[论文理解] CornerNet: Detecting Objects as Paired Keypoints
Posted aoru45
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文理解] CornerNet: Detecting Objects as Paired Keypoints相关的知识,希望对你有一定的参考价值。
[论文理解] CornerNet: Detecting Objects as Paired Keypoints
简介
首先这是一篇anchor free的文章,看了之后觉得方法挺好的,预测左上角和右下角,这样不需要去管anchor了,理论上也就w*h个点,这总比好几万甚至好几十万的anchor容易吧。文章灵感来源于Newell et al. (2017) on Associative Embedding in the context of multi-person pose estimation,利用embedding后的角点的距离区分左上角和右下角的角点是否属于一个类别,同时,文章提出了Corner Pooling来确保网络得到足够的信息,这比一般的临近位置polling更加有效(这让我学会了如何在特定任务时使用特定方法)。
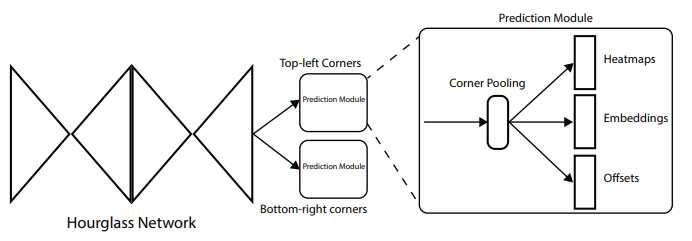
网络结构
网络大致结构如图所示,网络的输出由三个部分组成,分别是heatmap、embedding vectors和offsets:
网络的baseline是Hourglass Network,同时训练两个hourglass 网络,一个用来输出corner,一个用来输出右下角corner,然后再训练一个embedding网络,给输出的corner编码成向量通过编码的向量间的距离将左上角corner与右下角corner匹配组成一个box。而通过offsets可以弥补下采样带来的位置损失,并且使gt和预测更加接近。
训练前-Ground Truth分配
文章用的网络的输出由heatmap、embedding vectors和offsets三部分组成,后两者后面会详细说的。对于heatmap而言,输出的heatmap是shape为(batch_size,c,h,w),其中c为类别数,本文并没有设置背景类别,h,w分别为feature map的宽和高。
文章对gt的分配就是看在gt点的一定半径范围内的点认为是positive,半径之外的点认为是negative,而positive的点的值并不是全分配1,而是按照二维高斯分布分配值,这样做的好处就是保证在gt附近的点的预测值有一定权值,因为其也可能预测到完全框住gt的框,但是显然更靠近gt的点的权值应该被分配的大一些。看官方给的图:

这里绿色的是预测的,但是绿色框的corner并没有和gt重合,但是其却也可以包含目标,所以我们对这种点也应该分配其为positive,这样应该就理解了。
类别置信度的loss为facal loss的改进版,因为总还是会遇到类别不平衡的问题,而focal loss就正好很大程度上能解决这个问题,其loss的形式为:
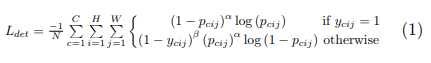
这里C为类别数,H和W分别为feature map的宽高。由于本文的gt的score不一定是1,因为我们上面的高斯分布去分配score使得gt可能小于1,所以作者的改动就在不是1的时候,也就是下面的情况,这个设计使得与gt的临近点的loss惩罚比较小,由此解决hard positive exmaple的问题,α和β都是超参,额外设置的,具体看官方的代码。
offset学习
因为feature map比原始图像肯定是小的,所以在由feature map映射到原图像位置的时候就存在一定偏移,比如原始图像的位置为(220,220),下采样的比率为3,则对应的feature map的位置就是(73,73),而要映射回去的时候却出现了问题,因为73*3 = 219,所以是有偏移的,这个偏移可以通过网络学习,这样不仅可以消去偏移,而且可以让临近点尽可能忘gt靠拢。所以学习的时候就学习这个差值:
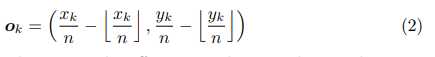
文章采用的offset的loss为smotth L1 Loss,所以loss的计算如图:
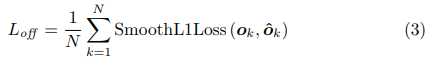
embedding学习
embedding的目的是为了group corners,对feature map embedding的目的是为了让embedding后的左上角和右下角的向量距离小,而和不同类别的corner的距离大,所以训练的loss就是下面这样子的:

ek这里是第k个box embedding之后左上角和右下角的均值,所以上面的loss可以确保相同同一个box的左上角和右下角的距离足够近,而下面的loss可以保证其和其他不同类别的vector的距离足够远。
Corner Pooling
由于一般的pooling只会利用周边的信息,而本文的任务需要利用的信息是水平的或者竖直的,对于top left corner而言,其需要利用的应该是其水平右边所有的信息和竖直下边所有的信息,比如下面这个例子:

为了确定好左上角这个corner,需要利用这个图里的帽子区域的信息和左边手这里的信息,而corner pooling就是来解决这个问题的,其具体操作如下:
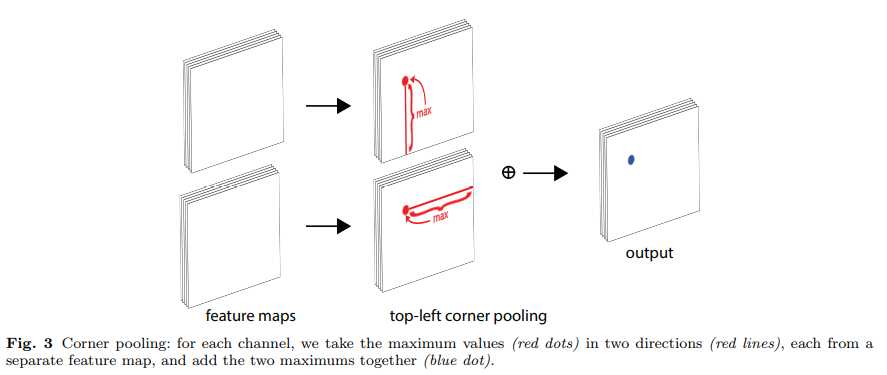
对于top left corner,就是取其从改点到width的所有值中的最大值,然后取改点到height的最大值,将两者值进行相加,就得到了pooling后的值。
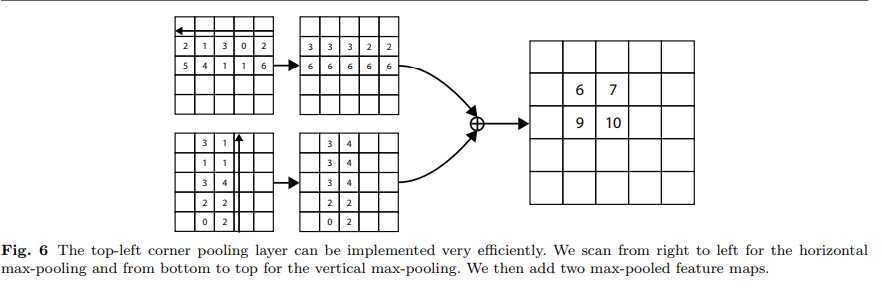
官方给出的例子如下:
代码实现参加github:
https://github.com/princeton-vl/CornerNet-Lite
论文地址:
https://arxiv.org/pdf/1808.01244.pdf
以上是关于[论文理解] CornerNet: Detecting Objects as Paired Keypoints的主要内容,如果未能解决你的问题,请参考以下文章
CentripetalNet:更合理的角点匹配,多方面改进CornerNet | CVPR 2020
论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
DenseBox: Unifying Landmark Localization with End to End Object Detection