爬虫基础知识及requests常用方法总结
Posted chuwanliu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基础知识及requests常用方法总结相关的知识,希望对你有一定的参考价值。
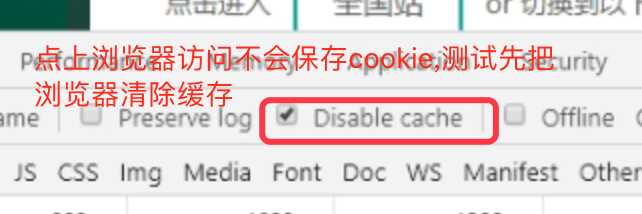
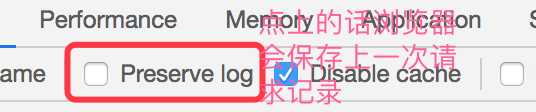
一、浏览器Disable cache 和 Preserve log的作用
.
.
二、复制url乱码情况
from urllib.parse import urlencode.
三、requests请求
res=resquests.get(url)
print(res) #得到的是对象
print(res.text) #文本
print(res.content) #得到的是二进制文件
res.cookies ===>返回一个cookies对象
res.cookies.get_dict()===>获得cookie字典四、浏览器报错
400 中不到资源
500 服务器错误
200 成功五、requests.get/requests.post请求参数
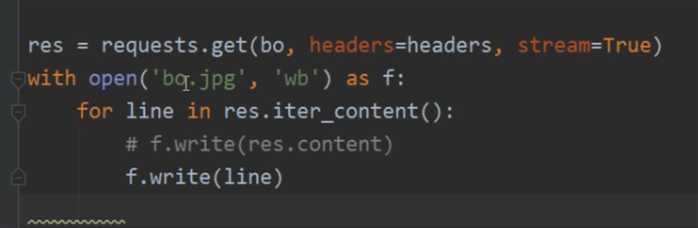
requests.get(url(url请求地址),headers=""(请求头),params,json ,data(不是json类型就需要dumps,form表单数据),cookies(cookies数据),allow_redirects=True(指定是否让请求重定向),cert(存放安全认证的信息)=("/path/server(文件名,可以自己命名).crt","/path/key")) 六、视频通过流的方式一行一行写入
.
七、requests发送请求出现htpps SSL改进方法
方法一、
import requests
response=requests.get("https://www.xiaohuar.com",verify=False)
print(response.text)缺点:还会出现警告
.
改进方法二、
import urllib3
import requsets
urllib3.disable_warnings()
response=requests.get("https://www.xiaohuar.com",verify=False)
print(response.text)八、requests使用代理ip
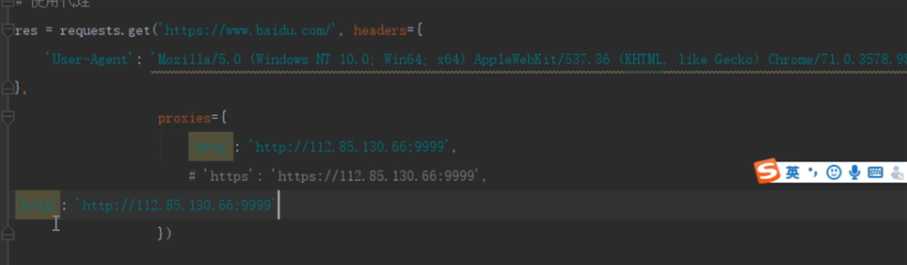
1、requests发送http|https协议(使用代理ip)
.
import requests
res=requests.get(url,proxies="http":"http://ip:port",
"https":"https://ip:port")2、reqursts发送其他的sock的协议
import requests
res=requests.get(url,proxies=
"sock":"sock://ip:port"
)九、requests.auth用法
import reqeusts
import requests.auth import HTTPBaiscAuth
res=resquests.get(url,HTTPBasicAuth("username","password"))十、requests file功能
import requests
files="file":open(path,"rb")
response=requests.post(url,files=files)
print(response.status_code)以上是关于爬虫基础知识及requests常用方法总结的主要内容,如果未能解决你的问题,请参考以下文章
requests库与 lxml 库常用操作整理+总结,爬虫120例阶段整理篇
requests库与 lxml 库常用操作整理+总结,爬虫120例阶段整理篇