大数据学习之Storm实时统计网站访问量案例35
Posted hidamowang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习之Storm实时统计网站访问量案例35相关的知识,希望对你有一定的参考价值。
案例一:统计网站访问量(实时统计)
实时流式计算框架:storm
1)spout
数据源,接入数据源
本地文件如下
编写spout程序:
package pvcount;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
/**
* @author Dawn
* @date 2019年6月7日10:19:39
* @version 1.0
* 编写spout。接入本地数据源
*/
public class PvCountSpout implements IRichSpout
private SpoutOutputCollector collector;
private BufferedReader br;
private String line;
@Override
public void nextTuple()
//发送读取的数据的每一行
try
while((line=br.readLine()) != null)
//发送数据到splitbolt
collector.emit(new Values(line));
//设置延迟
Thread.sleep(500);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector)
this.collector=collector;
//读取文件
try
br=new BufferedReader(new InputStreamReader(new FileInputStream("f:/temp/storm实时统计访问量/weblog.log")));
catch (FileNotFoundException e)
// TODO Auto-generated catch block
e.printStackTrace();
//别关流!!!!
// finally
// if(br!=null)
// try
// br.close();
// catch (IOException e)
// // TODO Auto-generated catch block
// e.printStackTrace();
//
//
//
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
//声明
declarer.declare(new Fields("logs"));
//处理tuple成功 回调的方法。就像kafka的那个callback回调函数,还有zookeeper中的回调函数 process
@Override
public void ack(Object arg0)
// TODO Auto-generated method stub
//如果spout在失效的模式中 调用此方法来激活,和在Linux中那个命令 storm activate [拓扑名称] 一样的效果
@Override
public void activate()
// TODO Auto-generated method stub
//在spout程序关闭前执行 不能保证一定被执行 kill -9 是不执行 storm kill 是不执行
@Override
public void close()
// TODO Auto-generated method stub
//在spout失效期间,nextTuple不会被调用 和在Linux中那个命令 storm deactivate [拓扑名称] 一样的效果
@Override
public void deactivate()
// TODO Auto-generated method stub
//处理tuple失败回调的方法
@Override
public void fail(Object arg0)
// TODO Auto-generated method stub
//配置
@Override
public Map<String, Object> getComponentConfiguration()
// TODO Auto-generated method stub
return null;
2)splitbolt
业务逻辑处理
切分数据
拿到网址
package pvcount;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* @author Dawn
* @date 2019年6月7日10:30:38
* @version 1.0
* 切分数据,拿到网址
*/
public class PvCountSplitBolt implements IRichBolt
private OutputCollector collector;
private int pvnum = 0;
//业务逻辑 分布式 集群 并发度 线程(接收tuple然后进行处理)
@Override
public void execute(Tuple input)
//1.获取数据
String line = input.getStringByField("logs");
//2.切分数据
String[] fields = line.split("\\t");
String session_id=fields[1];
//3.局部累加
if(session_id != null)
pvnum++;
//输出
collector.emit(new Values(Thread.currentThread().getId(),pvnum));
//初始化调用
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector)
this.collector=collector;
//声明
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
//声明输出
declarer.declare(new Fields("threadid","pvnum"));
//一个bolt即将关闭时调用 不能保证一定被调用 资源清理
@Override
public void cleanup()
// TODO Auto-generated method stub
//配置
@Override
public Map<String, Object> getComponentConfiguration()
// TODO Auto-generated method stub
return null;
3)bolt
累加次数求和
package pvcount;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
/**
* @author Dawn
* @date 2019年6月7日10:39:52
* @version 1.0
* 累加次数求和
*/
public class PvCountSumBolt implements IRichBolt
private OutputCollector collector;
private HashMap<Long, Integer> hashmap=new HashMap<>();
@Override
public void cleanup()
@Override
public void execute(Tuple input)
//1.获取数据
Long threadId = input.getLongByField("threadid");
Integer pvnum = input.getIntegerByField("pvnum");
//2.创建集合 存储 (threadid,pvnum)
hashmap.put(threadId, pvnum);
//3.累加求和(拿到集合中所有value值)
Iterator<Integer> iterator = hashmap.values().iterator();
//4.清空之前的数据
int sum=0;
while(iterator.hasNext())
sum+=iterator.next();
System.err.println(Thread.currentThread().getName() + "总访问量为->" + sum);
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector)
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer)
@Override
public Map<String, Object> getComponentConfiguration()
// TODO Auto-generated method stub
return null;
4)Driver
使用字段分组
package pvcount;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* @author Dawn
* @date 2019年6月7日10:45:53
* @version 1.0 统计网站访问量(实时统计)
*/
public class PvCountDriver
public static void main(String[] args)
// 1.创建拓扑
TopologyBuilder builder = new TopologyBuilder();
// 2.指定设置
builder.setSpout("pvcountspout", new PvCountSpout(), 1);
builder.setBolt("pvsplitbolt", new PvCountSplitBolt(), 6).setNumTasks(4).fieldsGrouping("pvcountspout",
new Fields("logs"));
builder.setBolt("pvcountbolt", new PvCountSumBolt(), 1).fieldsGrouping("pvsplitbolt",
new Fields("threadid", "pvnum"));
// 3.创建配置信息
Config conf = new Config();
conf.setNumWorkers(2);
// 4.提交任务
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("pvcounttopology", conf, builder.createTopology());
运行结果如下:
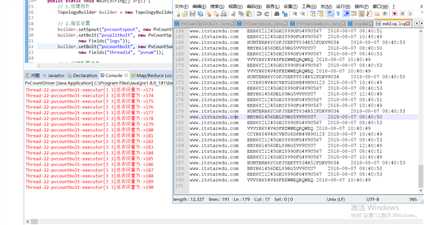
总共190条数据。统计完成之后再进行添加数据。程序会继续统计

以上是关于大数据学习之Storm实时统计网站访问量案例35的主要内容,如果未能解决你的问题,请参考以下文章