奇点云数据中台技术汇| DataSimba系列之计算引擎篇
Posted startdt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了奇点云数据中台技术汇| DataSimba系列之计算引擎篇相关的知识,希望对你有一定的参考价值。

随着移动互联网、云计算、物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代。数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产。如何处理大数据,挖掘大数据的价值,让大数据为企业的发展保驾护航,将是未来信息技术发展道路上关注的重点。
传统的数据处理方式通常是将数据导入至专门的数据分析工具中,这样会面临两个问题:1、如果源数据非常大时,往往数据的移动就要花费较长时间。2、传统的数据处理工具往往是单机模型,面对海量数据时,数据处理的时间也是一个很大的问题。通常我们对数据的实时性要求并没有那么高,但是对数据能不能及时产出却是有强烈要求的。
因此产生了一系列的基于大数据技术的计算引擎,来满足日渐增长的数据量以及复杂的业务场景。下面主要介绍下DataSimba支持的一些计算引擎以及DataSimba是如何选择相应的计算引擎去解决不同的业务场景。
计 算 引 擎
计算引擎最主要的应用场景就是传统的ETL过程,如电信领域的KPI、KQI的计算。单据经过探针采集上来后,按照一定的规则转换成原始单据,根据业务需求,按周期(分钟、小时、天)等粒度计算成业务单据。以前的这一过程通常使用数据库来计算,但是随着数据量越来越多,传统的数据库技术遇到了瓶颈,就出现了分布式的计算引擎技术。
一般来说目前的计算引擎大致分为两大类:基于磁盘的计算技术、基于内存的计算技术。基于磁盘的典型代表是Hive,基于内存的代表为Spark。还有其它的例如Impala、Presto、Druid、Kylin等计算引擎,都是大数据在不同应用场景下解决不同的问题而产生的。
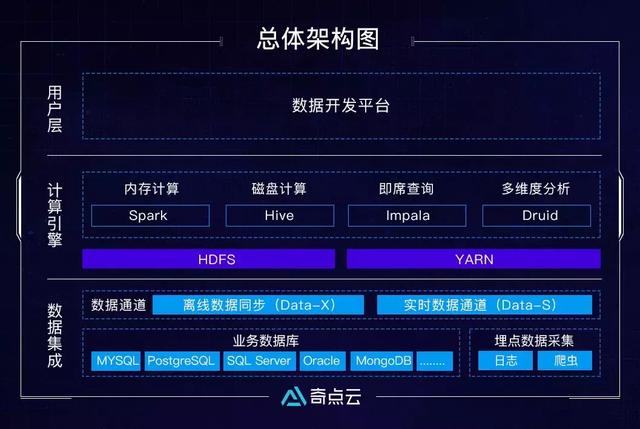
DataSimba数据中台采用了多种计算引擎以适应各种应用场景的需要,并且专门为数据开发定制了数据开发平台,降低开发难度,使数据开发、分析师可以很方便的根据不同的场景使用与之对应的计算引擎。总体架构图如下所示:
磁盘计算
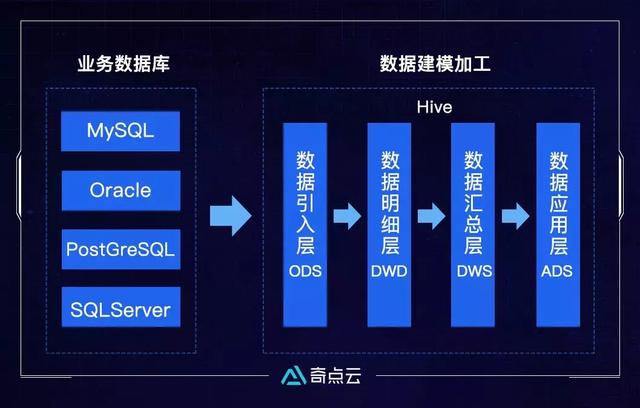
就目前来说,基于磁盘的计算引擎仍然是大数据处理过程中很重要的一种,其主要特点是稳定、分布式、多副本、可处理的数据量非常庞大。基于此,通常大数据的数仓会采取此种计算引擎,而这种计算引擎的典型代表就是Hive。
Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉MapReduce的用户很方便的利用SQL语言查询、汇总、分析数据。而MapReduce开发人员可以把自己写的Mapper 和Reducer 作为插件来支持Hive做更复杂的数据分析。
Hive是构建DataSimba数据中台过程中非常重要的一种计算引擎,它能帮助用户快速的搭建数仓模型、ETL数据清洗、数据开发调式等,目前已经在多个项目中得到了实施验证。
某母婴客户案例
⊙客户背景:该母婴集团运营效率低下,无标准数据体系及系统支持的情况下,其电商APP千人一面,所有运营决策都基于经验决策,影响用户体验,老客户复购率低。
⊙解决方案:奇点云帮助客户构建了统一的数据中台,规范数据采集,打通日志、交易、售后等数据,基于Hive计算引擎帮助客户快速的搭建了数仓模型,每天稳定支撑了1000多个任务量的离线调度。离线加实时计算会员、商品、店铺对象的行为和属性特征,在购物主链路四个环节(曝光-点击-加购-购买)做到千人千面推荐引擎。
⊙实施效果:最终提升新客户50%的转化率与老客户80%的复购率。同时帮助客户运营人员构建业务分析BI系统及一系列运营报表,支撑运营日常数据工作效率提升,快速洞察业务。
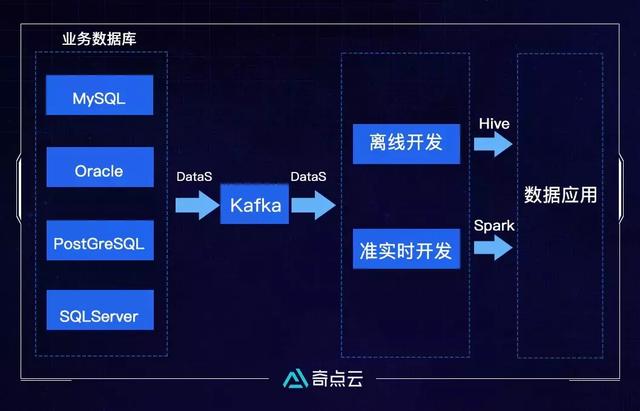
内存计算
由于Hive计算框架是基于磁盘的,因此势必会涉及到频繁的读写磁盘,导致Hive计算框架的计算速度很慢,不适用于实时性要求相对高一点的场景。如今内存容量的增加和成本的降低,促进了基于内存的计算框架的出现,让离线计算在性能上有了极大的提升。
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的场合。需要反复操作的次数越多,需要读取的数据量越大,性能提升就越大;同时也非常的适合数据量不是特别大,但是要求实时统计分析的场景。
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的内容,它表示了已被分区、不可变的、能够被并行操作的数据集,不同的数据集格式对应不同的RDD实现。RDD必须是可以序列化的。RDD可以缓存到内存中,每次对RDD数据集的操作结果都可以存放到内存中,下一个操作可以直接从内存中获取数据,省略了大量的磁盘I/O操作,大大的提高了离线计算的速度。
DataSimba数据中台采取了Hive和Spark互补的双批处理引擎,针对不同的应用场景采取不同的引擎。例如我们在项目上采用了Hive去搭建数仓模型,用Spark去做一些准实时场景的离线开发。
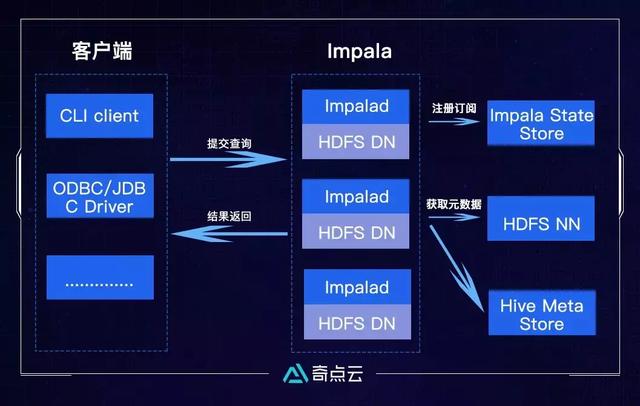
即席查询
在数据仓库领域有一个概念叫Adhoc Query,中文也叫“即席查询”。即席查询是指用户在使用系统时,根据自己当时的需求定义的查询,一般的应用场景为实时数据分析、在线查询等。因为是查询应用,所以通常具有几个特点:延时低、查询条件复杂、查询范围大、返回结果小、并发要求高、需要SQL化。
传统上,常常使用关系型数据库来承担Adhoc Query的职责,但是随着数据量的日益变大,数据库已经无法承受这样的压力,基于内存模型的分布式查询引擎成为了必然的选择。
DataSimba采用了Impala作为即席查询引擎,它提供SQL语义,能查询存储在Hdfs中的PB级大数据,并且计算的时候不需要把中间结果写入磁盘,省掉了大量的I/O开销,完全抛弃了批处理这个不太适合做SQL查询的范式,借鉴了MPP并行数据库的思想,从而省掉不必要的shuffle、sort等开销,大大的提高了查询速度。
多维度分析
在数据仓库里面有两种联机查询:联机事务查询OLTP和联机分析查询OLAP。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,需要对各种维度和度量进行上卷、下钻、切片和切块分析,侧重决策支持,并且提供直观易懂的查询结果。随着目前数据规模的急剧膨胀,从传统的单表千万级到现在的单表百亿、万亿级,维度也从传统的几十维到现在的一些互联网企业可能存在的万维,而且因为交互对象是人,如此大的数据量查询响应延迟要求仍为秒级,OLTP正在逐步的被OALP所替换。
DataSimba底层使用了Druid作为OLAP查询引擎。Druid主要运用了四大关键技术来解决大规模数据量的实时查询:预聚合、列式存储、字段编码、位图索引。首先通过数据的预聚合,可以减少大量不必要数据的存储以及避免查询时很多不必要的计算;并且因为OLAP的分析场景大多只关心某个列或者某几个列的指标计算,列式存储可以很好的满足这个场景;最后在列式存储的基础之上,再加上字段编码,能够有效的提升数据的压缩率,然后位图索引让很多查询最终直接转化成计算机层面的位计算,提升查询效率。
某零售客户解决方案如下
⊙数据量:保存近几年的数据
⊙数据接入方式:当天数据Kafka实时数据接入,隔天离线数据覆盖昨天数据
⊙查询方式:实时查询
⊙ 业务实现:TopN实现销售额曲线展示,GroupBy分组客流分布,TimeSerise做天汇总
目前市场上开源的计算引擎很多,如何选择适合业务场景的计算引擎,是一个比较令人头疼的问题。DataSimba后续会在统一引擎方面投入一定的资源去做研究,屏蔽计算引擎底层、降低用户使用门槛,无需再去学习各引擎使用方法和优缺点,无需手动选择执行引擎、通过SQL画像智能选取合适的计算引擎、收集SQL执行数据,通过决策树,Logistic回归,SVM等分类算法实现引擎的智能路由。
以上是关于奇点云数据中台技术汇| DataSimba系列之计算引擎篇的主要内容,如果未能解决你的问题,请参考以下文章