window10搭建pyspark(超级详细)
Posted yfb918
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了window10搭建pyspark(超级详细)相关的知识,希望对你有一定的参考价值。
一、组件版本说明
Java JDK:1.8.0_144
spark-2.4.3-bin-hadoop2.7
hadoop-2.7.7
scala-2.12.8
hadooponwindows-master
Python3.7
注意事项:
Spark运行在Java 8 +,Python 2.7 + / 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.3使用Scala 2.12。您需要使用兼容的Scala版本(2.12.x)
1、JDK安装
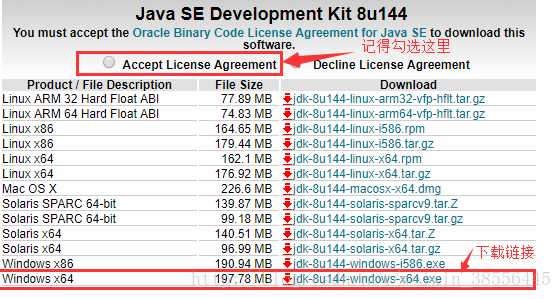
下载安装后配置环境变量:
配置环境变量的方法为电脑[右键]——>属性——>环境变量,编辑环境变量方法见下图
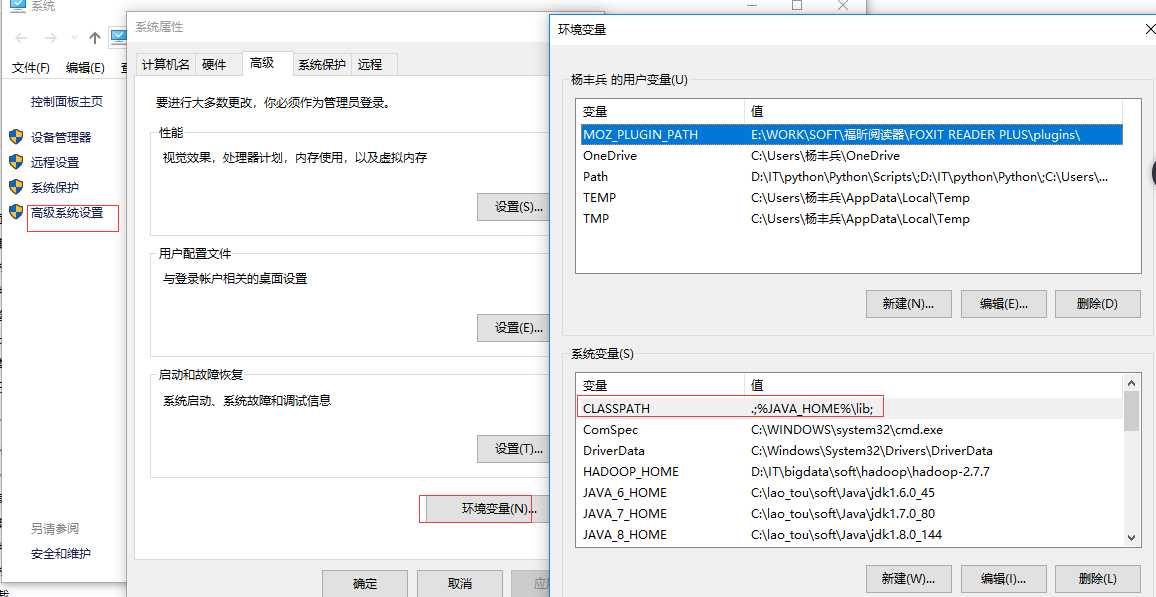
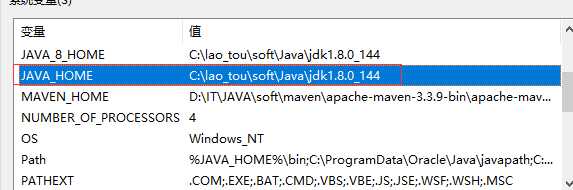
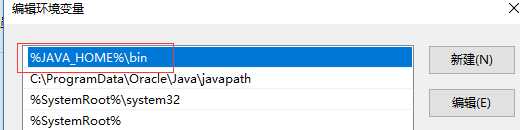
配置完成后:开启cmd窗口
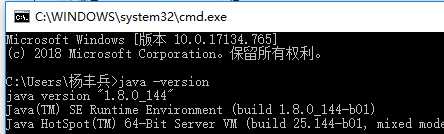
2、配置Scala
下载地址:
https://www.scala-lang.org/download/2.12.8.html
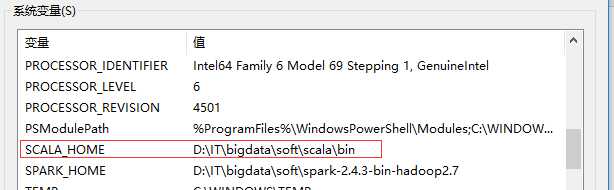
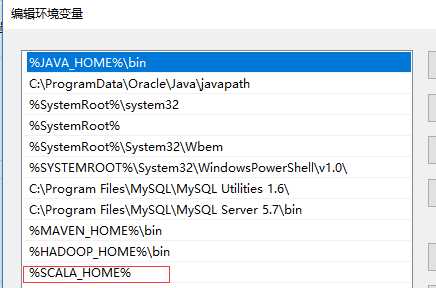
安装完成后,配置环境变量

3、安装Spark
下载地址:
http://spark.apache.org/downloads.html


解压后配置环境变量:
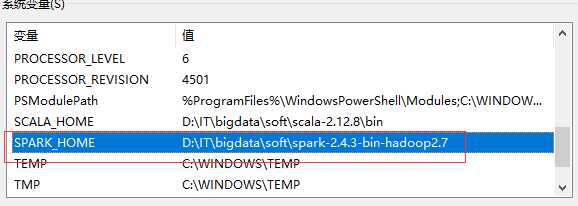
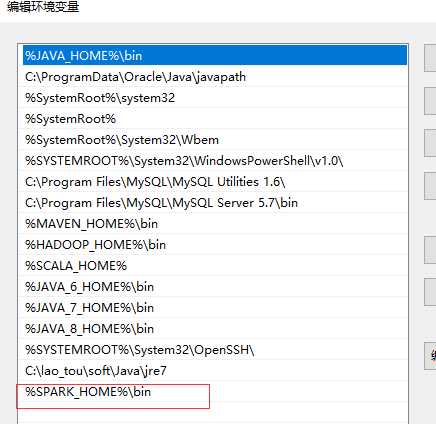
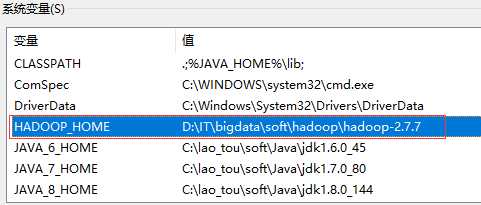
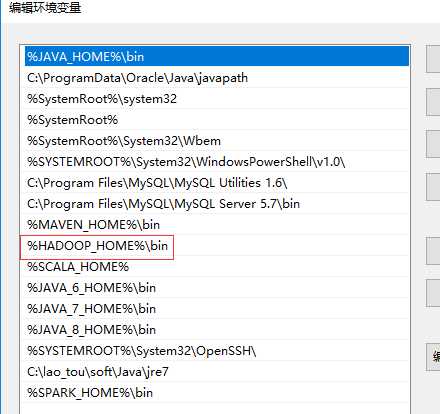
4、安装hadoop
下载地址:
http://hadoop.apache.org/releases.html
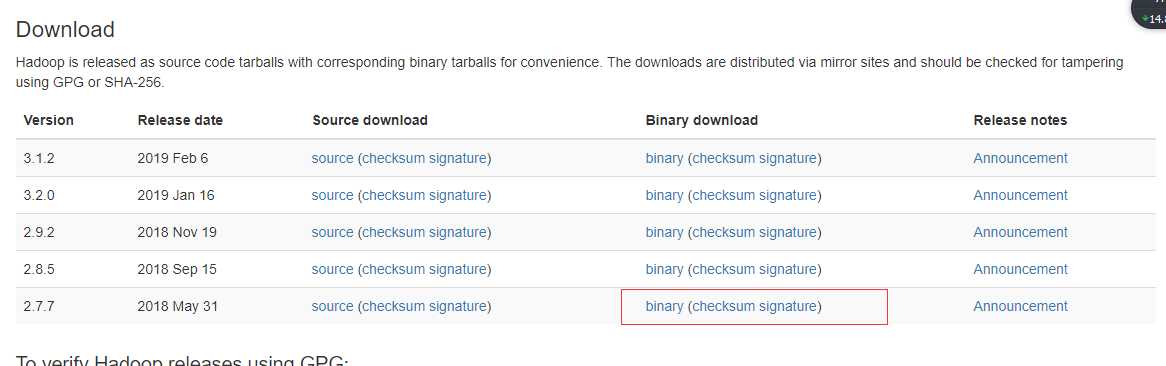
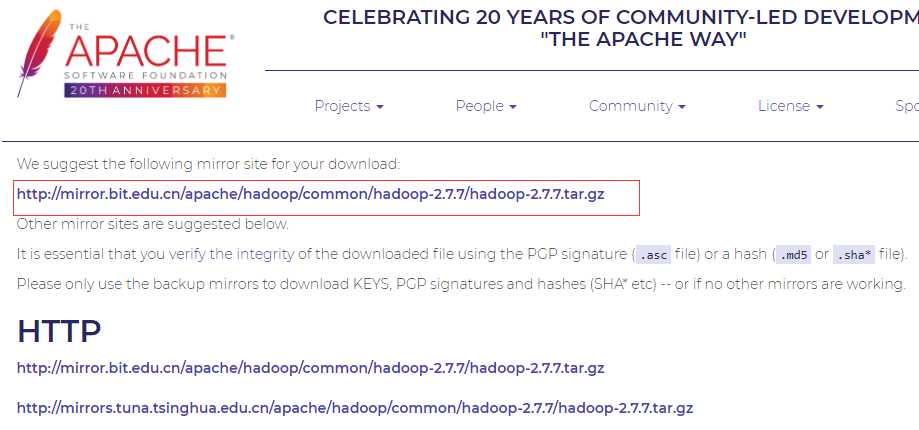
解压后配置环境变量:
5、安装Python3.7
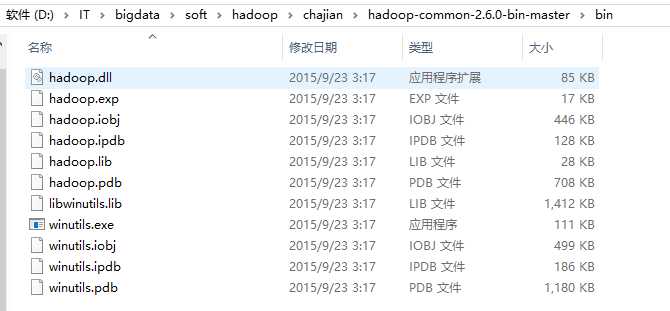
6、把hadooponwindows-master的bin覆盖hadoop-2.7.7的bin
7、处理Python相关
1,将spark所在目录下(比如我的D:\\IT\\bigdata\\soft\\spark-2.4.3-bin-hadoop2.7\\python)的pyspark文件夹拷贝到python文件夹下(我的是D:\\IT\\python\\Python\\Lib\\site-packages)
2,安装py4j库
一般的在cmd命令行下 pip install py4j 就可以。若是没有将pip路径添加到path中,就将路径切换到python的Scripts中,然后再 pip install py4j 来安装库。
3 修改权限
将winutils.exe文件放到Hadoop的bin目录下(我的是E:\\spark\\spark-2.1.0-bin-hadoop2.7\\bin),然后以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\\tmp\\Hive
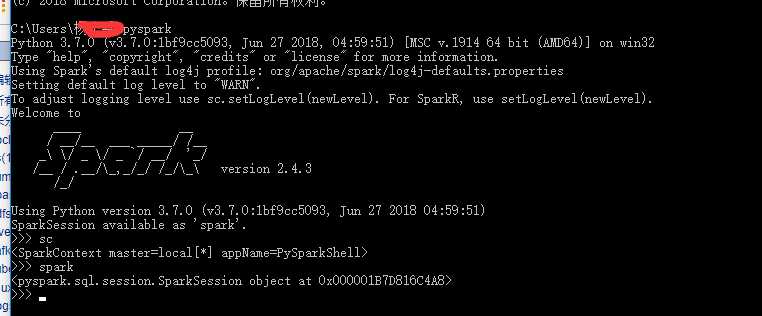
8、启动
9、使用Pycharm新建一个wordcount例程
from pyspark import SparkConf, SparkContext # 创建SparkConf和SparkContext conf = SparkConf().setMaster("local").setAppName("lichao-wordcount") sc = SparkContext(conf=conf) # 输入的数据 data = ["hello", "world", "hello", "word", "count", "count", "hello"] # 将Collection的data转化为spark中的rdd并进行操作 rdd = sc.parallelize(data) resultRdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b) # rdd转为collecton并打印 resultColl = resultRdd.collect() for line in resultColl: print(line)
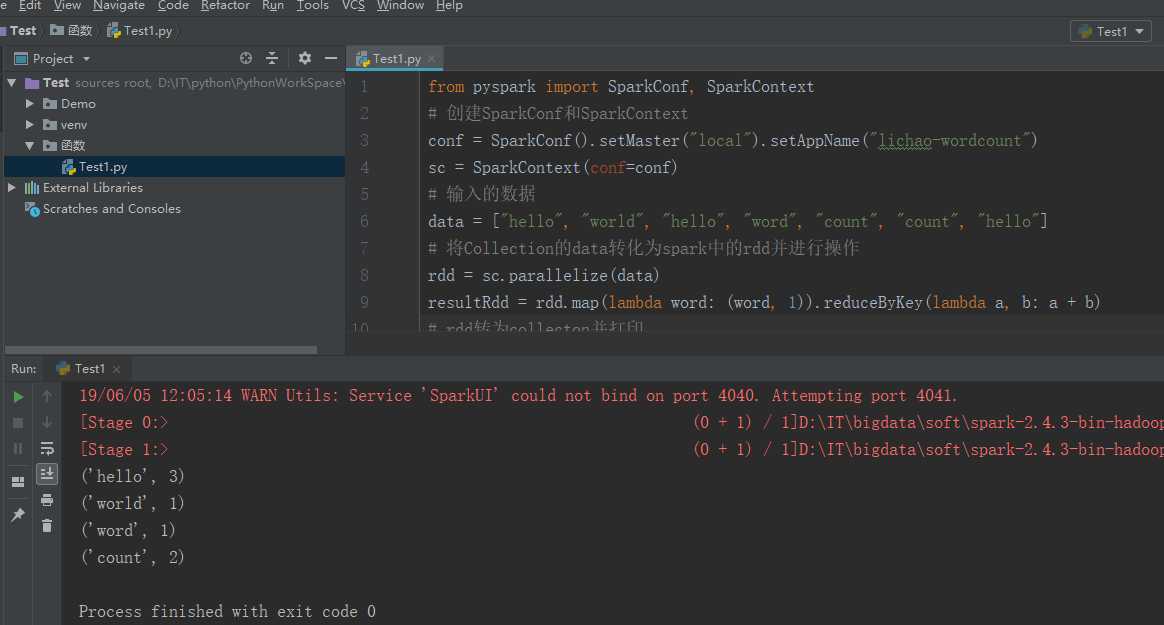
搭建完成啦!
以上是关于window10搭建pyspark(超级详细)的主要内容,如果未能解决你的问题,请参考以下文章