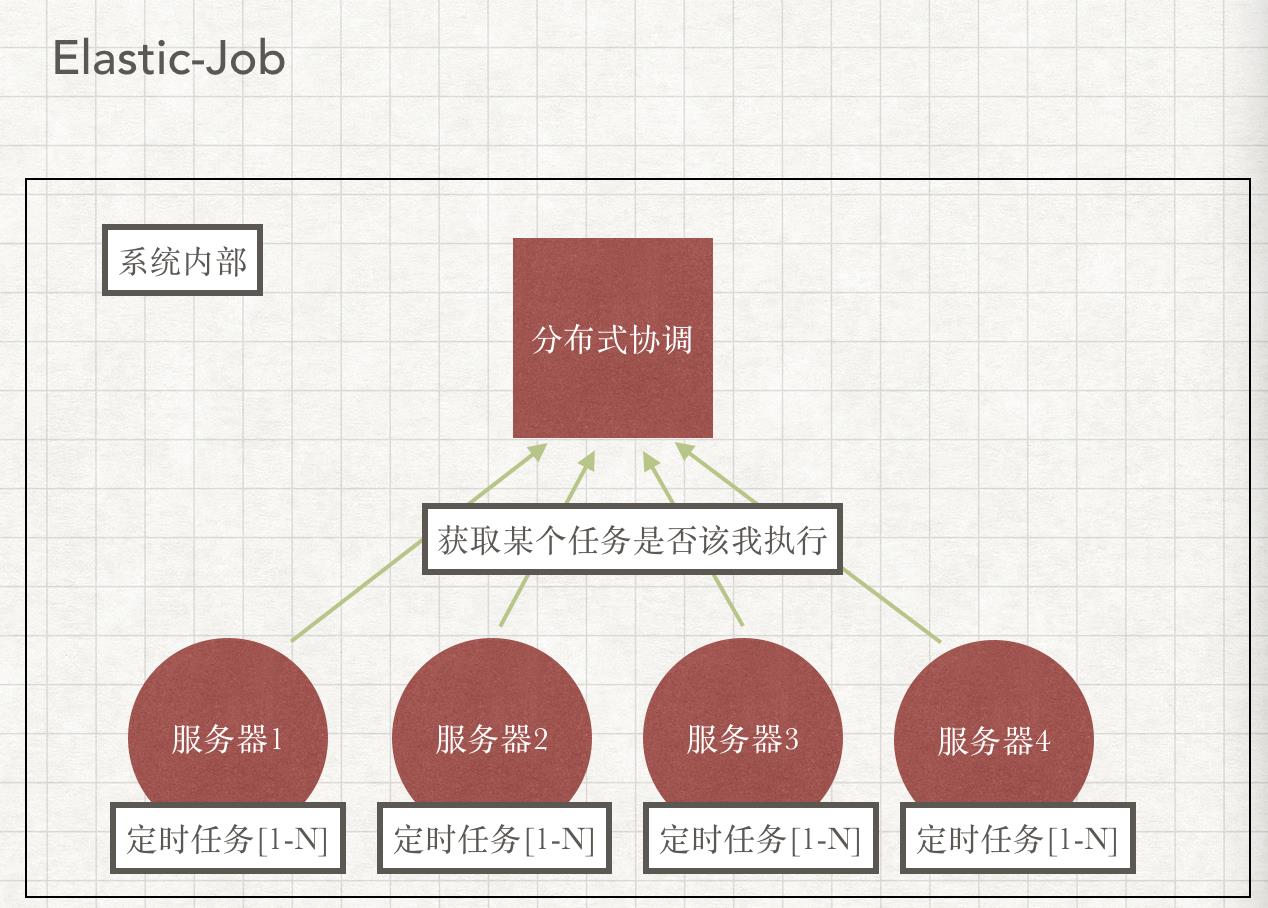
所有的任务执行节点上的调度器都在运行,他们执行不执行某个任务,是根据从协调中心获取到的数据判断的。quartz是看数据库记录,elastic-job是看zookeeper中的sharding信息。
3.另外一种思路?
可能你会想,为什么定时任务不能是单独的一个集群,然后可以通过管理端随时上传定时任务的jar上去,然后又头结点调度呢?这样的话不是所有的定时任务都能集中、统一管理起来了么?那该多好,和部署的服务器独立。我只能说,市面上是有这种类型的服务的,比如阿里提供的E-MapReduce服务,前端支持手动触发和定时触发作业,后端的作业处理使用的是Hadoop。
最后,说明一下,既然知道了分布式定时任务的思想,那么也就很容易理解他的部署方式了:
也就是直接和你的web服务在一起,每个服务器实例都是一个计算节点,连接到协调中心(数据库/zookeeper),定时任务触发时从协调中心查询自己是应当执行job任务,还是直接返回,跳过job的执行。
接下来着重从源代码层面的不同侧面做一些对elastic-job的粗范的解析,以利于使用elastic-job时遇到问题的快速解决。(2016年10月19日补充:以下分析均针对ej的1.1.0版本,1.1.1之后,已经拆分成了ej-lite和ej-cloud,其中ej-cloud就是博主提到的第三种思想)
任务的初始化过程
初始化的入口在:
new JobScheduler(regCenter, simpleJobConfig, new SimpleDistributeOnceElasticJobListener()).init();
接下来看下init方法到底做了什么事情:

其中最主要的两个步骤是:
1.registerStartUpInfo,这一步,这里面添加了对zookeeper的监听(后续会讲到监听和监听后做了什么),和zookeeper上相关节点的创建。
其中persistJobConfiguration方法中用到了前面问题中说到的overwrite,如果overwrite为false,那么shechule的触发cron表达式是直接从zookeeper中获取的,而不是本地xml配置的。
其中的setReshrdingFlag用来创建一个标记,所有服务器上的同名schedule运行的job都会检查是否存在这个标记(在后续的任务执行中会说到),如果存在,那么执行任务重新分片(后续会说到什么是分片,分片用来干什么,这是elastic-job优于quartz集群的大亮点之一)。
2.sheduleJob
这就是创建quartz的schedule,启动定时任务了。
任务执行
elastic-job任务分片,多种类型任务的封装都在这里,先看下elastic-job和做为elastic-job基础的quartz之间的关系:
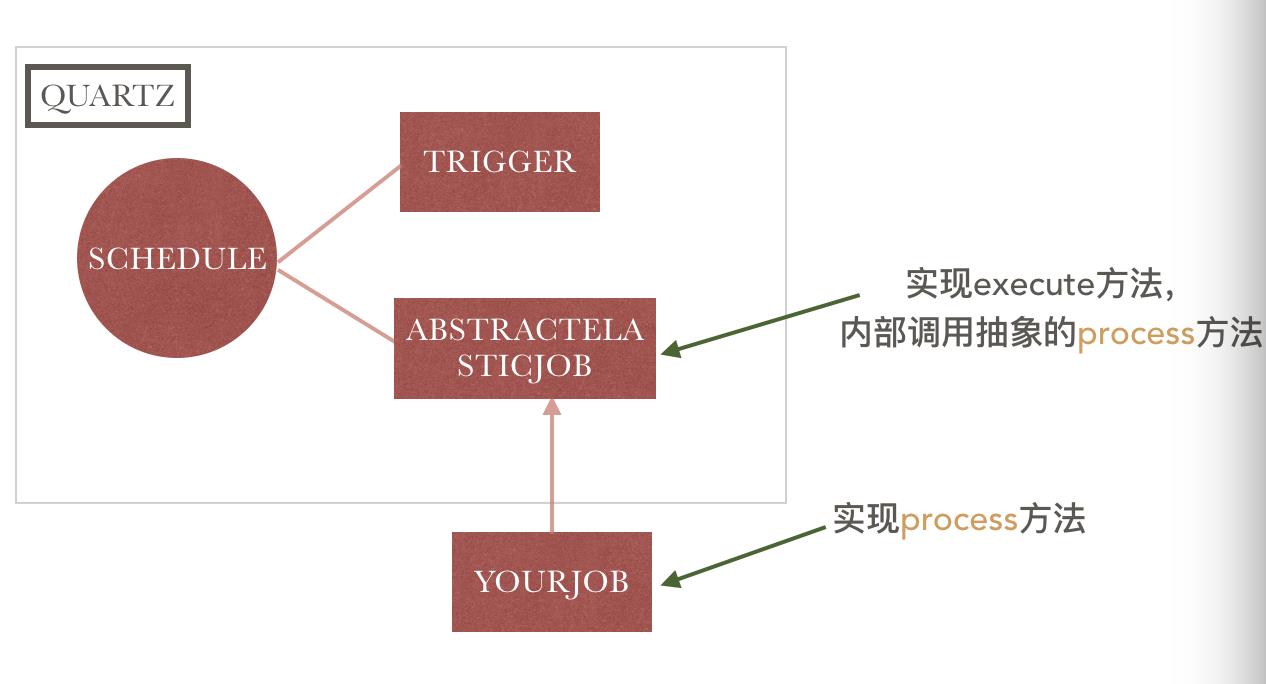
看上图,应该能够很清楚,elastic-job所有的关键都在abstractElasticJob.execute方法中,接下来一块看一下:
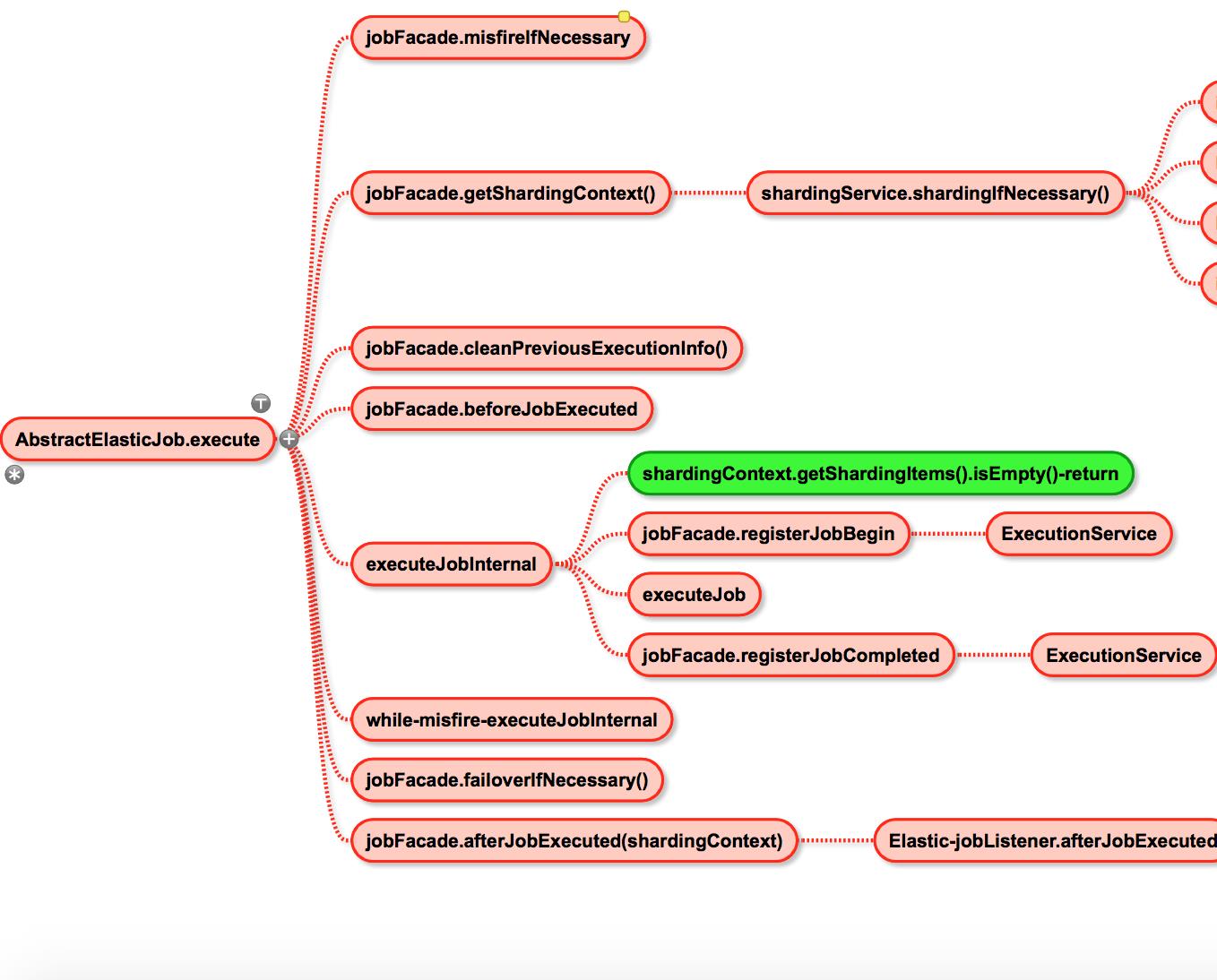
看到里面的shardingIfNecessary和getShardingItems.isEmpty-return了么?
这就是分片和控制任务仅被应当执行的服务器实例执行的关键了。
分片
看了上边那么多,估计很可能你还是对分片是什么,怎么用,什么时候会触发分片存在很多很多的疑问,接下来一个一个的看。
说到分片这可以说是elastic-job在quartz集群调度上的一个创新。在quartz集群环境下,仅有一个服务器实例可以运行某一个特定的schedule。但是在elastic-job下,你可以指定有几个服务器实例执行这一个任务,可以是1个,2个,3个都可以。
那么几个服务器实例运行同一个任务不是冲突了么,至少是浪费了么?NONONO…..
举个例子,在一个更广的环境下,比如你有一个定时计算用户积分的任务,你的用户表是分在10个数据库里的。那么你可以用一个服务器实例去运行,也可以用5个服务器实例去运行,因为你有5台服务器可用,每个服务器实例分给2个数据库的计算任务。
这种场景用quartz是做不到的,用elastic-job,你只需要指定总分片10,那么每一个分片指定一个标记量,那么每台服务器会得到2个任务去执行。
当然如果你有5台服务器可用来计算,但是数据库仅有2个,那么你只能分两个片,那么这5台中有两台得到运行的权利,其他的服务器将在job.execute中看到自己的getShardingItems.isEmpty然后直接return。
分片在什么场景下会触发呢?
以下场景都会触发重新分片,以下场景是在zookeeper中添加了一个reshard的标记量,任务下次执行的时候就会触发分片。
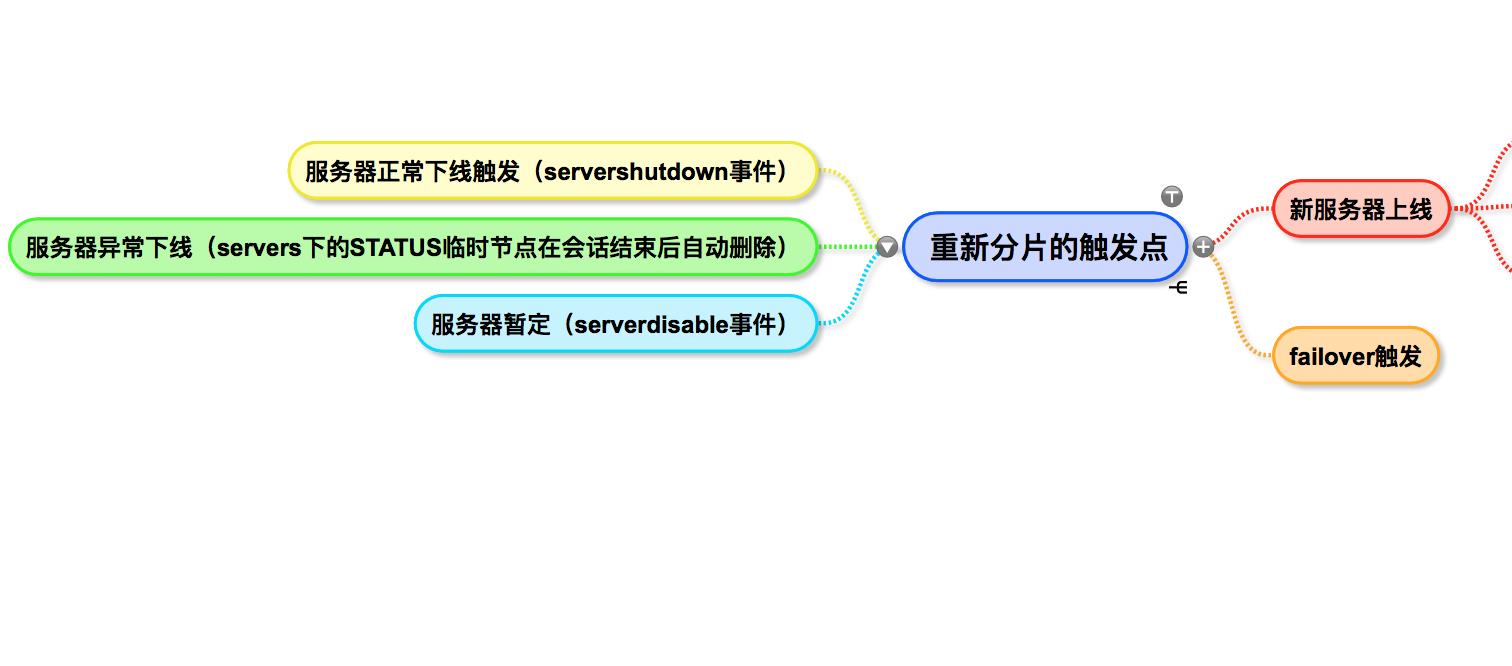
监听器的作用
前边说过了,在初始化的时候elastic-job会注册一系列的zookeeper监听器,监听节点的变化,那么他具体监听了哪些地方呢?
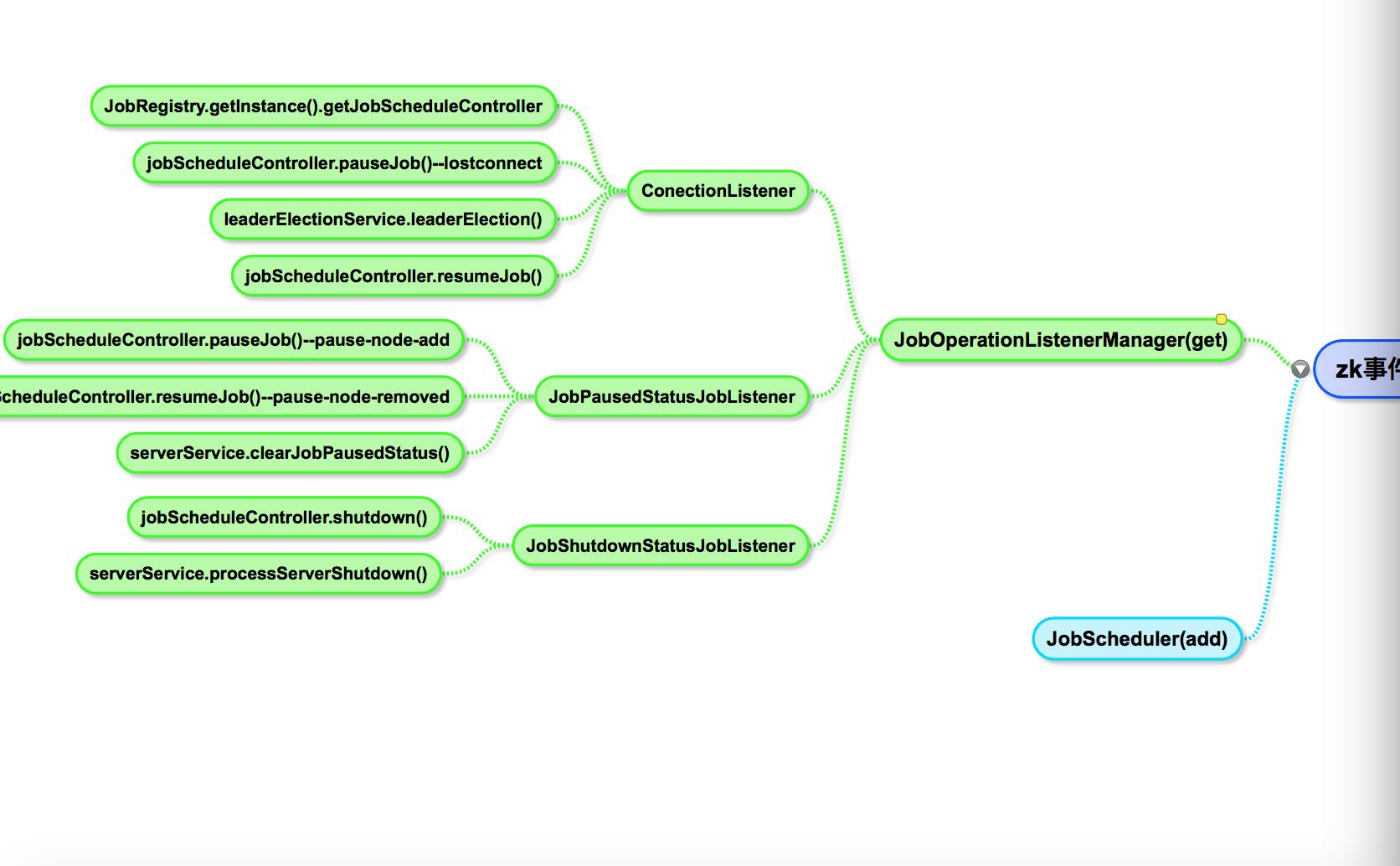
汇总起来是两个方面:一个是响应console对定时任务的控制,一个是响应服务器的崩溃。当执行的节点崩溃时,会触发重新分片,由其他服务器接起定时任务的执行。
以上是关于分布式系统中的定时任务全解的主要内容,如果未能解决你的问题,请参考以下文章